
Apache Kafka has become the go-to choice for building distributed streaming platforms and real-time data pipelines.
As a developer working with Kafka, it’s crucial to understand some core concepts and best practices to ensure applications work well and data processing pipelines are efficient and reliable.
We will explore why it’s essential to design topics and optimize partition sizing, ensure data serialization efficiency, handle tombstones, and a few more tricky aspects:
-
Avoiding too many or too few partitions
-
The puzzle of the data format
-
Avoid the dual-write problem when writing to downstream systems
-
Deleting records in Kafka (via tombstones)
-
Tune Kafka producers to improve performance and reliability
1. Avoiding too many or too few partitions#
One of the key decisions you’ll make as a Kafka developer is determining the appropriate partition count of a topic.
Careful consideration must be given to factors such as:
-
Data volume
-
Throughput requirements
-
Data distribution
Too many or too few partitions can lead to uneven data distribution, scalability issues, and performance bottlenecks. When you have too few partitions in Kafka, it can lead to the following problems:
-
Limited Parallelism: Kafka achieves high throughput and scalability by allowing multiple consumers to process messages in parallel across partitions. With too few partitions, the available parallelism decreases as fewer partitions distribute the load among consumers. This can result in slower message processing and reduced throughput.
-
Inefficient Resource Utilization: Kafka partitions are distributed across broker nodes, and each broker can handle a specific load. When too few partitions exist, the available broker resources might be underutilized since the load cannot be evenly distributed. This can lead to inefficient resource allocation and suboptimal performance.
-
Limited Scalability: Kafka’s partitioning mechanism allows you to scale your consumer group horizontally by adding more consumer instances. However, with too few partitions, you might reach the scalability limits of your consumer group since the consumers can’t effectively utilize the available resources.
Having too many partitions can also present challenges:
-
Increased Overhead: Each partition requires metadata overhead, such as maintaining offset information and replication status. When there are excessive partitions, this overhead can become significant and consume additional storage and memory resources.
-
Higher Latency: Kafka maintains message ordering within a partition, allowing sequential processing within that partition. However, having too many partitions can increase the overall processing and coordination overhead, potentially leading to higher message latency.
-
Management Complexity: Each partition requires resources and administrative effort to manage and monitor. With excessive partitions, effectively monitoring and maintaining the Kafka cluster becomes more challenging, potentially increasing operational complexity.
It’s essential to strike a balance when determining the number of partitions in Apache Kafka. It depends on various factors, such as your Kafka cluster's expected throughput, consumer scalability, and resource capacity. Monitoring and optimizing the partition count is recommended based on your application's specific requirements and workload characteristics.
Conduktor enforces topic limits at the creation time, preventing too many and too few partitions, thus reducing infrastructure costs in the long term.
2. The puzzle of the data format#
Serialization and deserialization (“Serde”) play a crucial role in Apache Kafka by allowing data to be efficiently (or not!) transferred between producers and consumers.
While Kafka sees the messages produced, it just sees an opaque sequence of bytes, nothing else. It is up to your client applications to decide how to read these data in a format that will make them efficient and maintainable over time.
Some important considerations:
-
Space & Processing time? Select an efficient serialization format in terms of both space and processing time. Standard options include JSON, Avro, Protocol Buffers (Protobuf), and Apache Kafka’s native serialization (byte arrays). Consider the specific requirements of your application, such as data size, schema evolution, and compatibility with other systems.
-
Ensure Compatibility between clients: The serialization and deserialization libraries or frameworks producers and consumers must be compatible (consumers must be able to read what the producers are sending, no matter their language or framework). They should support the same serialization format and version. Ensure backward and forward compatibility to handle evolving schemas gracefully without breaking your Kafka workflows.
-
Carefully think about Schema Evolution: Plan for schema evolution to accommodate changes in data structures over time (new fields, fields removed, default value changed, etc.). You can manage schemas and enforce compatibility checks with Conduktor. Understand the compatibility strategies like backward compatibility (old consumers can read new messages) and forward compatibility (new consumers can read old messages).
