
Introduction#
Each company has its own Kafka story, but the pattern is often the same:
- You start with a few clusters, and then you end up with a lot of them
- You have a few topics, and then you have thousands of them.
- You have a few applications, and then you have hundreds of them.
It's good because it means your company is growing, using Kafka more and more, and improving its data-driven culture. But it's also bad because it means your Kafka bill is growing fast if you don't have the right tooling to help you.
Hopefully, Conduktor has your back. We recently launched Conduktor Gateway to help you enhance Kafka functionality among other things. What is to enhance for example? Well, the cost of everything!
Let's go through several factors impacting the overall Kafka cost and how we can tackle each of them to reduce the bill.
Multi-tenancy and Virtual Kafkas#
It's common in companies to end up with a large number of clusters for historical, technical, or other reasons (we mean, dozens or even hundreds!).
These clusters cost obviously money, a lot of it, whether you're hosting them (maintenance, support, tooling etc.) or if you're using a cloud provider (AWS MSK, Confluent, Aiven, etc.).
Remember when we were only dealing with physical machines before the Cloud era? It was a nightmare to manage them, and it was expensive. Then came virtualization, and it was a game-changer. You could now run multiple virtual machines on a single physical machine, and it was a lot cheaper, way more flexible and resource-efficient.
Conduktor Gateway has a feature similar to VMWare or VirtualBox: it enables you to create as many virtual clusters as you need on a single Kafka cluster, allowing you to reduce the number of clusters you need to pay and maintain.
You now have the flexibility to choose between physical and virtual clusters. By doing so, you decrease your infrastructure costs, installation costs, and monitoring costs without changing anything for your users, who continue to be served effectively. This solution is unique on the market, with enormous value to any organization using Kafka.
You can see a Virtual Kafka as a "multi-tenant" Kafka cluster. It's a single Kafka cluster that can host multiple virtual clusters, each with its own users, topics, ACLs, quotas, etc. Bootstrap a new Kafka cluster with one API call, and done! No need to go to procurement anymore to get a new cluster.
No more networking cost. No more latency.#
If you're using a Kafka provider in the Cloud (AWS MSK, Confluent, Aiven, etc.), it means you want an easy and lazy life and that's a great choice! (who wants to maintain a Kafka cluster by themselves?). One thing to consider is if your Kafka is not in the same VPC as your application: you're going to pay some networking cost... and some latency penalty! (going in and out between networks is not free).
Conduktor Gateway sits between your Kafka client applications and your Kafka clusters. It intercepts all the traffic and all the Kafka data flowing between your applications and your clusters. One of the many things it can do is to cache Kafka data. See our Data Caching interceptor.
Why caching data is good here? By deploying Gateway close to your applications: you're going to be able to cache data close to them (caching with Kafka is completely safe because Kafka is an immutable commit log).
When you have multiple applications accessing the same topics, then the Gateway is going to fetch the data from your Kafka the first time only (not in cache yet) then the next requests for these topics will be served instantly, entirely bypassing the connection to your Kafka. As if it was not enough, the overall latency is going to drop because you're going to stay in your internal network. You can even go further by relying on the sidecar pattern (in a Kubernetes environment), then it's really going to just be 0ms (localhost, local loopback)!
Enforcing an efficient Kafka Storage#
The next cost to tackle is the Kafka storage cost.
Whether you're using a cloud-based Kafka provider or managing your own Kafka, storage will always be an issue because someone has to manage it: it scales, disks fail, corruptions occur, it has deep performance implications. Storage in Kafka is often misunderstood. Managing Storage can be seen as "boring" but it's a critical part of any Kafka infrastructure because this has so many consequences.
Let's use a simple example:
- You have one application sending a batch of messages that's 1 MB to Kafka: 1 MB of data moves over the network to Kafka
- Kafka accepts the batch and replicate this data: 2 MB of networking
- At some point, Kafka will flush the data to disk: 1 MB of batch stored on each different machine
1 MB of produced data has turned into 3 MB storage and 3 MB of networking. (more details about Kafka Message Replication on our Kafkademy).
