
Why build a Streaming Platform?#
At Conduktor, we speak with hundreds of customers, learning about their Kafka journeys and what we can do to make them smoother. The theme of these conversations is very similar:
- One team finds Kafka and uses it. They manage it themselves, and everyone is happy
- Kafka is pretty cool. Other teams have started to use it. The original team manages Kafka for everyone, or each team spins up its clusters and manages them in its own way. Everyone is still relatively happy.
- Kafka is really quite cool. More and more teams have started to use it too. You get exponential growth, an explosion of Kafka. Everyone isn't quite as happy as they were, as managing the wide usage of Kafka comes with challenges and costs.
We see two general ways that organization use to deal with this exponential growth:
- Centralization: central team is in charge of all of Kafka-things for the organization.
- Decentralization: each team manages its own Kafka.
Centralized or not: How to build a Streaming Platform for an organization?
Let's deep dive into these extremes and explore a third option... hybrid!
Let's centralize Kafka ownership!#
Some organizations have a Kafka Central team to manage everything-Kafka: from clusters to software. This team manages topic creation, ACLs (security), new cluster requests (like for a new product), and general administration around developer requirements.
They want to build a magnificent Streaming Platform to help the organization.
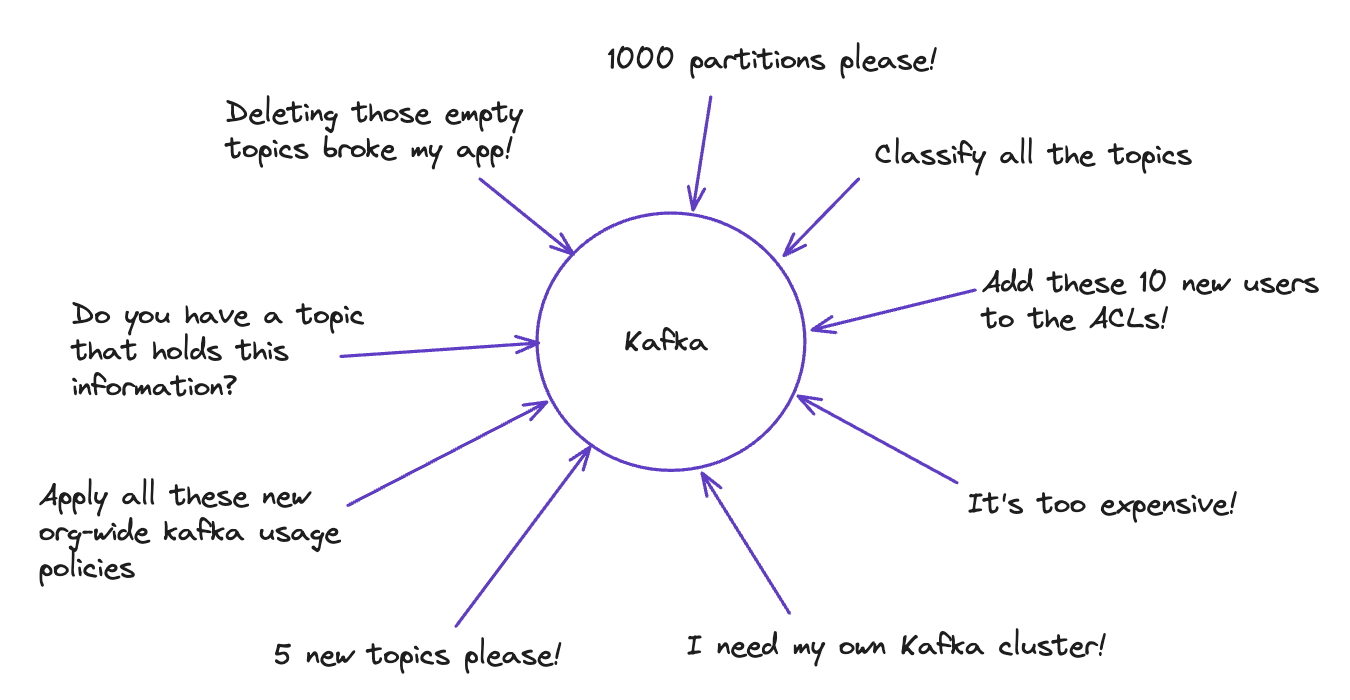
This Central team is expected to know what all the topics and Kafka instances are for. In retrospect, they will often require time to do some archeology and understand the history and how we got here.
