Kafka producer retries
Kafka producer retries recover from transient failures. Configure retries, retry.backoff.ms and delivery.timeout.ms, and avoid ordering risks with idempotency.
By Stéphane Derosiaux · July 23, 2026
Learn how to configure producer retries for reliable message delivery
Kafka producers can automatically retry failed requests to improve reliability and handle transient failures in distributed systems.
What you'll learn:
- How producer retries work and when they're triggered
- The difference between retriable and non-retriable errors
- How to configure retry behavior for idempotent producers
- Best practices for retry timeout and backoff settings
Why retries matter
In distributed systems, temporary failures are common:
- Network connectivity issues
- Broker leadership changes
- Temporary resource constraints
- Replication delays
Without retries, these transient issues would result in lost messages. Retries provide resilience against such failures.
Retry configuration
Basic retry settings
# Number of retry attempts (default varies by Kafka version)
retries=2147483647
# Time to wait between retries (default: 100ms)
retry.backoff.ms=100
# Maximum time to wait for acknowledgment (default: 30s)
request.timeout.ms=30000
# Maximum time to deliver a message including retries (default: 2 minutes)
delivery.timeout.ms=120000Kafka version differences
Kafka < 3.0:
retries=0(no retries by default)- Must explicitly enable retries
Kafka >= 3.0:
retries=Integer.MAX_VALUE(unlimited retries)- Retries enabled by default with idempotent producers
Types of errors
Retriable errors
These errors can potentially be resolved by retrying:
- TimeoutException: Request timed out
- NotEnoughReplicasException: Not enough in-sync replicas
- NotEnoughReplicasAfterAppendException: Replication issues
- RetriableException: Generic retriable error
- LeaderNotAvailableException: Leader election in progress
- NetworkException: Network connectivity issues
Non-retriable errors
These errors indicate permanent failures that won't be resolved by retrying:
- RecordTooLargeException: Message exceeds size limits
- SerializationException: Message serialization failed
- OffsetMetadataTooLarge: Offset metadata too large
- InvalidTopicException: Topic doesn't exist or is invalid
- UnknownTopicOrPartitionException: Topic or partition invalid
- AuthorizationException: Authentication/authorization failure
Error handling decision tree
This decision tree helps you understand how to handle different types of producer errors:
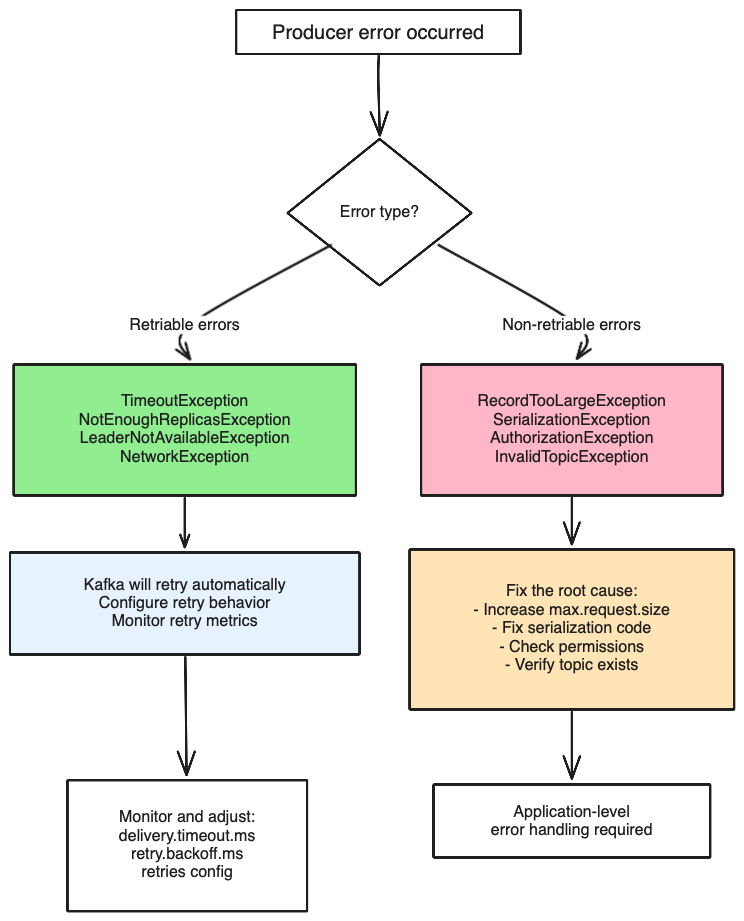
Retry decision flowchart
This flowchart shows how the producer decides whether to retry a failed request:
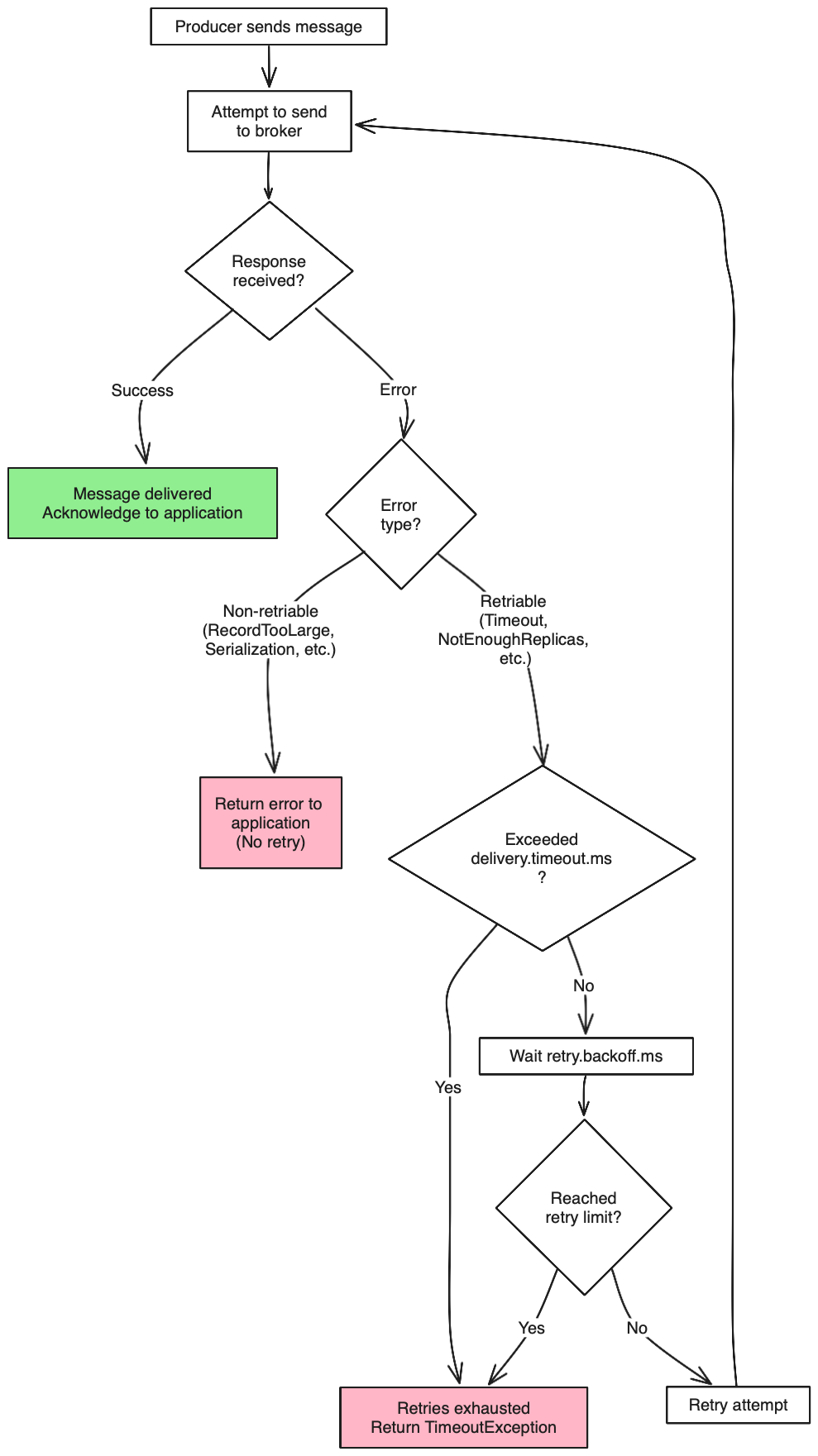
Idempotent producers (Kafka 2.4+): With
enable.idempotence=trueandacks=all, you get unlimited retries by default without risk of duplicates, making retry configuration much simpler.
