Kafka Cost Optimization
Find waste. Attribute spend. Run leaner.
Kafka usage grows by accretion: more topics, clusters, integrations, and the operational overhead behind them. Conduktor gives platform teams the visibility, attribution, and architectural levers to find what's recoverable, run more efficiently, and keep the gains from eroding.
Where Kafka Costs Actually Hide
The Kafka bill is rarely one line item. It surfaces across four layers, and waste in one pulls the others up with it. Operational overhead is the layer most teams underestimate. Most platform teams find 25 to 40 percent recoverable spend across these layers without a replatform or a renegotiation.
Infrastructure
Brokers, partitions, storage, replication. The biggest layer and the easiest to act on. Six patterns drive most of the waste, from partition overprovisioning to topic proliferation.
Ecosystem tooling
Streams, ksqlDB, Flink, Connect. Sits on top of infrastructure and inherits its inefficiencies. Filter-only jobs alone can dominate stream-processing usage.
Vendor and licensing
Support contracts priced as a percentage of platform spend. Tier upgrades and add-ons scale with cluster footprint. Shrink the infrastructure, these shrink with it.
Operational overhead
The cost that never appears on the bill, and the largest one most teams miss. Platform-team time on manual provisioning, firefighting, and cleanup coordination that better tooling would absorb.
From patterns to solutions
Most Kafka estates carry the same six waste patterns. Conduktor helps in two ways: in identifying waste and addressing inefficiencies.
| Pattern | What it looks like | How Conduktor helps |
|---|---|---|
| Partition overprovisioning | Topics with 30+ partitions for use cases that need 3, brokers approaching the per-broker partition-replica ceiling | Insights finds the over-partitioned topics. Cost Guardrails bound new ones at creation. |
| Retention misalignment | Default retention on every topic regardless of consumer lag, retention longer than any consumer reads back | Insights flags retention overrun. Cost Guardrails cap retention windows on new topics. |
