Ivy Preview Feed your agents real-time context. Automate what can't wait.
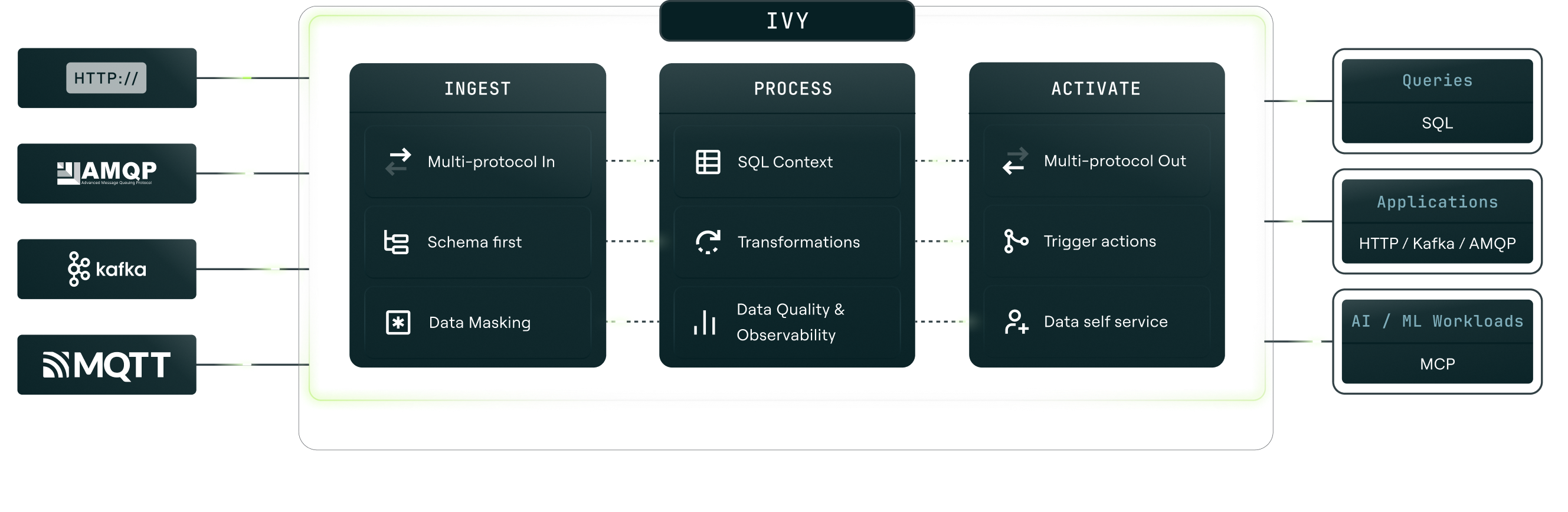
Ivy activates your operational data: correlate your streams into the datasets, context, and triggers your agents, apps, and models act on, all through a guided UX. No SQL, no code, no warehouse. Any protocol, MCP included.
Decisions are moving from a human reading a dashboard to an agent that acts in real time.
Your operational data is captured and governed, but it's sitting idle, scattered across systems that don't talk to each other. Ivy is where you activate it: correlate streams, build the datasets and context each use-case needs, and fire the triggers your agents, apps, and models act on, in any protocol.
Bring every event together
The data you want to activate is scattered. Orders in Kafka, inventory in Postgres, sensor reads over MQTT, a payment webhook from a SaaS, each in its own shape. Correlating them means a connector and a pipeline per source.
Ingest from HTTP, Kafka, MQTT, AMQP, Postgres CDC, and SaaS webhooks into one place. One schema, one set of permissions, no Connect cluster to run.
Correlate and prepare, visually
Moving data is the easy part. The work is joining it, matching an order to its shipment to its payment over a time window, before it goes stale. That usually means a stream-processing job, a query language to learn, and a store to babysit.
Ivy guides you to the right pattern, cross-stream joins, time windows, correlation, in a visual builder. No SQL, no code, so anyone can build it. Stateful and exactly-once, with no RocksDB or Redis to operate.
