Consumer incremental rebalance and static group membership
Kafka static group membership (group.instance.id) and incremental cooperative rebalancing: two ways to cut consumer downtime during Kafka rebalancing.
By Stéphane Derosiaux · July 23, 2026
Learn how to minimize rebalance disruption
Kafka's incremental cooperative rebalancing and static group membership features reduce the disruption caused by consumer group rebalances, improving overall system stability and performance.
What you'll learn:
- How incremental cooperative rebalancing reduces processing downtime
- The multi-phase rebalancing process and how it differs from eager rebalancing
- How to configure static group membership for stable consumer identities
- Best practices for production deployments
Traditional rebalancing problems
Eager rebalancing (pre-Kafka 2.4)
- Stop-the-world: All consumers stop processing during rebalance
- Complete reassignment: All partitions are revoked and reassigned
- Processing downtime: No messages processed during rebalance period
- Cascading rebalances: One consumer failure affects entire group
Performance impact
Consumer 1: [P0, P1, P2] → [ ] → [P0, P1]
Consumer 2: [P3, P4, P5] → [ ] → [P2, P3]
Consumer 3: [P6, P7, P8] → [ ] → [P4, P5, P6, P7, P8]
All consumers stop processing during the transitionEager versus incremental rebalancing comparison
This diagram compares the impact of eager rebalancing versus incremental cooperative rebalancing:
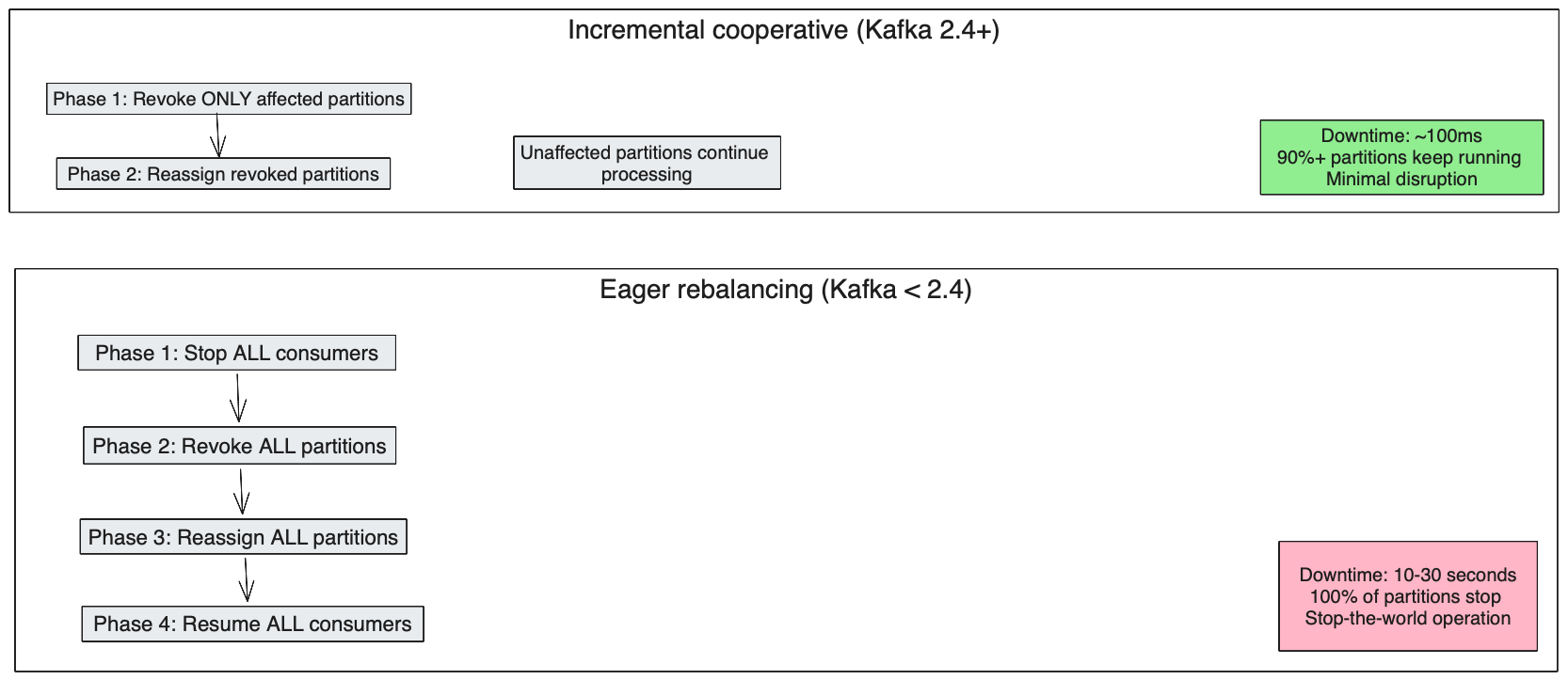
Incremental cooperative rebalancing
How it works (Kafka 2.4+)
- Minimal disruption: Only affected partitions are reassigned
- Continued processing: Unaffected partitions continue processing
- Gradual transition: Rebalance happens in multiple phases
- Reduced downtime: Significantly shorter processing interruptions
Rebalancing phases
The incremental rebalance happens in two distinct phases, minimizing disruption:
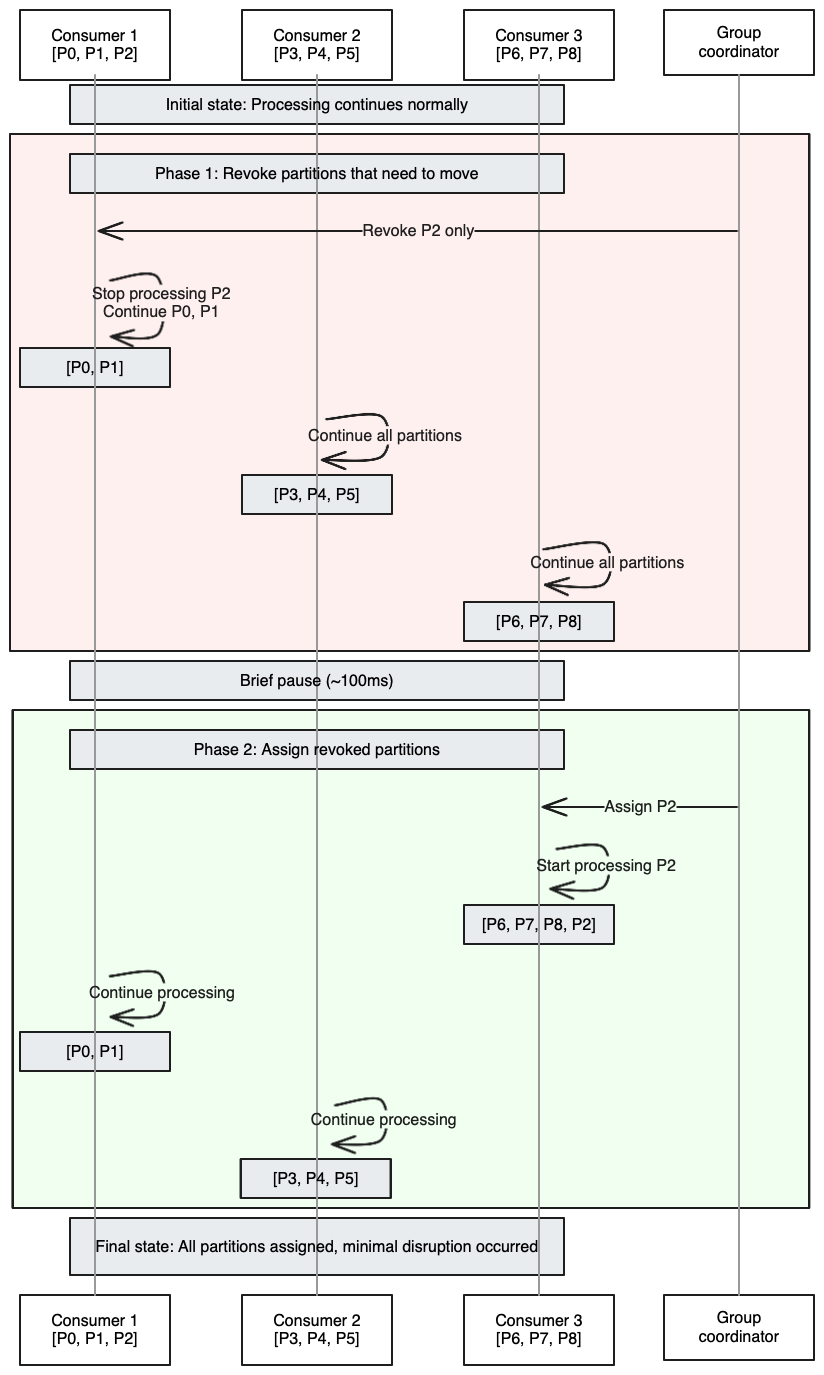
Key improvements over eager rebalancing:
- ✅ Only ONE consumer stops ONE partition (P2)
- ✅ Eight out of nine partitions never stop processing
- ✅ Total downtime: ~100ms instead of several seconds
- ✅ Cascading failures prevented
Configuration
# Enable incremental cooperative rebalancing (default in Kafka 2.4+)
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
# Or use range assignor with cooperative rebalancing
partition.assignment.strategy=org.apache.kafka.clients.consumer.RangeAssignorStatic group membership
Concept
Static group membership allows consumers to maintain stable identities across restarts, preventing unnecessary rebalances during planned maintenance or brief outages.