| Cluster sprawl | A cluster per project, environment, or business unit, each carrying its own broker fixed cost | Capacity Pooling consolidates dedicated isolation clusters onto shared infrastructure. |
| Topic proliferation and duplication | Orphan topics with no traffic, near-duplicates, derived topics from filter-only stream processing | Insights surfaces orphans and duplicates. Topic Views replace filter-only derivations. Chargeback gets app teams retiring what they don't need. |
| Inefficient client patterns | Producers without compression, idempotence misconfigured, consumers without partition awareness | Cost Guardrails enforce compression, idempotence, and ack policies on every producer. |
| Static capacity per resource | Every topic gets dedicated partitions and replicas regardless of actual throughput | Capacity Pooling replaces dedicated partitions with shared backing topics via concentration. |
Identify Waste
You can't fix what you can't see and so central cleanup never sticks. Insights finds the waste while Chargeback puts the bill in terms the business can act on.
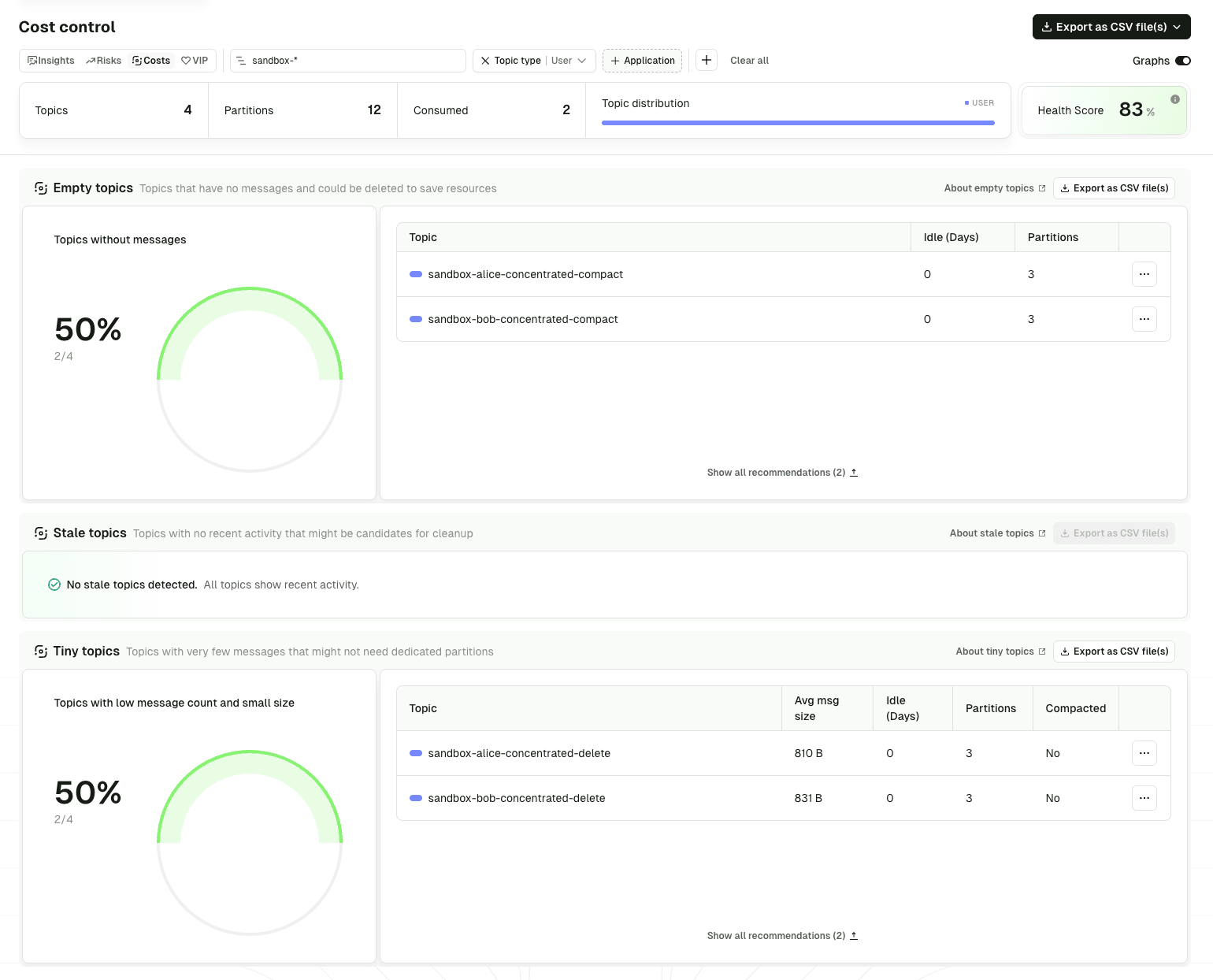
Find the waste hiding in your estate
Insights surfaces the topics you are paying for that you should not be: orphans, oversized, over-retained. The Cost Control view ranks them so cleanup runs by impact, not by cluster.
- Cost Control ranks expensive topics by storage, partitions, and throughput, with the underlying pattern (over-partitioned, retention overrun, orphan) flagged on each
- Filter by application, topic prefix, or cluster so cleanup scopes to the topics that matter
- RBAC-aware so app owners see the topics they own and act on them without escalating to a platform admin
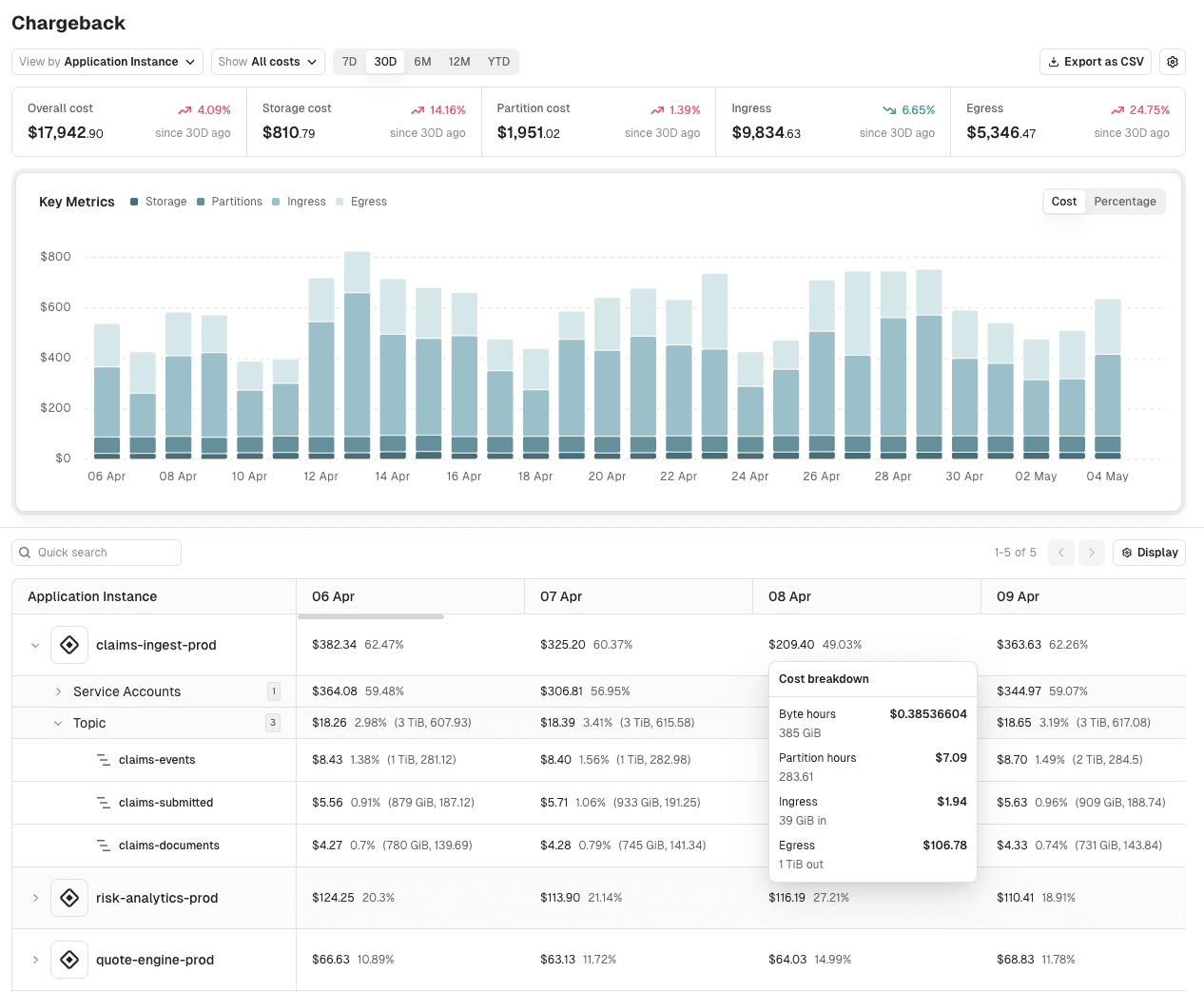
Make app teams own their costs
Cleanup pushed centrally never sticks. Chargeback turns consumption into an accounting view of spend, so teams generating the cost see their own bill before anyone has to ask.