Stream, context, or trigger
A prepared dataset is only useful if each consumer can act on it their way. An app wants SQL, an agent wants an MCP tool, a model wants a feed, another system wants a push.
Activate the same result as an enriched stream (Kafka, HTTP, MQTT), a queryable context (Postgres-wire SQL, HTTP, MCP), or a trigger (an outbound webhook or a write into another system). One result, every consumer.
Where a real-time call moves the business.
Each combines events from several systems, correlated as they happen. You build it on Ivy, no code.
Supply chain
Reroute shipments and reorder stock as disruptions land, not in the next planning cycle.
Fraud & risk
Score and stop suspicious activity as it happens, with a clear record of what the call was based on.
Real-time payments
Approve, route, and reconcile as the payment clears, where a wrong call is felt immediately.
Personalization
Shape the next offer from what a customer is doing right now, not what they did last week.
Connected products & IoT
Turn a stream of device signals into action at the edge before a problem grows.
Capture · Process · Activate.
The three steps, in one binary. Capture from any protocol, correlate in a visual builder, and activate as a stream, a query, an MCP tool, or a trigger.
kcat -P -b kafka.demo.ivy.conduktor.io:9094 -t mystream \
-X security.protocol=SASL_SSL \
-X sasl.mechanism=SCRAM-SHA-256 \
-X sasl.username=tok_V8WkorRDLT6NYxg3CPpUKQ \
-X sasl.password=ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM \
<<< '{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}'echo '{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}' | kafka-console-producer \
--bootstrap-server kafka.demo.ivy.conduktor.io:9094 \
--topic mystream \
--producer-property security.protocol=SASL_SSL \
--producer-property sasl.mechanism=SCRAM-SHA-256 \
--producer-property sasl.jaas.config='org.apache.kafka.common.security.scram.ScramLoginModule required username="tok_V8WkorRDLT6NYxg3CPpUKQ" password="ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM";'import { Kafka } from "kafkajs";
const kafka = new Kafka({
brokers: ["kafka.demo.ivy.conduktor.io:9094"],
ssl: true,
sasl: { mechanism: "scram-sha-256", username: "tok_V8WkorRDLT6NYxg3CPpUKQ", password: "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM" },
});
const producer = kafka.producer();
await producer.connect();
await producer.send({
topic: "mystream",
messages: [{ value: JSON.stringify({"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}) }],
});from confluent_kafka import Producer
p = Producer({
"bootstrap.servers": "kafka.demo.ivy.conduktor.io:9094",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "tok_V8WkorRDLT6NYxg3CPpUKQ",
"sasl.password": "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
})
p.produce("mystream", '{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}')
p.flush()import "github.com/confluentinc/confluent-kafka-go/v2/kafka"
p, _ := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": "kafka.demo.ivy.conduktor.io:9094",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "tok_V8WkorRDLT6NYxg3CPpUKQ",
"sasl.password": "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
})
topic := "mystream"
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(`{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}`),
}, nil)
p.Flush(5000)import pika, ssl
ctx = ssl.create_default_context()
params = pika.URLParameters("amqps://tok_V8WkorRDLT6NYxg3CPpUKQ:ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM@amqp.demo.ivy.conduktor.io:5671/%2F")
params.ssl_options = pika.SSLOptions(ctx)
conn = pika.BlockingConnection(params)
ch = conn.channel()
ch.basic_publish(
exchange="ivy.mystream",
routing_key="mystream",
body='{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}',
)import amqp from "amqplib";
const conn = await amqp.connect("amqps://tok_V8WkorRDLT6NYxg3CPpUKQ:ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM@amqp.demo.ivy.conduktor.io:5671/");
const ch = await conn.createChannel();
await ch.assertExchange("ivy.mystream", "topic", { durable: true });
ch.publish("ivy.mystream", "mystream",
Buffer.from(JSON.stringify({"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"})));import amqp "github.com/rabbitmq/amqp091-go"
conn, _ := amqp.DialTLS("amqps://tok_V8WkorRDLT6NYxg3CPpUKQ:ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM@amqp.demo.ivy.conduktor.io:5671/", nil)
ch, _ := conn.Channel()
ch.PublishWithContext(ctx, "ivy.mystream", "mystream", false, false,
amqp.Publishing{ContentType: "application/json",
Body: []byte(`{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}`)})curl -X POST https://http.demo.ivy.conduktor.io/topics/mystream \
-H "Authorization: Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM" \
-H "Content-Type: application/json" \
-d '{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}'await fetch("https://http.demo.ivy.conduktor.io/topics/mystream", {
method: "POST",
headers: {
Authorization: "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
"Content-Type": "application/json",
},
// Body shape mirrors the schema you authored in the wizard. Replace literal
// values with your runtime data when you wire this into your app.