Then, if you have 4 applications fetching this data: add 4 MB of networking from Kafka to the applications:
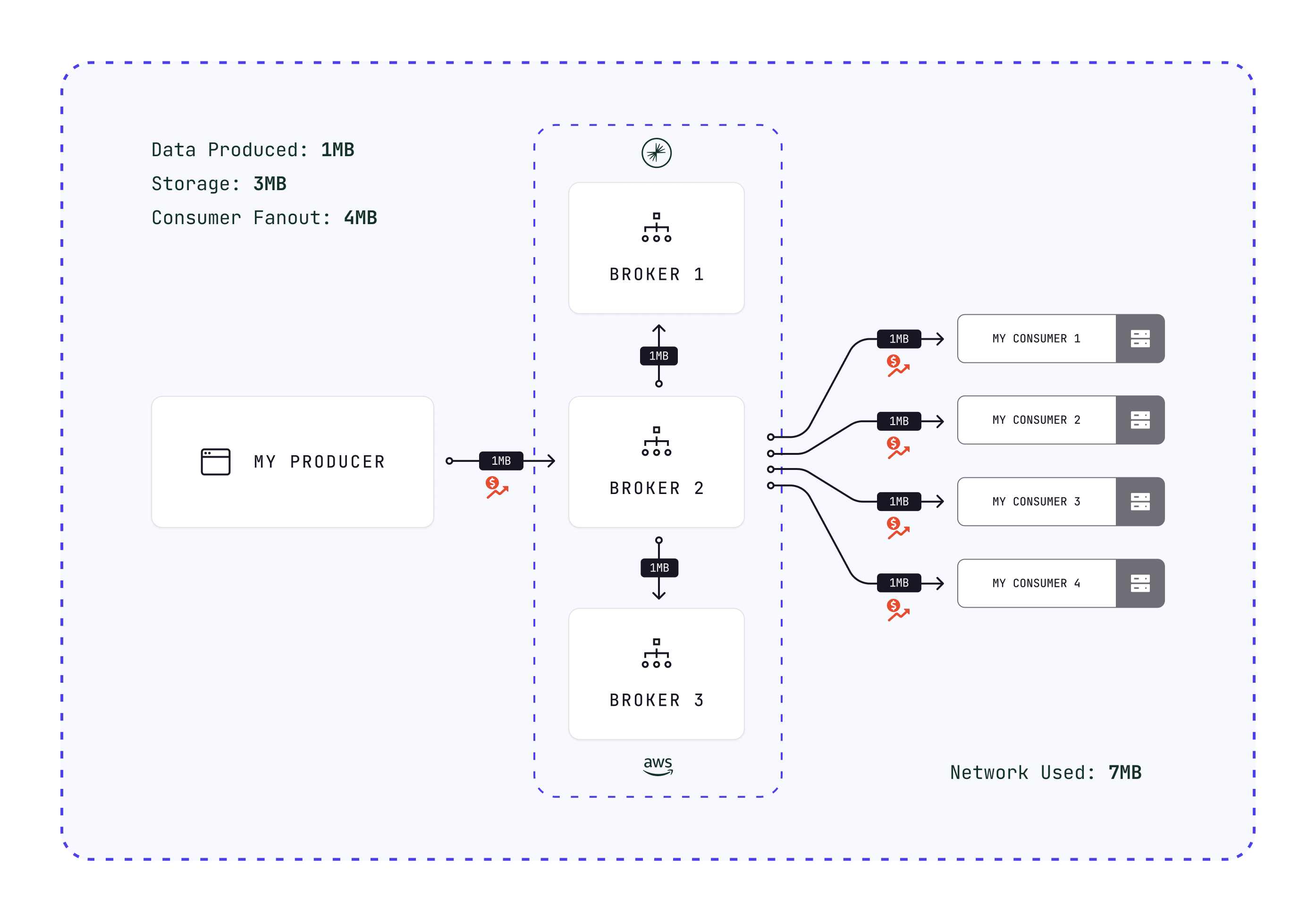
What if I tell you that you can reduce this by 10x? Because somehow, you hired Kafka expert 3k€ a day to optimize your Kafka infrastructure, and they told you that some applications are not using compression?
Easy to say but difficult to enforce for a whole company... except if you have Conduktor Gateway:
Interceptor: How to Enforce Compression
This interceptor allows you to enforce compression at the production level (the various compression types with Kafka). By enforcing all your applications hitting your Kafka to enable compression, you just reduced the 1 MB batch into a 100 KB batch: 10x improvement.

Outcomes:
- 10x less networking
- 10x less storage
- 10x faster networking and lower latency (smaller networking packets)
- A healthier Kafka infrastructure
How are Partitions and Costs related?#
A somewhat technical but real limit and cost in the Kafka universe: the number of partitions.
How do you control your partitions today? Do you have a way to enforce limits? Do you measure the impact of the number of partitions on your infrastructure? How do you know if you can continue to scale up and sustain your growth?
Preventing topic creation abuse#
You may already have some GitOps where your developers have to define some topic name and config, but then someone has to review and approve. But how do you know if the number of partitions is relevant? How do you know if the number of partitions is not too high? How do you know if the number of partitions is not too low?
