Kafka Cost Allocation & Chargeback
See the bill. Place it where it belongs.
Kafka spend keeps growing because no one outside the platform team can act on it. Conduktor attributes cost to the applications and teams that drive it, then gives those owners the visibility and the controls to act at the source.
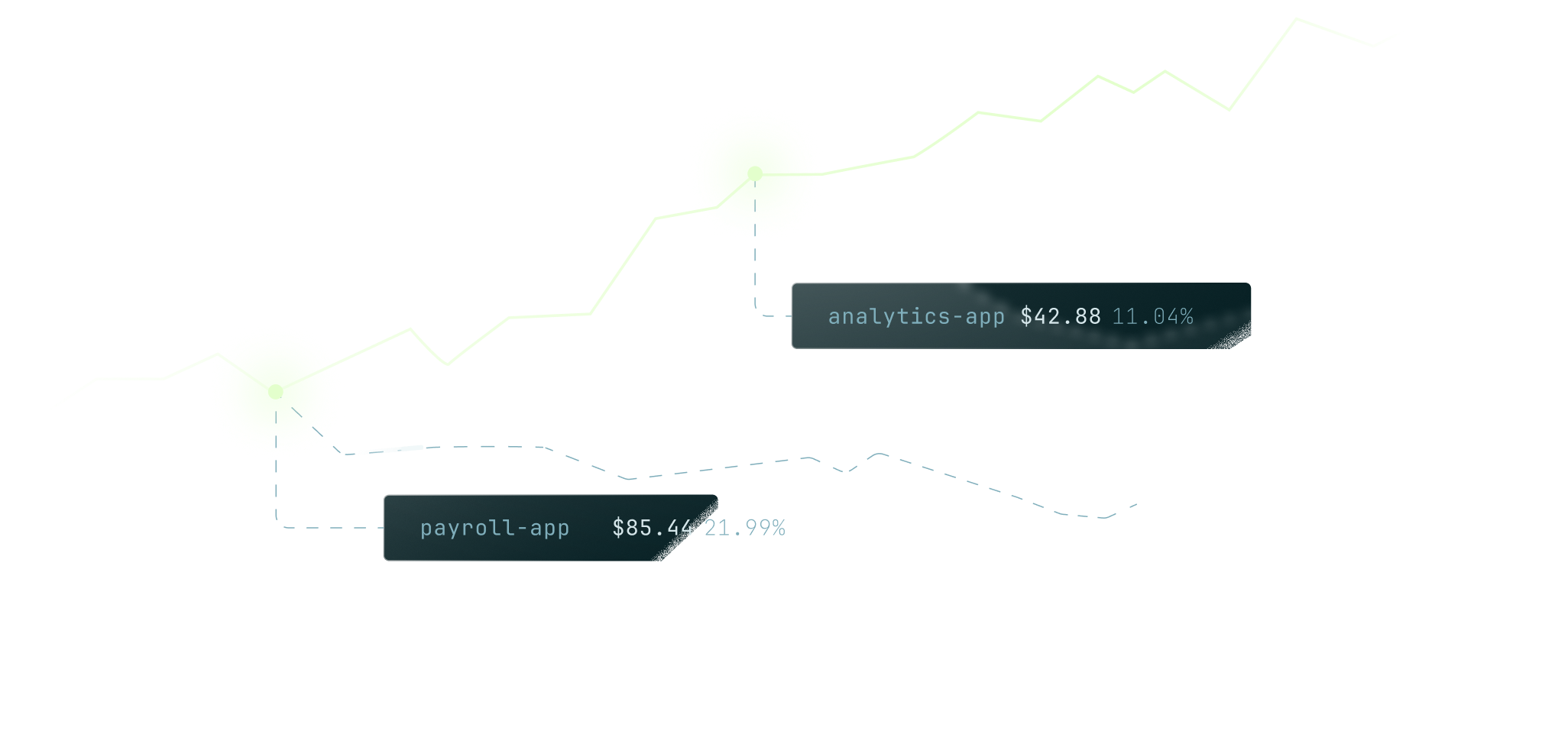
Visibility on one side, authority on the other
The platform team can see the waste but cannot act on resources other teams created. The teams that can act cannot see what their choices cost. Kafka gives you neither a per-team view of spend nor a way to hand owners the controls to fix it, so cost grows by accretion and central cleanup never sticks.