Examples that might sound familiar:
- They get asked to categorize 500 topics from across the organization and decide whether they are configured correctly or are still needed. They need to know why there are mysterious empty topics that can't be deleted due to use by legacy applications.
- They are the gatekeepers preventing 1000 partition topics from being created. They know the rules and regulations that need to be adhered to and need to try and keep everyone in line. People try and get around them because of delays or because their perceived requirements don't match what is allowed by default by the central team.
- They get quizzed by the CFO on why Kafka costs so much and are challenged to reduce the spending without impacting the business.
This Central team would LOVE to focus on Kafka and unleashing value from its data, spreading it even more in the organization and accelerating how developers work with it… but they are spending time answering all the support questions and trying not to be an administration bottleneck!
One typical solution of organizations is to grow this Central team, adding more people to absorb the throughput of requests instead of fixing the real issue: don't create a bottleneck.
Let's decentralize Kafka ownership, Free The Data!#
On the other side of the spectrum, we have the full decentralized model: let each Product team do their thing. They will move fast and deal with their problems their way.
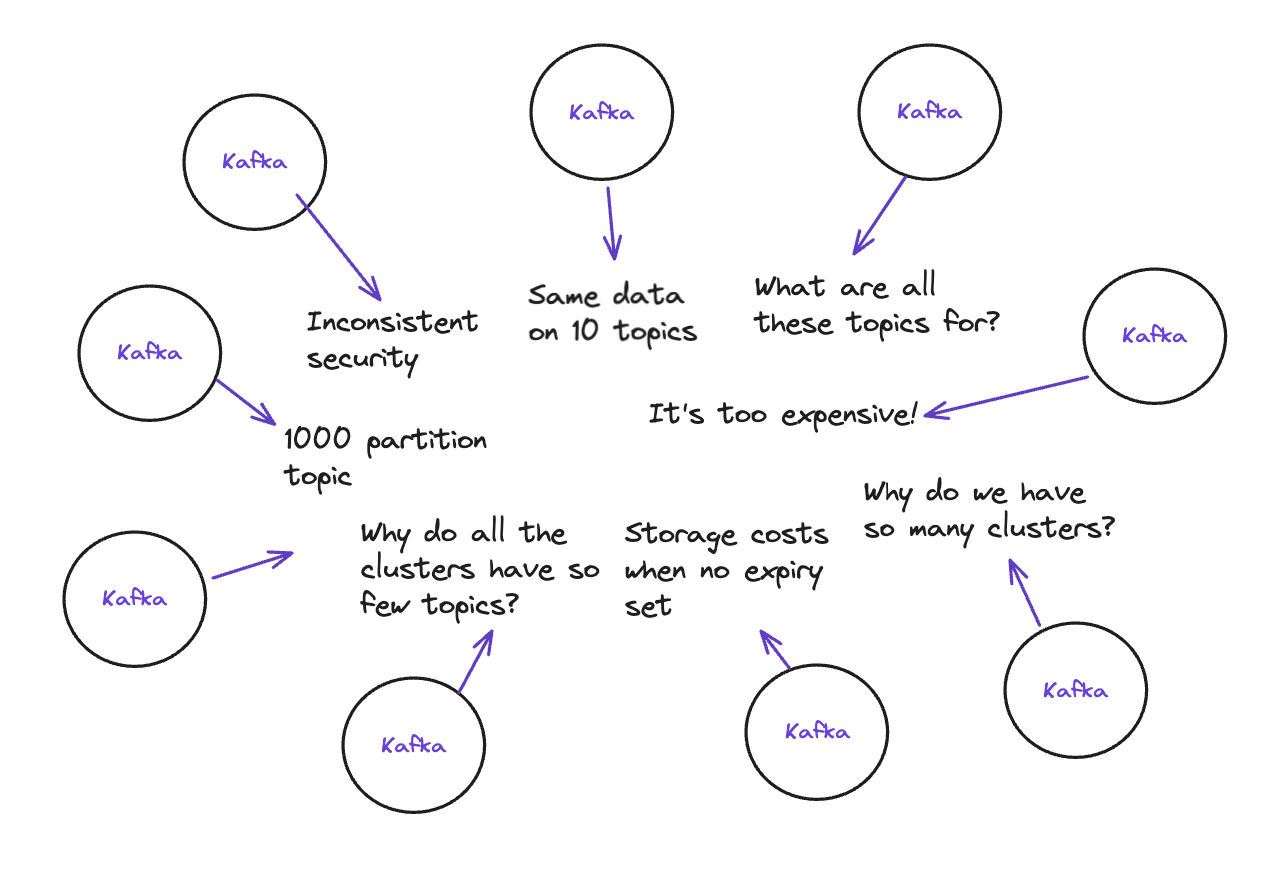
The organization encourages teams to self-serve their own Kafka as they were building their own Spring Boot application: they become responsible for Kafka resource management, topic creation, ACLS, Kafka Connect, and general Kafka admin. They can rely on Kafka Expert in the company, but the goal is similar to the DevOps culture:
you build it, you run it!