body: JSON.stringify({"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}),
});import json, requests
requests.post(
"https://http.demo.ivy.conduktor.io/topics/mystream",
headers={"Authorization": "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM", "Content-Type": "application/json"},
data=json.dumps(json.loads('{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}')),
)package main
import (
"bytes"
"net/http"
)
func main() {
body := []byte(`{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}`)
req, _ := http.NewRequest("POST", "https://http.demo.ivy.conduktor.io/topics/mystream", bytes.NewReader(body))
req.Header.Set("Authorization", "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM")
req.Header.Set("Content-Type", "application/json")
http.DefaultClient.Do(req)
}mosquitto_pub -h mqtt.demo.ivy.conduktor.io -p 8883 \
-u tok_V8WkorRDLT6NYxg3CPpUKQ -P "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM" \
-t "mystream" -q 1 \
-m '{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}'import mqtt from "mqtt";
const c = mqtt.connect("mqtts://mqtt.demo.ivy.conduktor.io:8883", {
username: "tok_V8WkorRDLT6NYxg3CPpUKQ",
password: "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
});
c.on("connect", () => {
c.publish("mystream", JSON.stringify({"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}), { qos: 1 });
});import paho.mqtt.client as mqtt, ssl
c = mqtt.Client()
c.username_pw_set("tok_V8WkorRDLT6NYxg3CPpUKQ", "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM")
c.tls_set(cert_reqs=ssl.CERT_REQUIRED)
c.connect("mqtt.demo.ivy.conduktor.io", 8883, 60)
c.publish("mystream", payload='{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}', qos=1)import mqtt "github.com/eclipse/paho.mqtt.golang"
opts := mqtt.NewClientOptions().
AddBroker("tls://mqtt.demo.ivy.conduktor.io:8883").
SetUsername("tok_V8WkorRDLT6NYxg3CPpUKQ").