What if you already have best practices in place to prevent these kind of problems, but there are ways to bypass it due to some limitations? (Like Kafka Streams or ksqlDB that can create topics on the fly) And what if you don't even have GitOps for your Kafka infrastructure? Where does freedom end and abuse start?
One very easy and simple way is to start by enforcing limits at the creation time. In essence, you're preventing errors in the abusive creation of partitions in a topic. See Topic creation Interceptor.
If your developers want something beyond your pre-defined policy, then they can have a conversation with you about their business case. You can then help them and decide what to do, based on their requirements. But at least, you have a way to enforce limits and prevent abuse for all the normal use-cases. This is where governance starts.
What about having free infinite partitions?!#
Setting limits is a must-have already but it's not enough.
If you use Debezium to do CDC (Change Data Capture), this can result in be hundreds of topics and thousands of partitions. It is common that most of them will rarely be used — because the related Tables won't have many updates — but you will still pay for them.
A typical pricing these days is: $0.0015/partition/hour.
- 100 topics, 10 partitions each = 1,000 partitions. The cost is ~$1,000/month
- 10,000 partitions? ~$10,000/month
And this is without considering the other costs (base cost, networking, storage, services, etc.).
What if I tell you that it's possible to concentrate multiple topics onto a single physical topic?
Surprise surprise, we have a feature for this, topic concentration which basically means: Unlimited Partitions (you read that right): you can have as many topics as you want, with as many partitions as you want, on a fixed-sized real topic. It's totally seamless for the applications which can create and consume any topics as usual, but you've just completely eliminated the problem related to partitions and their cost behind the scene.
How awesome is that? Talk to us to try it.
Fixing People mistakes are expensive too#
Beyond infrastructure costs, we must also consider people cost (the developers!). They are often way more expensive than the infrastructure cost itself.
From our experience, few engineers who use Kafka have received adequate training. One of the realities of IT is that we often learn on the job. Because this culture has been around for a long time, nobody pays attention to it.
As explained above, it's very easy to impact the final cost of Kafka with simple applications if left "uncontrolled". The business features are delivered, but the Kafka consequences are not understood, both in terms of cost, quality, and worst of all, future integrations. You'll go through hell if you want to fix things later, as everything is already running in production, and it's highly likely the original developers are not there anymore, that teams have evolved etc. You are stuck with a costly technical debt. Enjoy your hell. (contact us to tell your story!).
The most effective way to correct many of these problems is to be proactive with the developers who build the applications.
This is part of a Governance strategy. Governance is not just documentation or security, it's also a series of best practices, a means of communication, and verifications that the right paths are being taken and that nobody can slip through the cracks.
As an architect or a Kafka leader, it's our duty to protect the Kafka resources from people who don't have complete mastery of it yet (and most of them probably never will because it's not their job).
Conduktor Safeguard is part of our answer. Safeguard Interceptors intercepts Kafka requests or responses before hitting Kafka and can answer to any set of business or technical rules we wish to follow. It's therefore possible to enforce any kind of rules for all your developers so that you're proactively safeguarding Kafka, avoiding misconfigurations, bad decisions, badly formatted records, bad formats, and any other issues you might think of or have experiences.
A few examples to save you the hassle:
- Ensure topics creation requests adhere to specific requirements
- Ensure all records adhere to a schema in your Schema Registry
- Protect your cluster from connection storms
Security is expensive. And Kafka security is not adequate.#
Any enterprise need a strong security posture these days. IDP, authorization management, regulations, compliance, GDPR, data leakage, cyber-threats, phishing, suspicious activities detection, people turn-over... Apache Kafka is a powerful tool, but it's not designed for all the security constraints of our world. It's designed for performance and scalability. Security is a cross-cutting concern, and it's not easy to implement it correctly.
A flexible multi-clusters RBAC#
The security model of Kafka is based on a simple ACL model (who can do which action on what resource). It's basic and very often inadequate. Almost every single time, companies we're talking with create their own custom security system (RBAC) on top of Kafka liked to their internal authentication technology (their IDP) or synchronize them with an external source of truth (using our Kafka Security Manager).
Then they have to learn all the necessary tricks to do this, maintain something which is not their core business, integrate this into their GitOps system or extend it, then communicating about it, enforcing its use, documenting it, answering questions, and maintaining it. This often gets out of hand quickly, and the nice little GitOps operations soon become a bottleneck in the organization, so you need to hire more people and... read the previous paragraph again.
As you might expect, no need to reimplement all of that here! With Conduktor Gateway, we provide a full RBAC system for your existing Kafka infrastructure. Connect to your IDP/LDAP, setup your groups and permissions, you're good to go. This frees up your Ops team to focus on more interesting topics.