Service accounts show usage, not ownership
Bytes in and out tell you how much data moved, never which team, project, or environment it belongs to. Finance cannot budget against raw technical identifiers.
Cleanup is a coordination problem
A platform team finds thousands of empty topics and cannot delete one of them, because they do not own them and cannot confirm which are abandoned and which are waiting on a monthly consumer.
Cost is shaped like the cluster, not the org
The bill rolls up by broker and partition, not by the team or product line that generated it, so no one recognizes their own share.
No lever for the people with context
The teams that know whether a topic is still needed have no view of its cost and no safe way to retire or right-size it.
Why cost cleanup stalls: three stages of ownership
Most organizations sit somewhere on the same progression. What changes across the stages is not who pays the bill, but whether the people positioned to act have the visibility and the controls to do it effectively.
| Stage 1 | Stage 2 | Stage 3 | |
|---|---|---|---|
| Who pays the bill | Platform team carries it alone | Allocated as a flat share across teams | Teams pay in proportion to actual usage |
| Who can act on cost | Platform team alone, without levers on resources they don't own | Teams now pay, but coarse data and no expertise to tell value from waste | Teams act on their share, with platform-team expertise on what matters |
| What enables the stage | Default starting point | A model for dividing the bill, plus coarse usage views | Proportional attribution, self-service tooling, guardrails, and a working partnership |
| Where it breaks | Accountability without the levers | Responsibility shifted, capability didn't follow | Requires the prior structures to be working |
Stage 3 is where behavior actually changes, and it depends on two things landing together: spend attributed to the teams that own it, and those teams handed the controls to act. Read the full breakdown →
See the spend
Attribution and waste detection are the foundation. Before any cleanup or accountability conversation, the spend has to map to how the business is structured, and the waste has to be visible to the people who own it.
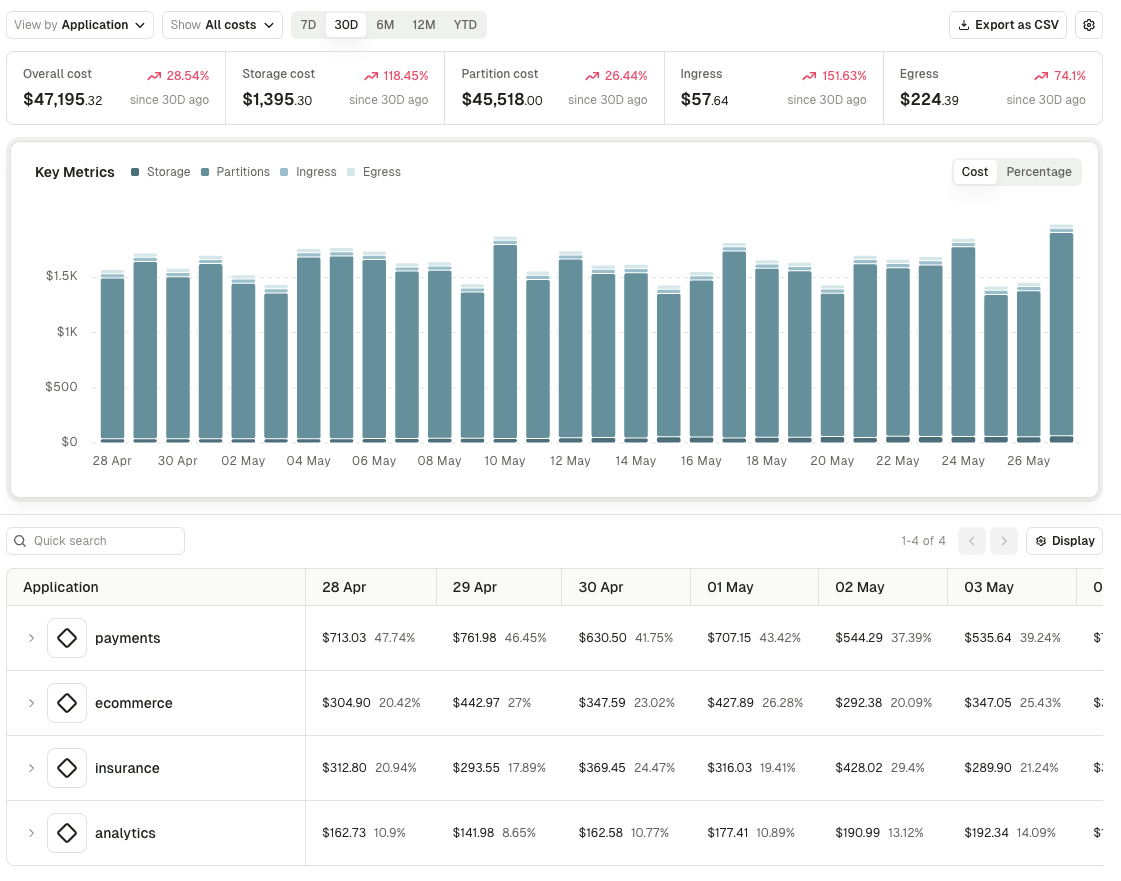
Map Kafka spend to teams with Chargeback
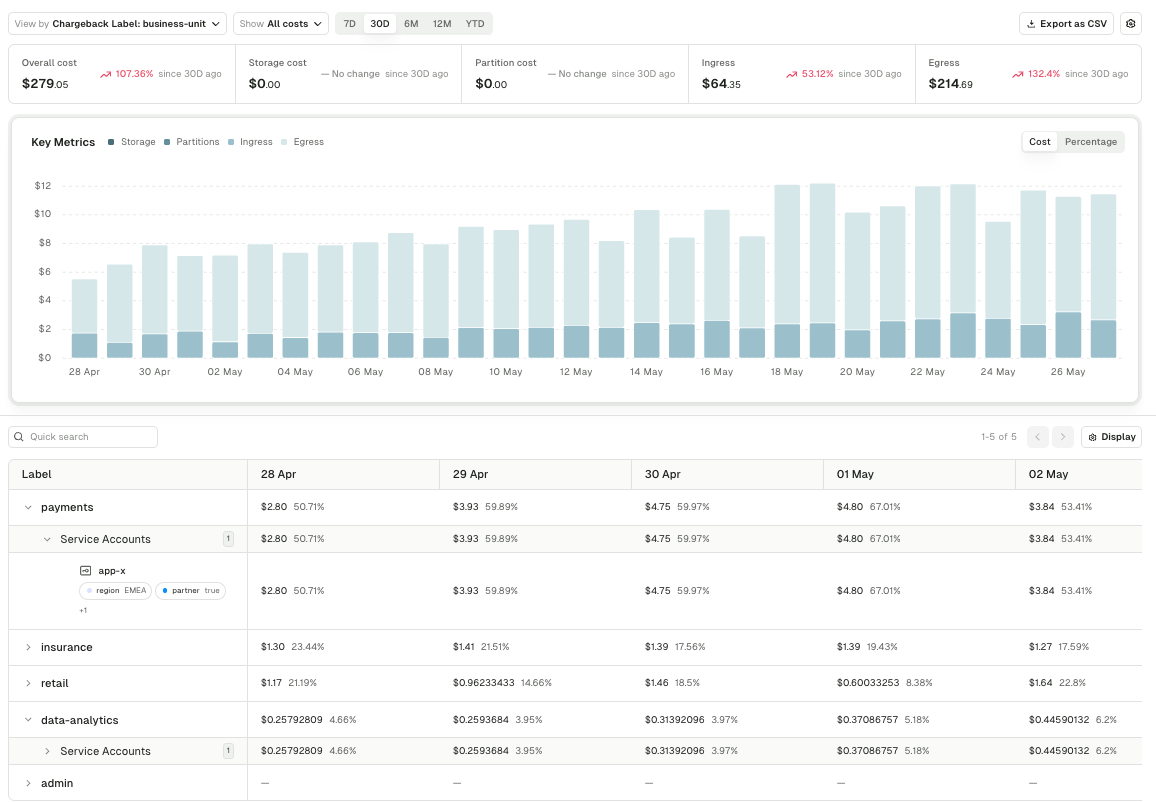
Chargeback turns raw consumption into an accounting view of spend. Costs roll up by application, service account, or any label, so reports line up with how the business is structured rather than how the infrastructure is shaped.