SetPassword("ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM")
c := mqtt.NewClient(opts)
c.Connect().Wait()
c.Publish("mystream", 1, false, `{"id":"550e8400-e29b-41d4-a716-446655440000","data":"example","time":"2026-04-29T14:00:00Z","type":"example","source":"example"}`).Wait()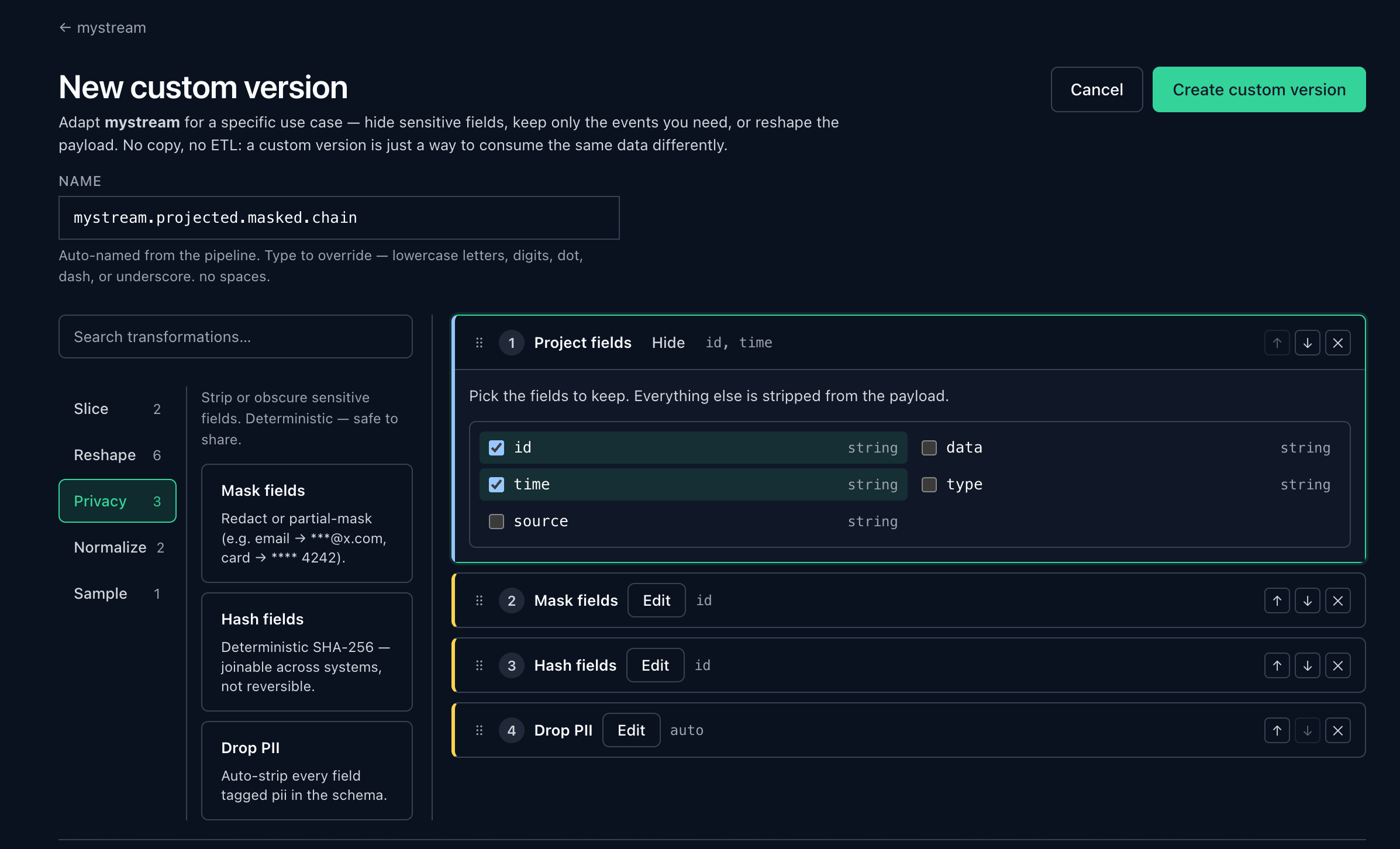
kcat -C -b kafka.demo.ivy.conduktor.io:9094 -t mystream -o beginning -e \
-X security.protocol=SASL_SSL \
-X sasl.mechanism=SCRAM-SHA-256 \
-X sasl.username=tok_V8WkorRDLT6NYxg3CPpUKQ \
-X sasl.password=ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmMkafka-console-consumer \
--bootstrap-server kafka.demo.ivy.conduktor.io:9094 \
--topic mystream \
--from-beginning \
--consumer-property security.protocol=SASL_SSL \
--consumer-property sasl.mechanism=SCRAM-SHA-256 \
--consumer-property sasl.jaas.config='org.apache.kafka.common.security.scram.ScramLoginModule required username="tok_V8WkorRDLT6NYxg3CPpUKQ" password="ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM";'import { Kafka } from "kafkajs";
const kafka = new Kafka({
brokers: ["kafka.demo.ivy.conduktor.io:9094"],
ssl: true,
sasl: { mechanism: "scram-sha-256", username: "tok_V8WkorRDLT6NYxg3CPpUKQ", password: "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM" },
});
const consumer = kafka.consumer({ groupId: "my-app" });
await consumer.connect();
await consumer.subscribe({ topic: "mystream", fromBeginning: true });
await consumer.run({
eachMessage: async ({ message }) => console.log(message.value?.toString()),
});from confluent_kafka import Consumer
c = Consumer({
"bootstrap.servers": "kafka.demo.ivy.conduktor.io:9094",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "tok_V8WkorRDLT6NYxg3CPpUKQ",
"sasl.password": "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
"group.id": "my-app",
"auto.offset.reset": "earliest",
})
c.subscribe(["mystream"])
while True:
msg = c.poll(1.0)
if msg and not msg.error():