-
Optimize for Performance: Efficient serialization and deserialization can significantly impact the performance of your Kafka applications. Consider factors like serialization overhead, compression, and network latency. Optimize the serialization process using lightweight libraries or binary formats when possible.
Be mindful of data size during serialization. We recommend using compact serialization formats like Avro or Protobuf to reduce message size and network bandwidth, combined with compression options, such as Kafka’s built-in compression codecs (e.g., GZIP, Snappy), to further reduce the message payload size.
-
SerDe Error Handling: Implement robust error-handling mechanisms during serialization and deserialization. Handle exceptions and validation errors gracefully, and consider using error codes or structured error messages for effective debugging and troubleshooting. For example, a good practice to deal with malformed messages is to route them to a dead letter topic (DLT) so they can be recovered and fixed later.
-
Use Schema Validation: Apply schema validation during deserialization to ensure the integrity and compatibility of incoming messages. Validate the message structure, required fields, and data types against the expected schema to avoid processing corrupt or invalid data. Safeguard can help.
Also, during the development, we should always test serialization and deserialization processes in your Kafka applications. Unit tests are a good way to ensure the correctness of serialization and deserialization code. Validate the behavior of your application with sample data and different message scenarios to ensure data integrity and proper handling of serialization-related errors.
The best practice is to use a schema registry whenever possible while dealing with SerDe in your client applications. As a developer, you will find it helpful to use something like Conduktor compatible with all schema registries, including Confluent, AWS Glue, Aiven, etc.