- Four cost axes: storage, partitions, ingress, and egress, each with configurable unit costs tied to your actual contract terms
- Group by application, service account, or label (team, department, environment, business unit), with drill-down into the topics and accounts behind every line
- Confluent Cloud direct: pulls ingress and egress from the Confluent Metrics API and maps anonymous service accounts back to the teams that own them, with no Conduktor Gateway required
- Export to CSV so finance can budget and forecast against numbers that match the org chart
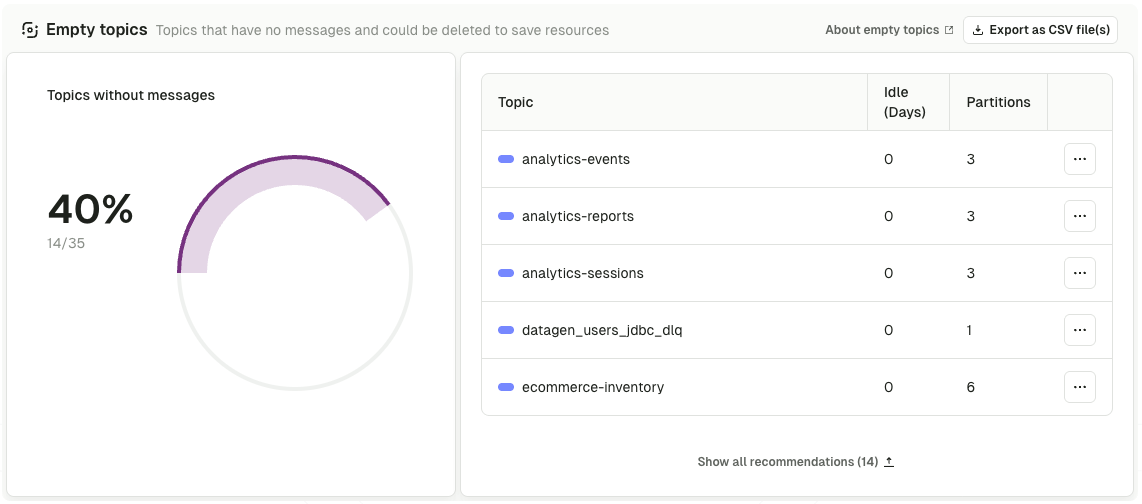
Surface the waste behind the bill
Attribution tells you who owns the spend. Insights tells you which of it is waste. The Cost Control view finds the topics you are paying for that you should not be, and ranks them so cleanup runs by impact, not by cluster.
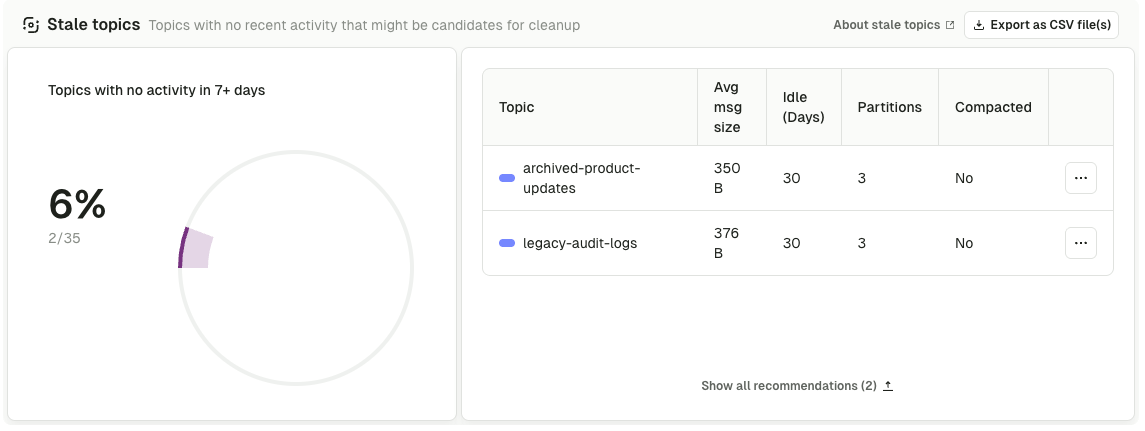
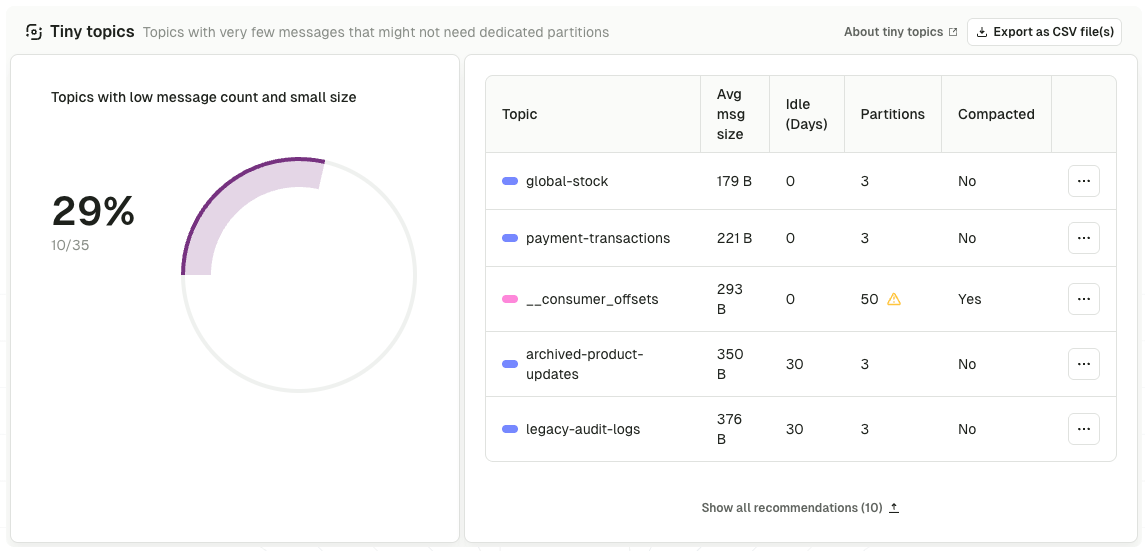
- Empty, stale, and tiny topics surfaced automatically, with idle time and partition count on each
- Ranked by storage, partitions, and throughput, with the underlying pattern flagged so the biggest offenders rise to the top
- Filter by application, topic prefix, or cluster so cleanup scopes to the topics that matter
Hand owners the controls
Visibility on its own does not change behavior. The shift to Stage 3 happens when the teams that can see their own bill also get the controls to act on it, without routing every change through a platform admin.
Give every team its own bill, and the means to act
Cost pushed centrally never sticks. Conduktor scopes both the visibility and the controls to the owning team, so each one sees its own consumption and can act at the source rather than waiting on the platform team.
