
We recently launched Conduktor Gateway to help you enhance Kafka functionality. You can now try our open-source Gateway on Conduktor Marketplace! One of the ways that Gateway can enhance Kafka functionality is by enforcing Kafka best practices to safeguard against potential Kafka issues.
Safeguarding is at the intersection of data governance and enforcing technical best practices. Ensuring not only that the data in your system is healthy, valid, and useful but also that your ability to serve that data is not compromised by bad actors in the system. Effective safeguarding can help organizations:
Minimize outages
Respond gracefully to change
Reduce friction between domain teams
What is safeguarding?
Safeguarding, as the name suggests, is all about protection. Protection for the data that flows through your cluster and protection for the cluster itself. We like to define safeguarding as the practice of protecting your data and infrastructure from intentional and unintentional threats, both internal and external.
We've worked with many of our customers looking to improve their safeguarding best practices and identified three stages in their journey:
Safeguarding by habit
Reactive automation
Proactive automation
In this article, we will look at these stages in detail, identify common themes and discuss ways in which to improve and progress to the next stage.
Safeguarding by habit
Today, the majority of safeguarding policies look like this: a loose set of contracts enforced by humans. These often boil down to some documented practices that are periodically discussed and partially applied.
Safeguarding of this type often suffers from issues like:
Relevance - How well does the safeguarding rule fit the use case? Safeguarding by habit practice tends to be "one size fits all" and is not tailored or relevant for a particular technology/domain.
Timeliness - When in the development cycle is safeguarding being applied? Safeguarding by habit is often applied right at the end of the cycle when changes are difficult and costly to make.
Perception - Mostly due to the two factors above, these checks are seen as a necessary evil. "Do we have to?" and "What can we get away with?" are common phrases associated with safeguarding by habit actions.
A perfect example of this is the "production readiness checklist". These are typically applied right at the end of a development cycle. Just before a new application is released to production you develop, test, and a week before you go live, you are presented with several boxes to tick. These generally suffer from all the issues detailed above and as such carry a bad reputation.
Reactive automation
The obvious technology solution to any human-based process is to automate. Reactive automation takes the safeguarding by habit process discussed above and attempts to represent them in metrics that can be collected from your Kafka cluster. Corresponding thresholds and alerts are created on these metrics, which are triggered when they are breached. However, on detection of something irregular, the question becomes "what's next?"
Let's say there is a misbehaving client that is impacting the health of a Kafka cluster and, by association, the health of other applications connected to the cluster. Straightforward logic says you should turn the misbehaving application off. But what if it has dependencies? What if it is more mission-critical to the business than all of the applications it is impacting?
These are complex decisions that need to be made on a case-by-case basis and need to be made quickly, as they are generally caught in production and have a wide impact radius. Even worse, the pressure associated with dealing with such incidents often leads to workarounds and temporary fixes that are never removed and end up dictating technical constraints for years to come.
All of this combined adds up to tech debt, a lot of it.
Proactive automation
Proactive is the gold standard of safeguarding but rarely seen in organizations. As with reactive automation, rules are created to detect irregular actions but, instead of being reported and analyzed in the future, these rules are enforced at the point of interaction with Kafka. Requests that do not meet the standards imposed by safeguarding rules can be rejected or even automatically corrected in a way as to make them compatible before reaching Kafka.
A good example of this is a topic creation request for say 50,000 partitions. This is very unlikely to be a good idea as it can be very resource intensive for the Kafka cluster and so, instead of rejecting the request the proactive automation could modify it to hit a maximum of 50 partitions.
When you contrast this to the reactive approach, you see the value of proactive automation. Reactive automation would have found the highly partitioned topic at some point in the future and determined it was against best practice. However, at this point, the topic holds data and the task of reducing partitions is difficult and time-consuming.
How can you achieve proactive automation?
Now that we have established the reasoning behind proactive automation, let's look at how it can be achieved. This question soon becomes less of a "how" and more of a "where" it can be applied:
Within the Kafka Cluster (as a broker plugin)
Within the applications (as a client plugin)
Between Cluster and Client (as a proxy)
Proactive automation within the Kafka cluster
Deploying proactive automation as a broker plugin carries the advantage of being close to the data and also close to the running conditions of the cluster but has downsides in that the plugin operation is closely coupled to the broker operation causing issues in versioning and maintenance. Given the current state of Kafka, it is likely that the new plugin versions will incur Kafka broker restarts, etc., and all of the issues that can come along with this.
Proactive automation within the application
On the opposite side of the scale is a client plugin that runs as close to the source of events as possible. This integrates well but creates a huge surface area to manage and maintain. Common strategies would expect at least one plugin per client and require that the plugin will support a range of Kafka clients (not just Java). Worse, as the server is not aware of the plugin it cannot ensure that clients are using it. Bad actors that wish to circumvent plugin restrictions can simply not implement it and go directly to the Kafka cluster.
Proactive automation between the cluster and application
A good balance between these two options is a Kafka proxy that sits between the client and the broker. This avoids a lot of the maintenance issues described (a proxy can be configured and restarted independently of the Kafka brokers) while still providing the functionality required. The proxy represents itself as a Kafka cluster to clients so can serve all traffic from any client type and, once a proxy is in place, direct access to the Kafka cluster can be disabled via the usual Kafka security mechanisms.