- Spend rolls up by application, service account, or any label (team, department, business unit) so reports match the org chart, not the cluster topology
- Configurable unit costs for storage, partitions, and ingress/egress tied to your actual contract terms
- Confluent Cloud direct: pulls ingress and egress from the Confluent Metrics API, no Conduktor Gateway required
Address Inefficiency
Visibility surfaces the waste, but cutting it takes a different mix of levers: capacity pooling, topic views in place of filter-only stream processing, and creation-time guardrails on every new resource.
Pool capacity instead of allocating it
Most cost waste is structural: each team gets its own cluster, each topic gets its own dedicated partitions. Virtual clusters and topic concentration share the underlying infrastructure without breaking isolation.
- Virtual clusters consolidate dedicated isolation clusters onto shared physical infrastructure, eliminating per-team broker overhead
- Topic concentration multiplexes low-volume topics onto a single physical backing topic, dropping partition counts on sparse topics by 50 to 90 percent
- Hard isolation between environments, brands, or business units with no new brokers required
# Two isolation boundaries on one physical cluster.
# No new brokers, no new licenses, no naming conventions.
apiVersion: gateway/v2
kind: VirtualCluster
metadata:
name: payments-team
spec:
type: Standard
aclEnabled: true
superUsers:
- payments-admin
apiVersion: gateway/v2
kind: VirtualCluster
metadata:
name: orders-team
spec:
type: Standard
aclEnabled: true
superUsers:
- orders-admin# Sparse regional topics: 24 logical partitions each,
# backed by 6 physical partitions on a shared topic.
apiVersion: gateway/v2
kind: ConcentratedTopic
metadata:
name: customer-events-eu
vCluster: payments-team
spec:
advertisedPartitions: 24
backingTopic: _concentrated_customer_events
apiVersion: gateway/v2
kind: ConcentratedTopic
metadata:
name: customer-events-us
vCluster: payments-team
spec:
advertisedPartitions: 24
backingTopic: _concentrated_customer_events
# Two topics × 24 partitions = 48 advertised.
# Physically backed by 6 partitions: 87.5% reduction.Replace filter-only stream processing
Most stream-processing jobs do one thing: read a topic, drop rows a consumer does not need, and write the rest somewhere new. The team pays three times: engine, dev time, derived infrastructure. Topic Views handle this at the proxy.
- SQL-based topic views serve a filtered or projected subset at the proxy layer, with no new physical topic or partitions to pay for
- Caching for high-frequency repetitive reads, reducing broker fetch load on the source topic
# Replaces a Flink job that filtered "customers" to EU adults.
# No derived topic, no new partitions, no Flink instance.
apiVersion: gateway/v2
kind: Interceptor
metadata:
name: customers-eu-adults
spec:
pluginClass: io.conduktor.gateway.interceptor.VirtualSqlTopicPlugin
priority: 100
config:
virtualTopic: customers-eu-adults
statement: |
SELECT firstName, lastName, email, country
FROM customers
WHERE age >= 18 AND country IN ('FR', 'DE', 'ES')
schemaRegistryConfig:
host: http://schema-registry:8081# High-frequency read patterns served from cache,
# reducing broker fetch load and outbound bandwidth.
apiVersion: gateway/v2
kind: Interceptor
metadata:
name: cache-reference-data
spec:
pluginClass: io.conduktor.gateway.interceptor.CacheInterceptorPlugin
priority: 100
config:
topic: "reference.*"
cacheConfig:
type: IN_MEMORY
inMemConfig:
cacheSize: 1000
expireTimeMs: 60000Stop waste at creation time
The cheapest cleanup is the one you never have to run. Bound partitions, retention, and replication at topic creation, require an owner on every new resource, and future loads inherit the discipline.
- Partition and retention bounds enforced at topic creation, with override-to-fixed or block actions
- Replication factor enforcement to prevent quietly-doubled replication on non-critical topics
- Producer policies for compression and idempotence to standardize client efficiency
- Federated ownership required on every new resource so orphan topics are blocked by construction
# New topics are bounded on partitions, retention,
# and replication factor at creation time.
apiVersion: gateway/v2
kind: Interceptor
metadata:
name: topic-cost-policy
spec:
pluginClass: io.conduktor.gateway.interceptor.safeguard.CreateTopicPolicyPlugin
priority: 100
config:
numPartition:
min: 3
max: 12
action: OVERRIDE
overrideValue: 6
replicationFactor:
min: 3
max: 3
action: BLOCK
retentionMs:
min: 86400000
max: 604800000
action: OVERRIDE
overrideValue: 259200000# Producers without compression or idempotence are blocked.
# Consistent client efficiency across every team.
apiVersion: gateway/v2
kind: Interceptor
metadata:
name: producer-efficiency-policy
spec:
pluginClass: io.conduktor.gateway.interceptor.safeguard.ProducerPolicyPlugin
priority: 100
config:
compressionType:
allowed: ["zstd", "lz4", "snappy"]
action: BLOCK
acks:
required: "all"
action: BLOCK
enableIdempotence:
required: true
action: BLOCKThree approaches to sequencing the work
The capabilities above are levers. How they get applied depends on which approach the team is taking. Most platform teams run all three in parallel: defaults catch new loads, optimization works through the existing estate, and architectural changes land over a longer horizon.
Set policies so new topics, clusters, and clients do not inherit waste. Partition defaults, retention policies, replication enforcement, and ownership requirements at creation time. Low coordination, fast to implement. Slows future cost growth without producing immediate savings.
Hygiene and right-sizing on what is already running: tuning retention, retiring orphans, right-sizing partition counts, consolidating duplicate topics. The gating factor is coordinating with producers and consumers, not the technical work itself. Typically moves the infrastructure bill by 10 to 20 percent in weeks to months, with reductions of 50 percent or more in estates with significant accumulated waste.