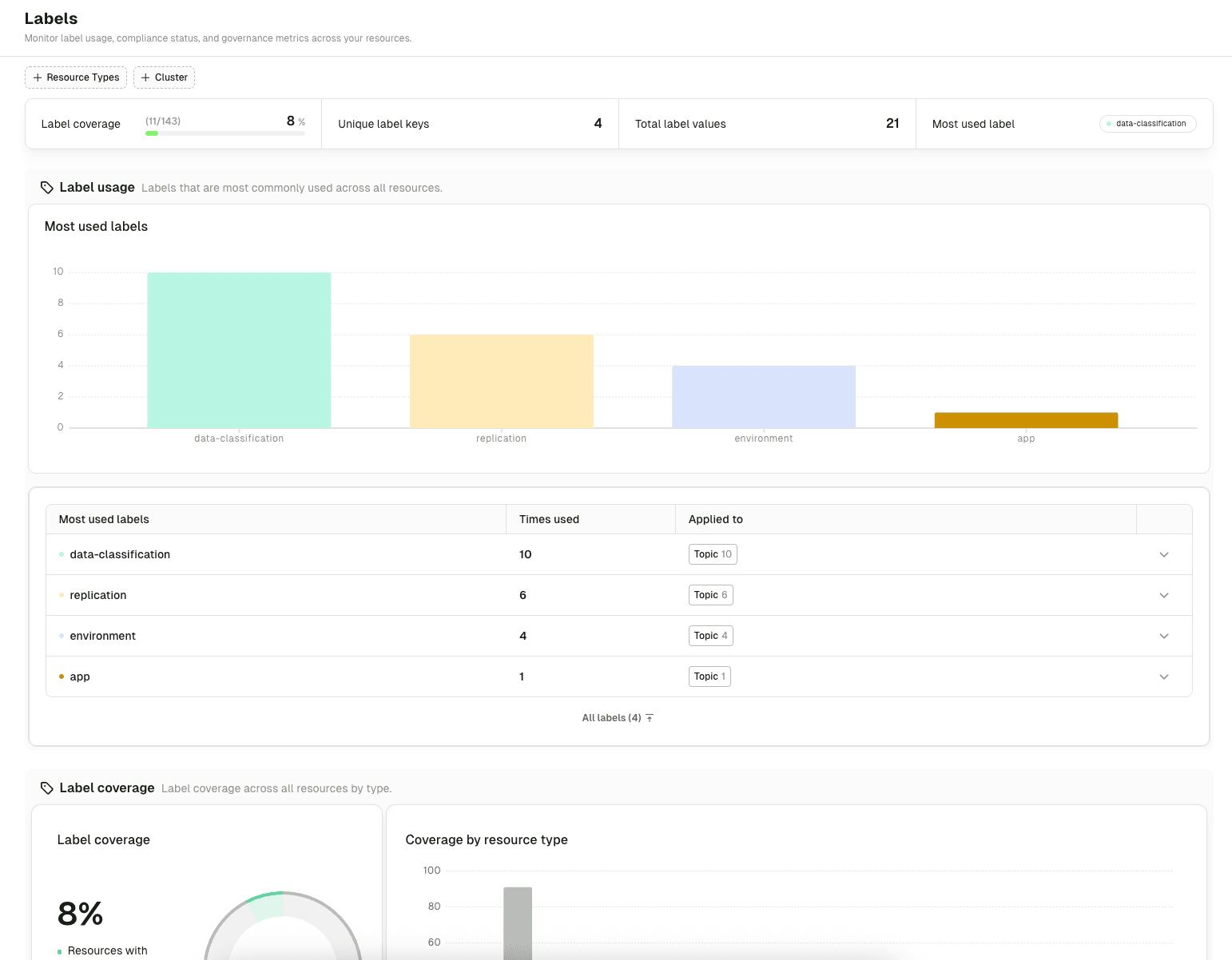
- RBAC-aware Insights and Chargeback: developers, SREs, and team leads see the health and cost of the topics they own, not just admins
- Delegated permissions through ApplicationGroups: hand specific responsibilities, like requesting access, approving requests, and managing service accounts or API keys, to the people who should hold them
- Self-service with guardrails: owners retire, right-size, and provision their own resources within bounds the platform team sets at creation time
- Ownership required on every new resource, so orphan topics are blocked by construction rather than chased down later
What changes when owners can see their own bill
Attribution and delegated controls move an estate from central firefighting to owners acting at the source. These are the typical shifts we measure once teams can see and act on their own consumption.
Cleanup outreach drops from roughly 1.5 hours per project to under 15 minutes, because teams arrive already aware of their own consumption from the chargeback view.
When teams see their own bill, steady-state staleness drops 60 to 80 percent across the estates we measure.
Confluent Cloud, Aiven, MSK, and self-managed, mapped to teams in one view rather than one cluster at a time.
Support priced as a percentage of platform spend shrinks automatically as the infrastructure it bills against shrinks, with no renegotiation.
How does cost attribution work across multiple clusters and providers?
Conduktor connects to every cluster regardless of provider and tracks consumption at the application level. Conduktor Gateway meters bytes in and out per service account, topic, and virtual cluster, while for Confluent Cloud the figures come straight from the Confluent Metrics API. Console aggregates all of it so cost breakdowns surface by team, application, or business label across the entire estate, not one cluster at a time.