print(msg.value().decode())import "github.com/confluentinc/confluent-kafka-go/v2/kafka"
c, _ := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "kafka.demo.ivy.conduktor.io:9094",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "tok_V8WkorRDLT6NYxg3CPpUKQ",
"sasl.password": "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
"group.id": "my-app",
"auto.offset.reset": "earliest",
})
c.Subscribe("mystream", nil)
for {
msg, err := c.ReadMessage(-1)
if err == nil {
println(string(msg.Value))
}
}import pika, ssl
ctx = ssl.create_default_context()
params = pika.URLParameters("amqps://tok_V8WkorRDLT6NYxg3CPpUKQ:ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM@amqp.demo.ivy.conduktor.io:5671/%2F")
params.ssl_options = pika.SSLOptions(ctx)
conn = pika.BlockingConnection(params)
ch = conn.channel()
ch.queue_declare("mystream", durable=True)
for method, props, body in ch.consume("mystream", auto_ack=True):
print(body.decode())import amqp from "amqplib";
const conn = await amqp.connect("amqps://tok_V8WkorRDLT6NYxg3CPpUKQ:ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM@amqp.demo.ivy.conduktor.io:5671/");
const ch = await conn.createChannel();
await ch.assertQueue("mystream", { durable: true });
ch.consume("mystream", (msg) => {
if (msg) {
console.log(msg.content.toString());
ch.ack(msg);
}
});import amqp "github.com/rabbitmq/amqp091-go"
conn, _ := amqp.DialTLS("amqps://tok_V8WkorRDLT6NYxg3CPpUKQ:ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM@amqp.demo.ivy.conduktor.io:5671/", nil)
ch, _ := conn.Channel()
msgs, _ := ch.Consume("mystream", "", true, false, false, false, nil)
for msg := range msgs {
println(string(msg.Body))
}curl -N "https://http.demo.ivy.conduktor.io/topics/mystream/stream?from=earliest" \
-H "Authorization: Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM" \