All the Kafka clusters and operations are going to be different as there are no gatekeepers to enforce organizational rules, eg:
- People make 1000 partition topics.
- Security is inconsistent, with different (or no) policies across the teams.
- Topic and cluster configuration varies hugely and doesn't adhere to best practices - infinite expiry can result in substantial storage costs, expiry is not correctly considered, data can be lost, etc.
No one else except the Product team owning one Kafka knows what the topics are for. The organization has no way to enforce various strategies or is going to be in pain:
- Reduce cost or complexity by clearing up topics
- Data may be duplicated as teams might create their own clusters to hold the same information.
- No Kafka best practices sharing
- People turnover will create knowledge-loss
- Security, encryption of data: a black hole
- GDPR, PII, PCI, Regulations: how can you even consider applying them at scale?
Many clusters are set up, each with a tiny handful of topics and partitions driving huge cloud provider costs and inefficient use of resources. The average number of topics on a cluster ends up being tiny, with 150 or more clusters, each hosting just a handful of topics. The global organization Kafka cost explodes. Nobody knows exactly what to do as a priority, and teams are challenged to reduce spending on their own significantly.
What about a Hybrid approach?#
These stories are familiar to us, both Conduktor engineers and our customers having lived through them.
We work with organizations to set them in the right direction: right from the start of their Kafka journey so they avoid the tech debt, the outages, and all the associated costs of the two approaches described above. This is how we build trust with our customers.
As with most things, there is a sweet spot, a middle ground, for managing these challenges and building a proper Streaming Platform.
5 steps to Redemption#
1. Ask yourself: Should I be organized?#
- Maybe you're a small organization, and it's very unlikely that your Kafka usage will grow to a point where you need some structure and direction.
- Maybe Kafka is not your central nervous system in your organization, just a geeky initiative on the side.
- Maybe you have a small team but a very high throughput in Kafka because of logs and tons of events, and this is all that matters to you.
If that's the case, stop reading this part.
If that's not the case, starting to future-proof right from the beginning might be your best bet, and your future you will thank you.
Perhaps you're just getting started or you are in the middle of the journey: your Kafka usage is growing. NOW is the time to put structure around how you use Kafka before it becomes costly and time-consuming to put into place.
Or you're very experienced with Kafka... but also becoming overwhelmed with the management and financial costs of such a large undertaking! It is possible to bring structure at this point, and while it can be an involved process at this stage, it is often the point at which our customers come to us for help.
Let's be clear: the longer you wait to introduce a solution, the more you'll suffer in the end.
2. Decouple your applications from your Kafka Clusters#
You decided that you have to organize yourself now. Good.
One aspect of Kafka is that all applications and tooling are connected to it directly. So if you want to add processes or enforce practices, you must add things inside the applications directly (Spring Boot, Kafka Streams, etc.) or on the Kafka side (and it's generally impossible because you don't have such control).
You can implement process-based rules in place around how teams should use Kafka (think: a Wiki page, an Excel file), but without extra tooling, those rules will be forgotten about, broken, and be hard to impossible to maintain because Kafka just isn't set up for this type of user experience.
What we suggest is to put another layer in the middle! Let's call it Gateway.