Introducing Conduktor Gateway
Architecturally a proxy is the front-running solution but proxies can be very difficult to develop and the Kafka wire protocol is tricky to implement. To counter this, we introduced Conduktor Gateway, a Kafka proxy with the ability to enforce safeguarding rules. At a fundamental level, Gateway is the transport layer between your Kafka client applications and your Kafka clusters. This layer is enhanced with Conduktor Interceptors or plugins that you can install on Gateway. One such Interceptor is Safeguard, which can transform, project, or filter Kafka requests or responses with a set of rules before interaction with Kafka.
To take the example from before, to limit the number of partitions that can be created, Conduktor Gateway would execute an Interceptor on the CreateTopics request that would conditionally alter the partition count for the topic submitted in the request (from client to Gateway the request would specify 50000 partitions but from Gateway to broker it would contain just 50).
Download this Interceptor from Conduktor Marketplace.
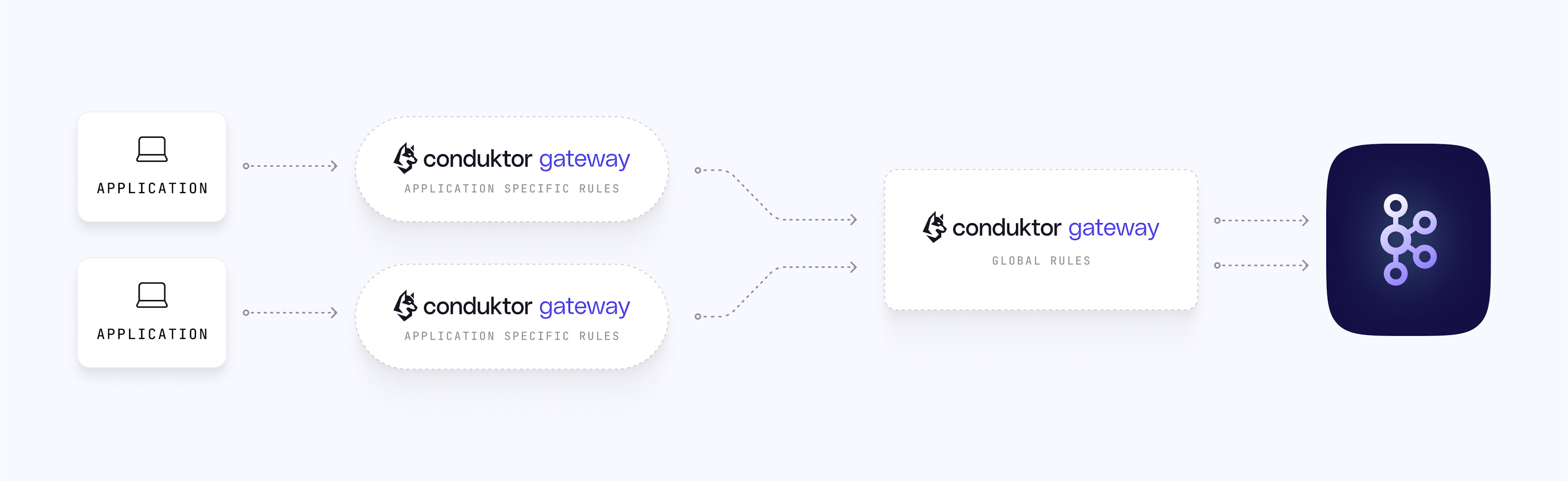
Conduktor Gateway is a stateless Java application that presents itself as a regular Kafka cluster to clients. Typical deployments have a Gateway cluster per Kafka cluster but a Gateway cluster can also be deployed per application based on use case. It's possible to have tiers of Gateway clusters where different levels of rules can be applied (i.e. rules for application 1, rules for application 2, and rules for the whole organization).

We released our open-source Gateway and some pre-built Interceptors for you to start trying Conduktor Gateway. As of now, we have the following Safeguarding capabilities available:
On top of these pre-built Interceptors, Conduktor Gateway provides a development kit for making new interceptors specific to your use cases. Interceptors can be created by implementing a few interfaces, an open-source reference edition of the Gateway is provided for testing and running these.
Conclusion
In this article, we discussed how safeguarding can be used to prevent outages and respond gracefully to change. Every organization is at a different stage of safeguarding. Achieving proactive safeguarding prevents outages and makes your Kafka clusters more resilient to unexpected change.
However, there is a more subtle benefit to consider to proactive approaches when it comes to perception. Habit-based, and reactive approaches are typically seen by developers and operators as cumbersome barriers to running their applications but, due to the early alerting and specific nature of proactive safeguarding, this perception can be reset. With a proactive approach, it is much easier to get buy-in for technical best practices and governance from application teams.
Conduktor Gateway can help you get started on your journey with proactive safeguarding. This is a proven solution that powers one of our features (Conduktor Playground) today. It makes it easy to implement simple safeguarding rules and is easily extensible to meet the requirements of your organization.
You can download the open-source version of Gateway from our Marketplace and start using Safeguard Interceptors today. If you have enterprise use cases please contact us to experience Gateway Enterprise.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.