-H "Accept: text/event-stream"const res = await fetch("https://http.demo.ivy.conduktor.io/topics/mystream/stream?from=earliest", {
headers: {
Authorization: "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
Accept: "text/event-stream",
},
});
for await (const chunk of res.body) {
console.log(new TextDecoder().decode(chunk));
}import requests
with requests.get(
"https://http.demo.ivy.conduktor.io/topics/mystream/stream?from=earliest",
headers={"Authorization": "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM", "Accept": "text/event-stream"},
stream=True,
) as r:
for line in r.iter_lines():
if line:
print(line.decode())package main
import (
"bufio"
"net/http"
)
func main() {
req, _ := http.NewRequest("GET", "https://http.demo.ivy.conduktor.io/topics/mystream/stream?from=earliest", nil)
req.Header.Set("Authorization", "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM")
req.Header.Set("Accept", "text/event-stream")
resp, _ := http.DefaultClient.Do(req)
defer resp.Body.Close()
s := bufio.NewScanner(resp.Body)
for s.Scan() {
println(s.Text())
}
}wscat -c "wss://http.demo.ivy.conduktor.io/ws/topics/mystream" -H "Authorization: Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM"const ws = new WebSocket("wss://http.demo.ivy.conduktor.io/ws/topics/mystream", ["bearer.tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM"]);
ws.onmessage = (e) => console.log(JSON.parse(e.data));import asyncio, websockets
async def main():
async with websockets.connect(
"wss://http.demo.ivy.conduktor.io/ws/topics/mystream",
extra_headers={"Authorization": "Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM"},
) as ws:
async for msg in ws:
print(msg)
asyncio.run(main())import "github.com/gorilla/websocket"
h := http.Header{"Authorization": []string{"Bearer tok_V8WkorRDLT6NYxg3CPpUKQ.ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM"}}
c, _, _ := websocket.DefaultDialer.Dial("wss://http.demo.ivy.conduktor.io/ws/topics/mystream", h)