Benefits
- Fewer rebalances: Consumer restarts don't trigger rebalances
- Stable assignments: Partitions stay with the same consumer instance
- Faster recovery: Consumers can resume processing from where they left off
- Operational efficiency: Planned maintenance doesn't disrupt other consumers
Configuration
# Assign static member ID to consumer
group.instance.id=consumer-instance-1
# Increase session timeout for planned restarts
session.timeout.ms=300000 # 5 minutes
# Adjust heartbeat interval accordingly
heartbeat.interval.ms=100000 # ~1.7 minutesConsumer lifecycle
Properties props = new Properties();
props.put("group.id", "my-consumer-group");
props.put("group.instance.id", "consumer-1"); // Static member ID
props.put("session.timeout.ms", "300000"); // 5 minutes
props.put("heartbeat.interval.ms", "100000"); // ~1.7 minutes
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);Use cases and benefits
High-availability applications
# Configuration for critical applications
group.instance.id=${hostname}-${process.id}
session.timeout.ms=300000
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
# Allows planned restarts without affecting other consumersContainerized environments
# Kubernetes deployment example
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
containers:
- name: kafka-consumer
env:
- name: GROUP_INSTANCE_ID
value: "consumer-${POD_NAME}"
# Consumer will maintain identity across pod restartsStream processing applications
- State preservation: Local state stores remain associated with specific consumers
- Reduced reprocessing: Avoid recomputing state after rebalances
- Consistent partitioning: Same consumer always processes same partitions
Monitor and observe
Key metrics
- Rebalance frequency: Number of rebalances per time period
- Rebalance duration: Time taken for rebalance completion
- Partition assignment stability: How often partitions change owners
- Consumer lag during rebalance: Processing delay during rebalances
JMX metrics
# Rebalance metrics
kafka.consumer:type=consumer-coordinator-metrics,client-id=*
- rebalance-rate-per-hour
- rebalance-latency-avg
- rebalance-latency-max
# Assignment metrics
kafka.consumer:type=consumer-metrics,client-id=*
- assigned-partitionsConfiguration best practices
For incremental rebalancing
# Use cooperative assignors
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
# Optimize for stability
session.timeout.ms=45000
heartbeat.interval.ms=15000
max.poll.interval.ms=300000For static group membership
# Stable consumer identity
group.instance.id=unique-consumer-id
# Extended timeouts for planned restarts
session.timeout.ms=600000 # 10 minutes
heartbeat.interval.ms=200000 # ~3.3 minutes
# Prevent accidental timeouts
max.poll.interval.ms=900000 # 15 minutesCombined configuration
# Best of both worlds
group.instance.id=consumer-${hostname}
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
session.timeout.ms=300000
heartbeat.interval.ms=100000
max.poll.interval.ms=600000Operational considerations
Deployment strategies
- Rolling updates: Use static group membership for zero-downtime deployments
- Blue-green: Static IDs help maintain partition assignments
- Canary releases: Incremental rebalancing minimizes impact on stable consumers
Maintenance windows
# Planned consumer restart with static membership
# 1. Consumer stops gracefully
# 2. Other consumers continue processing (no rebalance)
# 3. Consumer restarts with same group.instance.id
# 4. Resumes processing assigned partitionsTroubleshooting
Common issues and solutions:
- Duplicate static IDs: Ensure unique
group.instance.idper consumer - Long session timeouts: Balance between stability and failure detection
- Assignment strategy conflicts: Ensure all consumers use compatible assignors
When migrating to incremental rebalancing and static membership, start with incremental rebalancing first, monitor rebalance behavior and performance, then gradually introduce static group membership and test failure scenarios thoroughly.
Static member considerations
- Static members that don't restart within
session.timeout.mswill be removed from the group- Ensure unique
group.instance.idvalues to avoid conflicts- Plan for scaling scenarios where static IDs need management
Performance impact
Before (eager rebalancing)
Rebalance triggered → All consumers stop → Complete reassignment → Resume processing
Downtime: 10-30 seconds for entire consumer groupAfter (incremental + static)
Rebalance triggered → Only affected partitions stop → Minimal reassignment → Resume processing
Downtime: 1-5 seconds for affected partitions onlyMeasurable improvements
- 90% reduction in processing downtime during rebalances
- 50% fewer unnecessary rebalances with static membership
- Improved throughput due to reduced processing interruptions
- Better consumer utilization with sticky partition assignments
See it in practice with Conduktor
Conduktor Console visualizes consumer group rebalances in real-time, showing which partitions are being reassigned and the rebalance duration. Monitor consumer lag during rebalances to verify that incremental rebalancing is minimizing disruption as expected.
Next steps
- Move on to Kafka administration to operate and maintain your cluster
- Understand delivery semantics for reliable processing
- Configure consumer settings for optimal performance