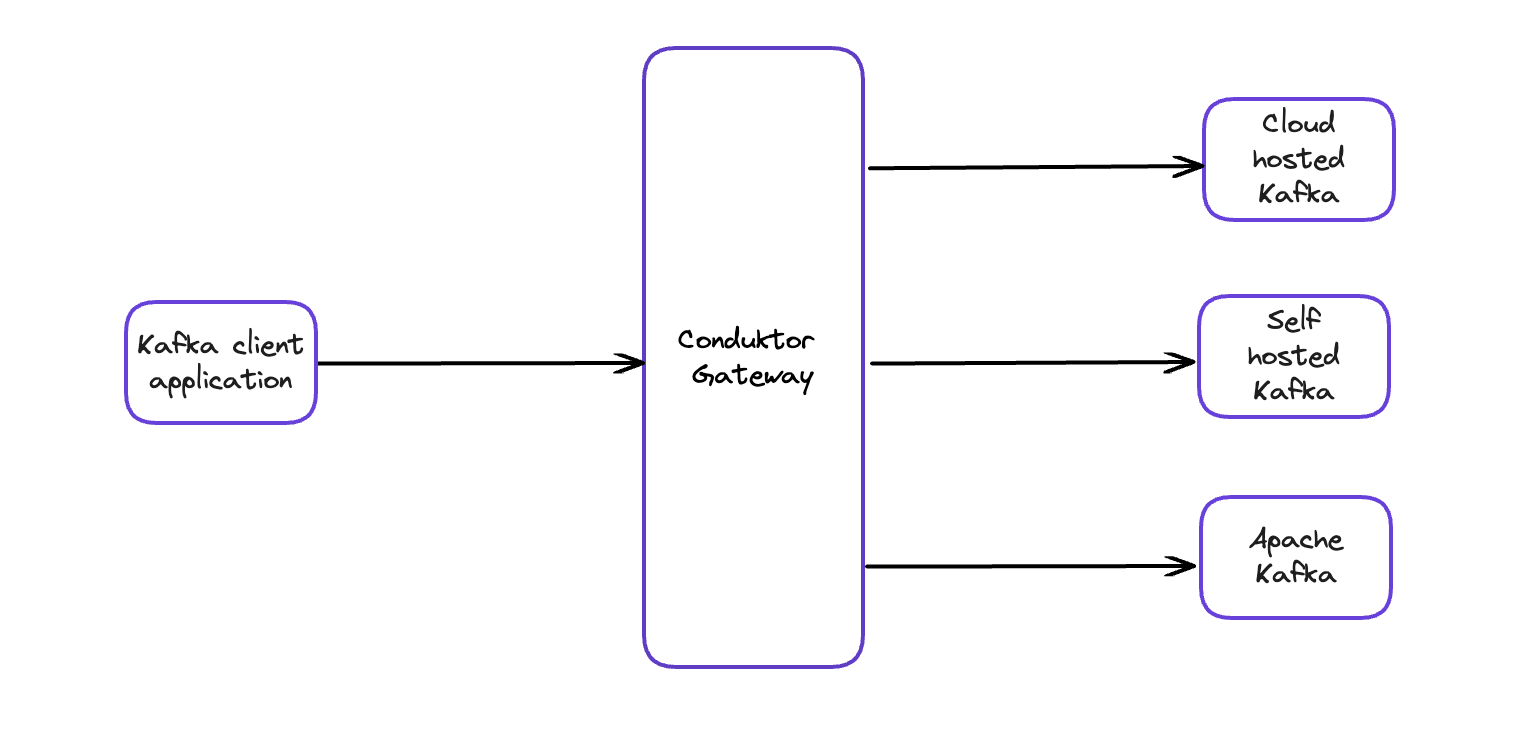
Putting a layer between your Kafka applications and your Kafka clusters means you can intercept the traffic from any applications and tooling using your Kafka and enforce any rule you want! You get infinite flexibility without altering your applications/Kafka ecosystem, no need to upgrade them, etc. The experience is seamless.
- Topic creation requests
- Topic & Broker configuration changes
- Produce requests
- Consumers, commits
- ACL setup
- ...
This is how you put rules and enforce them on a distributed system like Kafka. This model even supports multiple Kafka clusters and all its flavors and is language-agnostic (whether you're using Rust, Java, or Bash, it will work!).