for {
_, msg, err := c.ReadMessage()
if err != nil { break }
println(string(msg))
}mosquitto_sub -h mqtt.demo.ivy.conduktor.io -p 8883 \
-u tok_V8WkorRDLT6NYxg3CPpUKQ -P "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM" \
-t "mystream" -q 1 -vimport mqtt from "mqtt";
const c = mqtt.connect("mqtts://mqtt.demo.ivy.conduktor.io:8883", {
username: "tok_V8WkorRDLT6NYxg3CPpUKQ",
password: "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM",
});
c.on("connect", () => c.subscribe("mystream", { qos: 1 }));
c.on("message", (topic, payload) => console.log(payload.toString()));import paho.mqtt.client as mqtt, ssl
def on_message(client, userdata, msg):
print(msg.payload.decode())
c = mqtt.Client()
c.username_pw_set("tok_V8WkorRDLT6NYxg3CPpUKQ", "ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM")
c.tls_set(cert_reqs=ssl.CERT_REQUIRED)
c.on_message = on_message
c.connect("mqtt.demo.ivy.conduktor.io", 8883, 60)
c.subscribe("mystream", qos=1)
c.loop_forever()import mqtt "github.com/eclipse/paho.mqtt.golang"
opts := mqtt.NewClientOptions().
AddBroker("tls://mqtt.demo.ivy.conduktor.io:8883").
SetUsername("tok_V8WkorRDLT6NYxg3CPpUKQ").
SetPassword("ipk_hGg8uEBnIPi7bDHszUrAZ3RAjTLfz2KeEH8YD6BTUmM")
c := mqtt.NewClient(opts)
c.Connect().Wait()
c.Subscribe("mystream", 1, func(_ mqtt.Client, m mqtt.Message) {
println(string(m.Payload()))
}).Wait()On the edge, or as the backend.
Plug Ivy into the data you already produce, or write to it directly and use it as your activation backend.
Either way, every consumer reads the result in its native protocol.
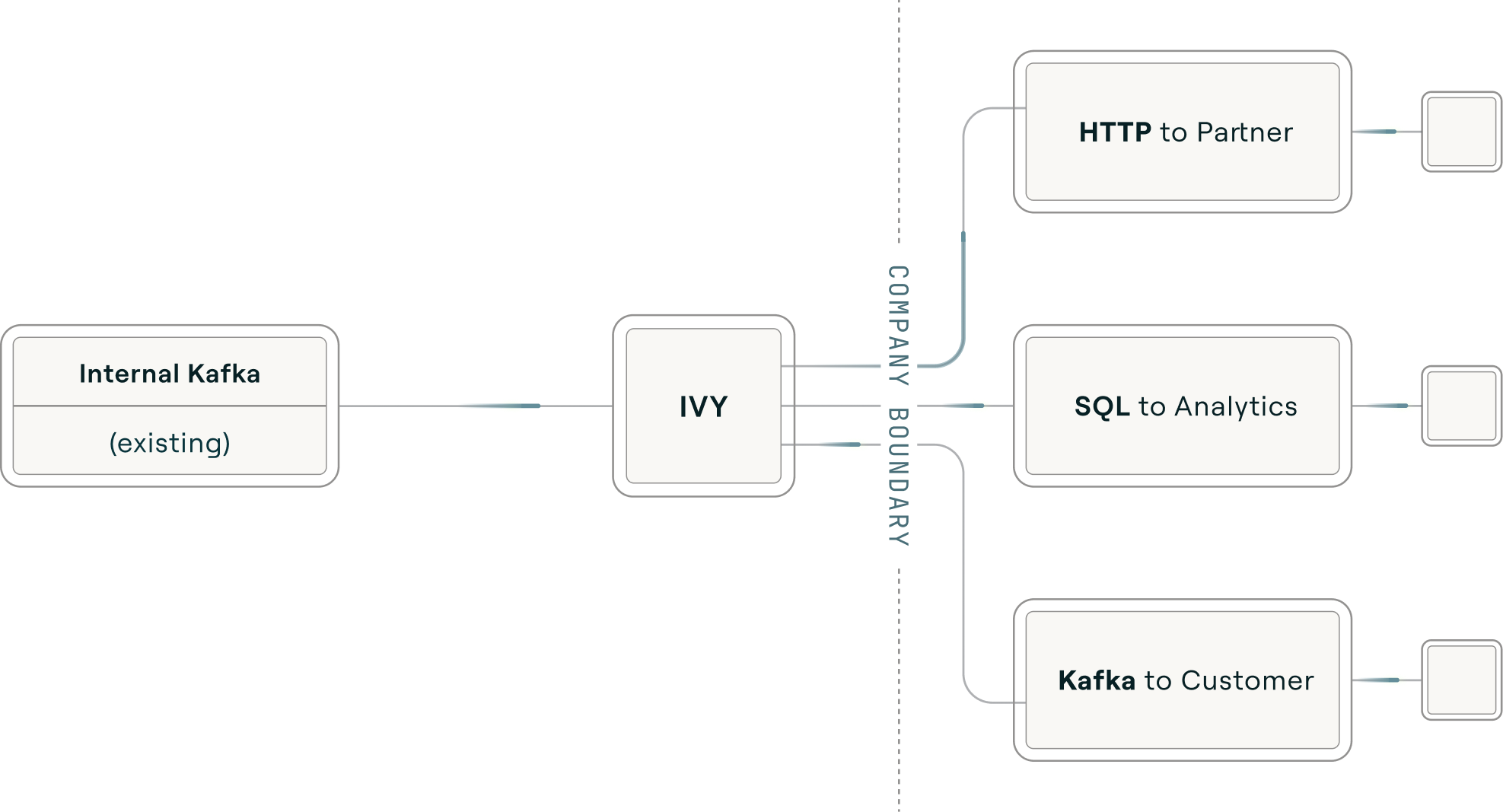
Ivy on the edge
Your existing Kafka topics or any other protocol sync to Ivy. Operational data becomes shareable and usable in the protocol they wish, without any ETL.
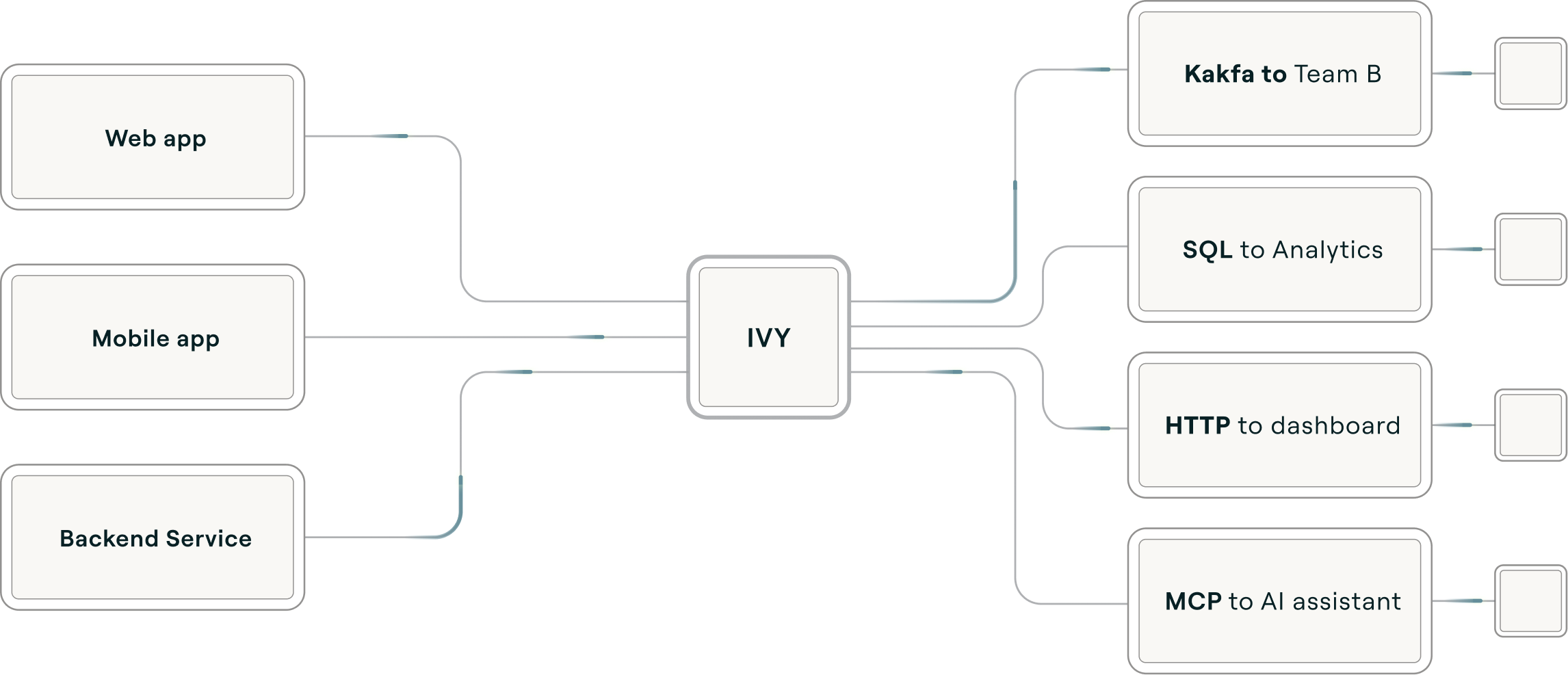
Ivy as a messaging infra