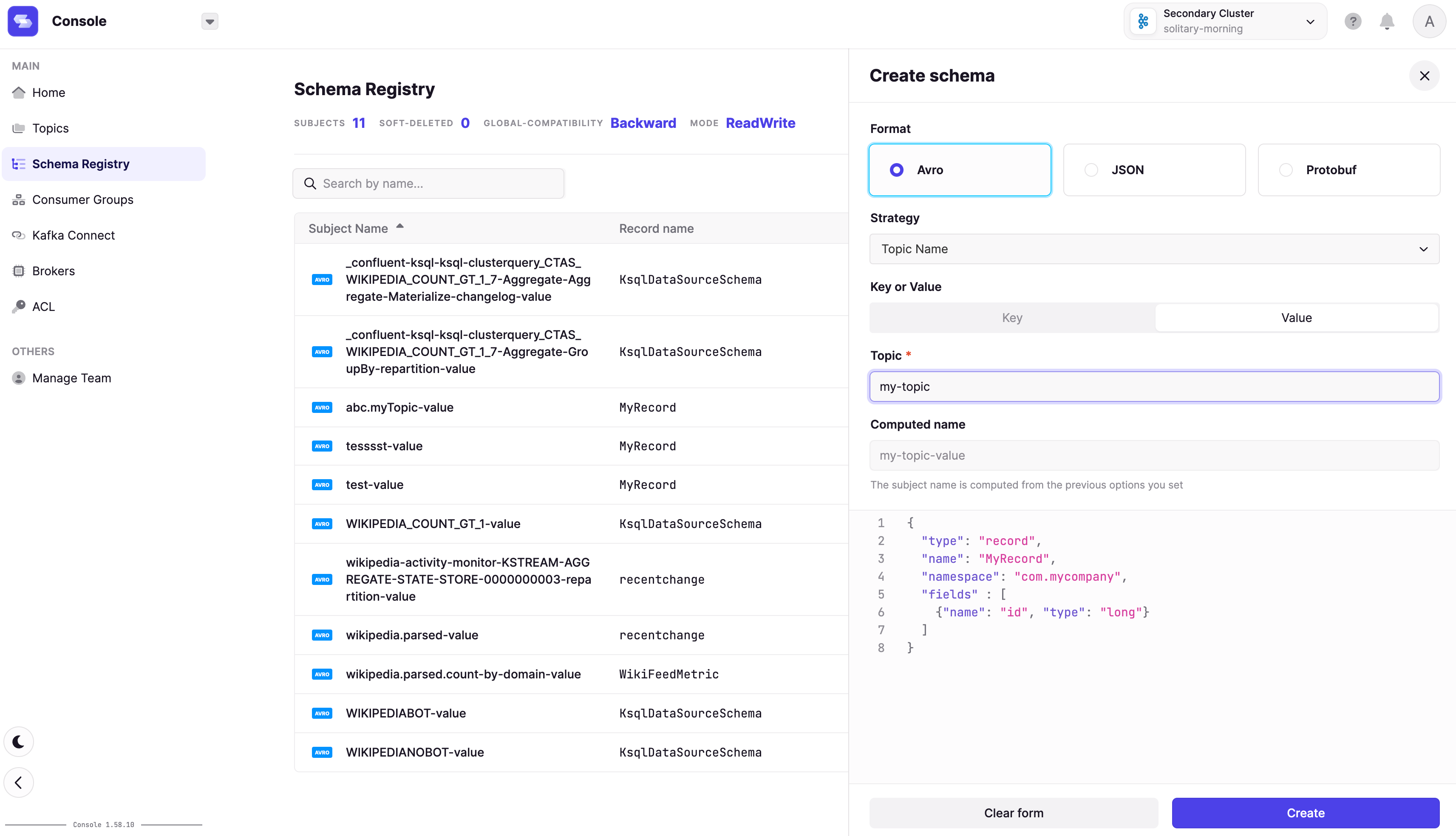
3. Avoid the dual-write problem when writing to downstream systems#
In distributed, event-driven applications, dual writes can cause problems. This happens when a service handling a command attempts to change the state in the database and publish a message to Kafka to notify other systems. The idea is that either both or none shall be done. If the database transaction fails, the message to Kafka must not be published to keep the data consistent in both systems.
To mitigate this issue, we can use the Transactional Outbox pattern, which helps achieve atomicity between Kafka and the database. The pattern involves capturing the changes made to the source table as events and writing them to a dedicated table called the Outbox within a transactional context. These events represent the intended writes to the downstream systems, waiting to be published in Kafka soon. Then, a separate process polls the Outbox table and publishes them to Kafka. This pattern guarantees that all the intended writes succeed or none take effect, maintaining data consistency.

Figure 02 — Sequence of operation in the transactional outbox pattern
A Change Data Capture (CDC) mechanism can be employed to implement the transactional outbox pattern. CDC tools, such as Debezium, capture data changes from a database and produce them as Kafka events. By integrating Debezium with the transactional outbox pattern, you can automatically generate events representing the changes in the database, ensuring that both Kafka and the downstream systems remain in sync.
Stephane actively worked on this problem years ago; it can get more tricky when you want to ensure high-availability situations: https://www.sderosiaux.com/articles/2020/01/06/learnings-from-using-kafka-connect-debezium-postgresql/#double-replication
Again, tooling is critical to get right to help us troubleshoot and visualize what’s going on, as well as auto-restart the failing connectors when it’s 3am and everybody sleeps, etc.