3. Multi-tenancy? Eh?#
In our Kafka world, Multi-tenancy is the ability to split a real (physical) Kafka cluster into many separate virtual (logical) Kafka clusters (a tenant). Each logical cluster looks like a standard Kafka cluster to its users and applications and is entirely ISOLATED: a tenant thinks it's alone in its world. It's the only one which can access the resources available to the tenant: they are invisible to other tenants.
A tenant can mean anything to you. It's just something you want to be isolated from:
- a business domain: delivery, sales, customers
- a project: having its own applications and topics
- an application: having multiple topics
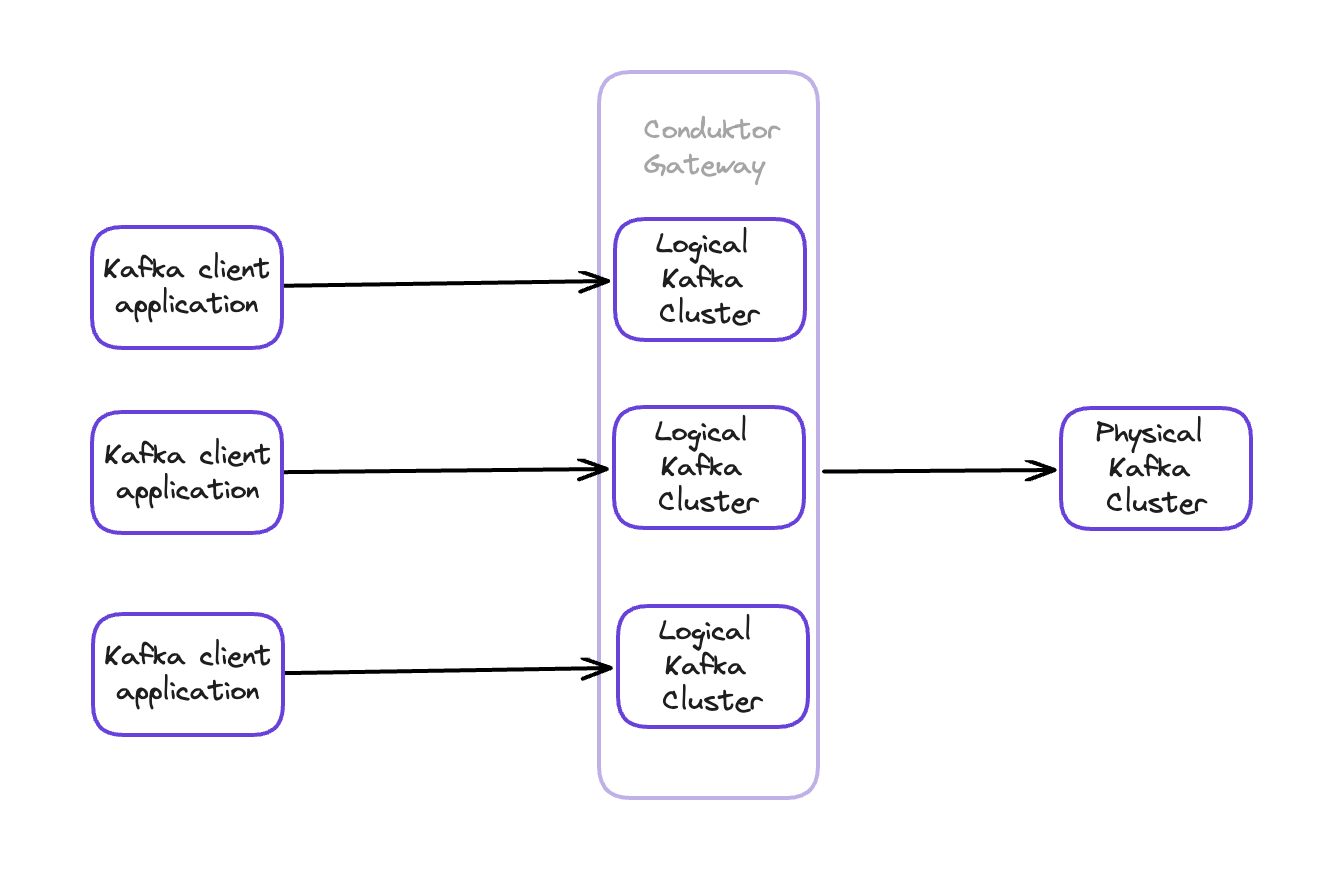
It might sound like a tank to kill a fly, but it's just a bleeding-edge technology we built that solves many problems, especially regarding cost and flexibility.