Do I need Conduktor Gateway for Chargeback?
No. For Confluent Cloud, Chargeback pulls ingress and egress from the Confluent Metrics API and joins them with Console's storage and partition data. Conduktor Gateway adds the same ingress and egress metering for other cluster types. Storage and partition costs are available for every cluster either way.
Why does attribution change team behavior when central cleanup does not?
Central cleanup stalls because the platform team has visibility without authority and the project teams have authority without visibility. Putting each team's own bill in front of it closes that gap: the team that can retire a topic is now the team that can see what it costs. Pairing that with delegated controls means they can act without filing a ticket, which is what turns awareness into change.
How is this different from the Kafka Cost Optimization page?
Cost allocation and chargeback is about seeing and owning the spend. Kafka cost optimization is about cutting it, with levers like capacity pooling, topic views, and creation-time guardrails. Most teams start here, because attribution and ownership make every other lever land.
Does this work with managed Kafka?
Yes. Insights and Chargeback connect to every cluster regardless of provider, and managed-Kafka customers often see proportionally larger gains because per-unit infrastructure cost is higher and the attribution gap is wider.
Ready to see where your Kafka bill comes from?
Book a cost analysis with our field engineering team. We will map your current ownership model, attribute the spend to the teams behind it, and show where the gaps are before any cleanup begins.