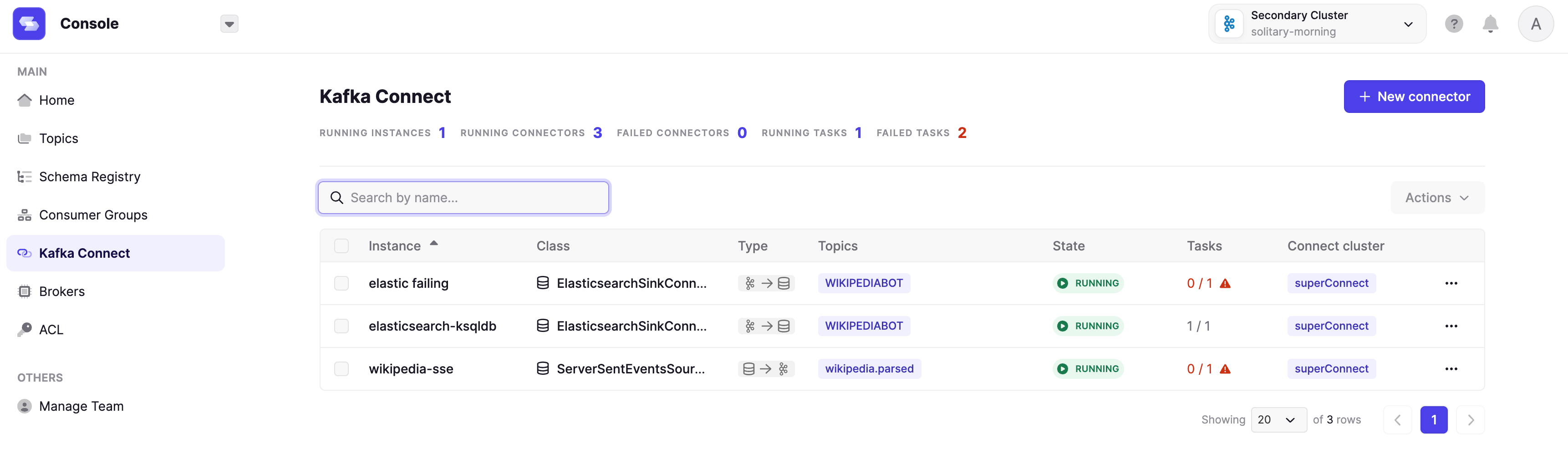
4. Deleting records in Kafka (via tombstones)#
Message compaction in Apache Kafka allows you to retain only the latest value for each key in a topic where cleanup.policy=compact, effectively cleaning up redundant data.
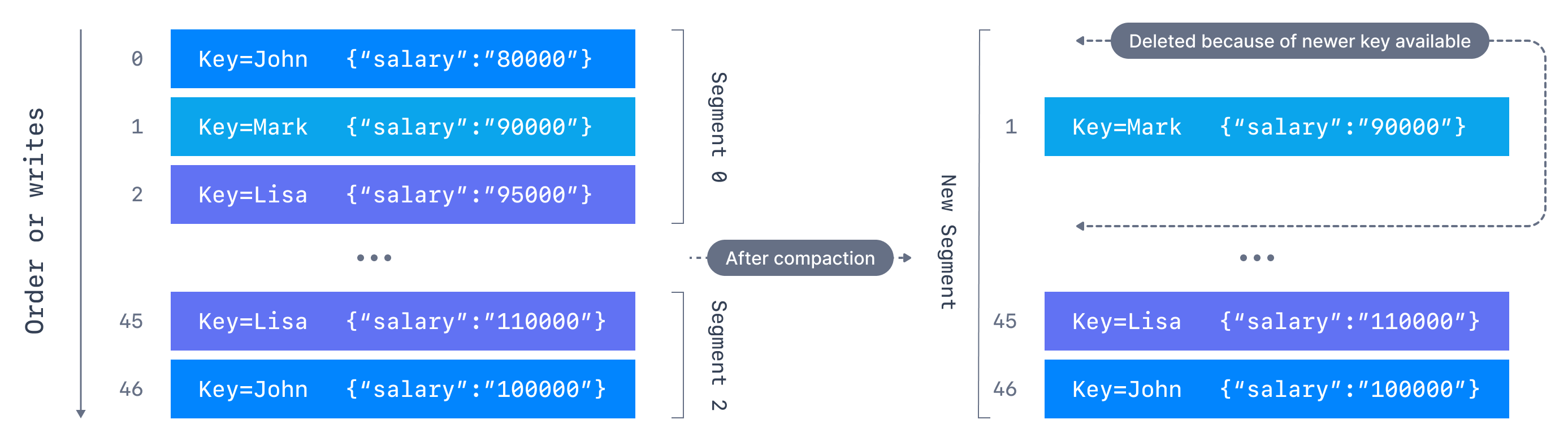
- A message with a key and a null payload will be treated as a delete from the log. Such a record is sometimes referred to as a tombstone. This delete marker will cause any prior message with that key to be removed (as would any new message with that key), but delete markers are special in that they will themselves be cleaned out of the log after a period to free up space.