Retry backoff strategies
Fixed backoff (default)
Waits a fixed amount of time between retries:
retry.backoff.ms=100 # Always wait 100ms between retriesPattern: Wait → Retry → Wait → Retry → Wait → Retry
Exponential backoff
Not natively supported by Kafka producer, but can be implemented at the application level:
Attempt 1: Wait 100ms
Attempt 2: Wait 200ms
Attempt 3: Wait 400ms
Attempt 4: Wait 800msImpact on message ordering
With retries enabled
Retries can affect message ordering within a partition:
Message A sent → Fails → Retry scheduled
Message B sent → Succeeds immediately
Message A retry → Succeeds
Result: Message B appears before Message A in partitionPreserve order
To maintain strict ordering, configure:
# Limit in-flight requests to preserve order
max.in.flight.requests.per.connection=1
# Or use idempotent producer (recommended)
enable.idempotence=true
max.in.flight.requests.per.connection=5 # Up to 5 with idempotencyDelivery timeout vs request timeout
Request timeout
Time to wait for a single request attempt:
request.timeout.ms=30000 # 30 seconds per attemptDelivery timeout
Total time limit for delivering a message (including all retries):
delivery.timeout.ms=120000 # 2 minutes totalRelationship:
delivery.timeout.ms >= request.timeout.ms + (retries × retry.backoff.ms)Configuration examples
High reliability (recommended)
# Unlimited retries with delivery timeout
retries=2147483647
delivery.timeout.ms=300000 # 5 minutes total
request.timeout.ms=30000 # 30 seconds per attempt
retry.backoff.ms=100 # 100ms between retries
enable.idempotence=true # Preserve ordering and avoid duplicatesFast failure
# Limited retries for quick feedback
retries=3
delivery.timeout.ms=10000 # 10 seconds total
request.timeout.ms=5000 # 5 seconds per attempt
retry.backoff.ms=100 # 100ms between retriesNo retries (not recommended for production)
retries=0
request.timeout.ms=30000Monitor retry behavior
Key metrics to track
- retry-rate: Rate of retry attempts
- retry-total: Total number of retries
- error-rate: Rate of failed requests (after all retries)
- request-latency: Time taken for requests (including retries)
JMX metrics
kafka.producer:type=producer-metrics,client-id=<client-id>
- retry-rate
- retry-total
- request-rate
- request-latency-avgError handling strategies
Synchronous error handling
Properties props = new Properties();
props.put("retries", 5);
props.put("retry.backoff.ms", 100);
Producer<String, String> producer = new KafkaProducer<>(props);
try {
ProducerRecord<String, String> record = new ProducerRecord<>("topic", "key", "value");
RecordMetadata metadata = producer.send(record).get();
System.out.println("Message sent to " + metadata.topic() + ":" + metadata.partition());
} catch (Exception e) {
System.err.println("Failed after all retries: " + e.getMessage());
}Asynchronous error handling
ProducerRecord<String, String> record = new ProducerRecord<>("topic", "key", "value");
producer.send(record, (metadata, exception) -> {
if (exception != null) {
System.err.println("Failed after all retries: " + exception.getMessage());
} else {
System.out.println("Message sent successfully");
}
});Best practices
Production recommendations
- Enable unlimited retries: Set
retries=Integer.MAX_VALUE - Use delivery timeout: Set
delivery.timeout.msto control total time - Enable idempotency: Prevents duplicates during retries
- Monitor retry metrics: Track retry rates and error patterns
- Handle non-retriable errors: Implement proper error handling for permanent failures
Configuration checklist
- ✅
retries=Integer.MAX_VALUE(unlimited retries) - ✅
delivery.timeout.ms=120000(reasonable total timeout) - ✅
request.timeout.ms=30000(reasonable per-request timeout) - ✅
retry.backoff.ms=100(reasonable delay between retries) - ✅
enable.idempotence=true(prevent duplicates)
Common mistakes to avoid
- Setting
retries=0in production - Not handling non-retriable errors
- Setting delivery timeout too low
- Ignoring retry metrics and error rates
Starting with Kafka 3.0, producers have sensible retry defaults: unlimited retries with idempotency enabled, a 2-minute delivery timeout, and proper error handling for most use cases. Note that retries can affect message ordering within partitions—use enable.idempotence=true or max.in.flight.requests.per.connection=1 if strict ordering is required.
See it in practice with Conduktor
Conduktor Console displays producer retry metrics and error rates in real-time. Monitor retry attempts, successful retries, and failed messages to validate your retry configuration and identify patterns in transient versus permanent failures.
Next steps
- Enable idempotent producers to avoid duplicates on retry
- Understand acknowledgment settings for delivery guarantees
- Optimize producer batching for throughput