Reshape data flows: pooled capacity at the cluster and topic layer, replacing filter-only stream processing with topic views, consolidating per-team clusters. The most variable approach in timeline and outcome, with the largest impact in big estates carrying years of accumulated structural decisions.
What to expect
Typical ranges from the estates we have analyzed. Your number depends on where you are starting from and which patterns dominate.
25 to 40 percent recoverable
The typical share of the Kafka infrastructure bill that's recoverable without a replatform. Configuration tuning and topic retirement do most of the work; consolidation and architectural changes close the rest.
10 to 20 percent typical infra reduction
What optimization on existing workloads usually moves the bill by, in weeks to months. Up to 50 percent in estates with significant accumulated orphans and over-partitioning.
50 to 90 percent partition reduction
Topic concentration on sparse low-throughput topics. Regional topics that would need hundreds of partitions back onto a fraction of the physical footprint.
~90 percent less cleanup coordination
Cleanup outreach drops from roughly 1.5 hours per project to under 15 minutes. Teams arrive already aware of their own consumption from the chargeback dashboard.
Stale topic rate from ~10% to ~3%
What happens when teams see their own bill. Steady-state staleness drops 60 to 80 percent across the estates we measure.
Support contract proportionally smaller
Support contracts on most hosted Kafka platforms are billed as a percentage of total platform spend. Cleaning up infrastructure shrinks that line item automatically, no renegotiation needed.
How much can I actually save?
A meaningful share of the typical Kafka infrastructure bill is recoverable through configuration changes, retirement, consolidation, and architectural levers. The 25 to 40 percent range is what we see across estates we analyze closely. Optimization on existing workloads typically moves the bill 10 to 20 percent in weeks to months, with reductions of 50 percent or more in estates carrying significant accumulated waste. Architectural changes like pooled capacity yield more variable returns with the largest impact in big estates.
Where do the savings tend to come from?
A small number of patterns account for most recoverable cost: partition overprovisioning, retention not matched to consumer needs, cluster sprawl, topic proliferation and duplication, inefficient client patterns, and static capacity per resource. The field guide covers each in detail. Estates vary in which dominate, but the data usually points to the biggest one or two quickly.
Where should I start?
Visibility first, almost always. Without a per-team breakdown of consumption, every other lever is operating blind. Insights and Chargeback are the typical starting point because they make the patterns and the accountability story concrete before any cleanup or architectural work begins.
What is topic concentration and how does it reduce costs?
Topic concentration multiplexes multiple low-volume logical topics onto a single physical backing topic. Applications still see independent topics with their own names and advertised partition counts, but the underlying storage is shared. Partition counts on sparse topics can drop 50 to 90 percent, directly lowering broker CPU, storage, and replication costs. Best fit is non-production environments and low-throughput production topics.
How does cost attribution work across multiple clusters and providers?
Conduktor connects to every cluster regardless of provider and tracks consumption at the application level. Conduktor Gateway meters bytes in and out per service account, topic, and virtual cluster. Console aggregates this into chargeback dashboards so cost breakdowns surface by team, application, or business label across the entire Kafka estate, not one cluster at a time.
Can I reduce costs without changing platforms?
Yes. Most cost work happens within the existing platform: tuning configurations, retiring waste, consolidating clusters, and pooling capacity through virtual clusters and topic concentration. Replatforming is a smaller set of cases and the longest commitment, and the first two categories of work usually close most of the gap. When a Kafka migration is planned, cost cleanup typically runs alongside it.
How do I keep the savings from eroding?
Defaults and policies are necessary but not sufficient. Holding the gains involves three things: visibility into what the estate contains and what it costs, clear ownership of every topic and cluster, and a regular cadence of reviewing what is actually being used. Federated ownership and self-service with guardrails are the structural pieces that hold up over years.
Does Conduktor work with managed Kafka (Confluent Cloud, AWS MSK)?
Yes. Console Insights and Chargeback connect to every cluster regardless of provider. Conduktor Gateway features like virtual clusters, topic concentration, and topic views work the same way, since clients connect to the gateway exactly like a broker. Managed-Kafka customers often see proportionally larger savings from concentration and view-based filtering because per-unit infrastructure cost is higher.
Ready to find what is recoverable in your estate?
Book a cost analysis with our field engineering team. We will walk through your estate together, identify the waste patterns that apply, and give a concrete estimate of where the savings sit.