Your app writes records to Ivy. Your team queries them. Your agent reads them. Each in their own protocol. Ivy is the backend.
Built in, not bolted on. Everything you need to capture, correlate, and activate real-time data in one binary: the full broker, plus the parts you'd otherwise wire up yourself, Connect, Schema Registry, an auth proxy, a state store, and the audit pipeline.
Multi-protocol I/O
HTTP, MQTT, WebSockets, Kafka, SaaS webhooks, and Postgres CDC. Native ingest and egress. No Connect cluster to operate separately.
Native pub/sub
Consumer groups, ordered partitions, fan-out, fan-in, DLQ, and replay. Kafka-protocol compatible. Your existing producers and consumers keep working.
Stateful processing
Pattern matching, tumbling and sliding windows, cross-stream joins, and exactly-once outputs. Built in a visual UX. No RocksDB or Redis to operate.
Schema catalog
Topics, schemas, versions, owners, ACLs, and lineage. Queryable over HTTP, the SDK, or exposed as MCP resources.
Unified governance
SSO, RBAC, field-level masking, schema enforcement, and full audit log. Applied once at ingest, not duplicated per consumer.
Replay & point-in-time
Read from any offset or timestamp. Bounded retention, configurable per stream. Debug a rule, redo a deploy, and audit a chain.
MCP server, built in
Agents browse the catalog, subscribe to topics, and trigger rules. Every call token-scoped, every call audited.
Postgres-wire SQL
Query live event streams with psql, dbt, or any BI tool. Point-in-time and bounded-history queries within the retention window, no warehouse round-trip.
Any protocol in. Any protocol out. No pipeline in between.
One platform speaks every language, so the same correlated data can be activated in any of them. Protocol-agnostic by design. Not Kafka-first, not Flink-first.
Feed your agents the context to act on.
One install. Correlate your streams, build the context, fire the triggers. Any protocol, MCP included.