And the cherry on the cake: it also completely abstracts your Kafka providers custom security (Confluent Cloud, Aiven, etc.) so that you can use the same security model everywhere and define it only once.
We all love PII and GDPR compliance#
Globally, all companies are dealing with user information or other sensitive private information. If terms such as PII, GDPR, HIPPA, etc. ring a bell, you are in the right place.
Sensitive data access must be properly controlled and audited. These are data you must absolutely protect from unauthorized access, and you want to be able to prove it.
You probably already build applications to filter and project data into topics for particular applications, in order for them to only see a subset of the original data. Just by doing that, you have:
- duplicated data
- complicated your security model
- not protected your resources "at rest"
- increased the cost of your infrastructure
- added cognitive load to your developers
- created application dependencies
- created more maintenance work
- ...
If you are a little more advanced, you have probably implemented end-to-end encryption. This is a complex task, and it is cross-cutting (it has nothing to do with business processing, it is a cross-cutting concern). It is often poorly implemented and documented because developers are often uncomfortable with security — let's be honest.
If we take a look at this real-life scenario, this is what happens:
- You made a lot of effort: your encryption/decryption Java library works, yes!
- Another team uses Rust. Rust is amazing. So you build a new library in Rust to at least decrypt the data in your company
- Producer & Consumers versions are evolving (in Rust and Java). You must build a test matrix to validate the interoperability now, be sure nothing will break in the future
- Each team using your library needs to setup your library: it needs some tokens and secrets to access your KMS (to be able to encrypt/decrypt). Now you have a secret management issue and a KMS governance issue. Good luck
- You are now responsible for the security of the data even if you were just trying to help. You are now a security expert. Congrats
Looks familiar? (tell us!). You have entered a universe that you did not want in the first place, you are going to suffer, and for what?
Hopefully, you can just use our seamless end-to-end encryption in Conduktor Gateway. Free yourself from problems related to applications, no problem of KMS governance, no problem of secret management, no problem of interoperability, no problem of language, no problem of deployment: it's totally seamless for your developers, nothing to change.
Who is sending .pdf into Kafka?#
org.apache.kafka.common.errors.RecordTooLargeException is a common error in Kafka. It's a good thing, it's a safeguard from the Kafka infrastructure (and Ops) against too large messages. They could cause a lot of problems to Kafka itself and to the applications consuming such records. It's also a source of frustration for developers who don't understand why this is happening and why their application is stuck. (and possibly blocking the business, so very critical and really not easy to fix).
Suppose you're working in a bank:
- You need to send a PDF to Kafka. This PDF needs to move in Kafka because this is the way
- This PDF is 25 MB. You quickly see that Kafka rejects this message, as it is too big
- You must send this file to Kafka, what to do?
Chunking? No.#
You divide this file into multiple chunks: you send them individually to Kafka.
Since they are under the maximum allowed limit, they will be accepted, it's up to the consumer to read the pieces and reorder them to create the original file (if you think this a terrible solution, and that you've lost time, you're probably right).
Claim Check Pattern? No.#
You use the Claim Check Pattern: you send a reference to Kafka (a simple string) to the file that you stored in S3 (/mybucket/my.pdf).
An important constraint to consider: producers and consumers must have access to S3 with some login/password. Another security and governance problem.
What happens if something must change somewhere? A bucket, a path, a service account, a password? It's a very brittle path full of problems.
Conduktor Cold Storage? Yes!#
Thanks to the Cold Storage Interceptor, Conduktor Gateway makes this problem a no-brainer: it will intercept the message and carry out the entire Claim Check Pattern strategy automatically, totally seamlessly for the producers and consumers.
The producer only has to send a file of arbitrary size, and the consumers fetch the records as usual. The Gateway takes care of dancing with S3 and Kafka: it's totally seamless and invisible for the Kafka clients, as well as very secure and manageable because only the Gateway needs access to S3 and its secrets.
You have reduced technical debt and governance problems to access S3, simplified usage, and above all, prevented adding large files to Kafka that had consequences on storage and the health of the cluster.
- If you want to send 25MB-records into Kafka quickly with Conduktor Gateway, contact us, we'll be happy to help you
- If you want to setup your Kafka cluster to accept 25MB-records without using Gateway, take a coffee and read our guide: https://www.conduktor.io/kafka/how-to-send-large-messages-in-apache-kafka/
Conclusion#
We have other surprises in store for you, but this article is already too long! We hope you enjoyed this article and that it gave you some ideas for your Kafka infrastructure. Really, contact us if you want to discuss your use cases. We want to build out-of-the-box and innovative solutions for enterprises using Apache Kafka, so we are very interested in your feedback.
You can download the open-source version of Gateway from our Marketplace and start using our Interceptors or build your own!
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.