Note: With a normal Kafka, multi-tenancy, in a form, is possible. You can 'namespace' the resources (add a prefix to all resources), then put in place ACLs to limit who can access these resources (with all the problems due to ACLs at scale...). You can put in place client quotas. All of this is very manual and more involved that you'd hope. While it's not quick and easy to add a new tenant, it is quick and easy for things to go wrong.
Conduktor Gateway is natively multi-tenant and hides any form of complexity. View multi-tenancy demo.
Examples of what an organization can get from multi-tenancy:
- Reduce the number of physical Kafka clusters required (cost)
- Reduce the complexity of having tons of physical Kafka clusters and managing them
- Spin up temporary Kafka clusters for transient usage like e2e testing or a sandbox for developer
- Avoid cross-cluster replication: offer read-only data access between clusters, no need for any replication (reduce cost and operational complexity)
- Build your Data Mesh: split an organization into data domains (advanced usage)
4. Introduce Self-service tooling#
Giving developers access to their own logical cluster with multi-tenancy means that individuals are in charge of their own Kafka usage without the risk of proliferation of Kafka clusters. They can self-serve their environment:
- setting up topics
- retention times
- topic-specific configuration
- ACLs
- ... everything else without impacting the other Kafkas
There's no central bottleneck (no Central team to apply stuff on your Kafka), so there are no delays in setting up new data requirements. If a team needs a topic, they can make one. If a topic is obsolete, they can delete it without asking. The teams own their own data and are in charge of it. This means they can focus on what the data is telling them, getting additional value from it, and this, WITHOUT thinking about the infrastructure itself.
It looks like the decentralised model we mentioned before, right? What is so different except the multi-tenancy approach?
5. Enforce rules for applications and safeguard the underlying infrastructure#
Developers who can self-serve themselves: it's nice, but it does not protect them from making bad decisions (they will!) about how they use their logical Kafka clusters. They can still:
- set infinite retention without realizing it
- create 1000 partition topics
- forget to enable
acks=all+min.insync.replicas=2on Produce requests to avoid data loss - produce data with a bad schema crashing the consuming applications
- ...or any number of other configuration requirements specific to your organization.
By being between applications and the infrastructure, Gateway can protect against these bad usage patterns or any organizational standards you may have:

It gives you all the power you don't have with Kafka, which is a pure-infrastructure product:
- Logical technical or business rules when producing/consuming data
- Audit everything
- Encrypt data at will
- Introduce lineage information in the flow
- Robust RBAC system instead of basic ACLs
- ...
This helps in other dimensions, from reducing cost to seamless end-to-end encryption and various ways of deploying it.
Here are a few scenarios where you can enforce rules:
- If a user tries to create a topic with
replication_factor=1, and you require areplication_factor=3, then the topic creation request can be rejected, telling the user to increase their replication factor. - If your organization requires that all
credit_carddetails are encrypted, then Gateway can encrypt all the fieldscredit_cardgoing through. - If you need topics to adhere to a particular naming convention
[BU]-[Project]-[PrivacyLevel]-namethen the naming requirements can be enforced. - You can go soft: add rules without enforcing them, but be notified if an application is not following them. You can then track non-compliance and have a discussion without disrupting the normal flow. (think: migration or during an analysis phase).
Conclusion: it depends!#
Everyone's Kafka journey is different: challenges and requirements. However, shared themes around Kafka management and usage are seen across these journeys. People often fall into extremes when navigating these challenges: centralized management? Decentralized self-serve? Both of these approaches have complex technical and organizational pitfalls.
We think that the hybrid approach, decentralized governance, is truly the best one. It brings the good sides of both approaches (self-service to improve the time-to-market and flexibility) while avoiding the pains and prohibitive costs (by introducing more seamless controls and guard rails).
We hope you enjoyed this article and that it gave you some ideas for your Kafka infrastructure. Really, contact us if you want to discuss your use cases. We want to build out-of-the-box and innovative solutions for enterprises using Apache Kafka, so we are very interested in your feedback.
You can download the open-source version of Gateway from our Marketplace and start using our Interceptors or build your own!
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.