When a consumer encounters a tombstone, this could signify the deletion of the corresponding key in the system (let’s say “user 1234 must be removed”). To ensure the correct interpretation of tombstones, your consumer applications should be designed to handle them appropriately by handling these null values instead of failing with a NullPointerException.
What can we do when our application receives a value=null?
-
Remove corresponding data from our internal stores or cache (let’s think Kafka Streams): we remove all occurrences for this key.
-
Communicating to downstream systems that something must be removed by calling their HTTP API, for instance (because they are not using Kafka)
The minimum retention time of Kafka tombstones is configurable using the min.cleanable.dirty.ratio configuration. It determines the duration a tombstone must be retained in the log before it becomes eligible for compaction (and removal) by Kafka. Ensuring an appropriate minimum retention time allows sufficient time for all consumers to process the tombstone and guarantees data consistency across the ecosystem.
You can check out Kafka Options Explorer for more information on various configuration options and documentation about compaction.
5. Tune Kafka producers to improve performance and reliability#
Optimizing the configuration of Kafka producers is essential for achieving good performance and reliability in data pipelines. Throughput can be increased, latency minimized, and resources be efficiently utilized “just” by fine-tuning various aspects of the data producer.
-
Produce asynchronous: Kafka producers offer a sync & asynchronous mode of sending messages. If you’re using kafkaFuture.get(), you’re probably not using it properly. Using asynchronous is extremely recommended to improve the throughput and performance significantly. By sending messages asynchronously, the producer can continue processing additional messages without waiting for each individual send() operation to complete.
-
Batching and compression: Batching multiple messages together before sending them to Kafka effectively reduces overhead and improves efficiency. It reduces the number of network roundtrips and improves overall throughput. It is configurable using batch.size and linger.ms mostly. Additionally, enabling compression.type to reduce significantly the amount of data transferred over the network is one of the easiest seamless ways to improve performance and reduce storage costs.
-
Monitor and handle backpressure: Backpressure can occur when the Kafka brokers or downstream systems cannot handle the incoming message rate from producers. Monitoring and handling backpressure effectively can be helpful to prevent overwhelming the system or consuming excessive memory. Implement mechanisms to track the response times of Kafka brokers and adjust the producer’s send rate accordingly. This ensures that the producer’s rate aligns with the system's capacity, preventing potential bottlenecks.
-
Configure appropriate buffer sizes and implement flow control: Kafka producers use internal buffers to hold messages before sending them to the brokers. Configuring an appropriate buffer size (buffer.memory) ensures efficient memory utilization and prevents excessive memory consumption.
Additionally, implementing flow control mechanisms, such as pausing/resuming partitions (see how Alpakka applies backpressure with Kafka 2.4+), the max.in.flight.requests.per.connection setting helps regulate the rate of outgoing messages, preventing the producer from overwhelming the Kafka brokers. Carefully tuning these parameters based on the expected message rates and system capacity ensures optimal performance and reliability.
Conduktor can help enforce Kafka producer configuration and Kafka consumer configuration, preventing heterogeneous configurations in your organization while being totally language-agnostic and not coding anything. How awesome is that?
Conclusion#
Building robust and performant Kafka applications needs understanding and implementing best practices related to topic design, data serialization, dual-write problems, tombstone handling, and producer tuning.
It’s challenging as your Kafka ecosystem often grows in complexity. This is where Conduktor kicks in by assisting you in implementing and enforcing best practices to protect your Kafka cluster and your developers. This saves time on troubleshooting, avoid creating a mess by preventing it from happening in the first pace, and improve your overall Kafka reliability and efficiency.

—
We hope you enjoyed this article and that it gave you some ideas for your Kafka infrastructure. Contact us if you want to discuss your use cases. We are Kafka experts and want to build out-of-the-box and innovative solutions for enterprises using Apache Kafka, so we are very interested in your feedback.
You can also download the open-source version of Conduktor Gateway and browse our marketplace to see all the supported features.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.