
- Reaching Kafka across VPCs is an addressing problem, not a networking one. Every broker address the cluster advertises has to be reachable from where the client sits.
- VPC peering doesn't scale. Each new client network is another change on the cluster's VPC, and managed Kafka caps how many you get.
- Transit gateways and per-broker load balancers work a layer too low. They move packets; they don't fix the addresses brokers hand back.
- A Kafka-aware proxy rewrites those addresses. Conduktor Gateway sits in a hub VPC, so the cluster keeps a single attachment no matter how many networks reach in.
- Gateway Community does it for free. One quickstart reproduces the whole setup on one machine.
Your Kafka cluster lives in one VPC. Your clients probably don't. A new team in another account, a partner who needs read access, a workload in another region or another cloud: every one of them needs a path to the cluster.
The usual practice is to peer the networks together. But this does not scale: editing the same VPC over time and adding more and more route-table and security-group entries raises questions about why the cluster's network now has several dozen routes, not to mention the tangle of peerings, route tables, and exceptions, all landing on the one VPC you least want to keep touching.
This is not a networking problem. Reaching Kafka across VPCs is an addressing problem, and that's why VPC peering, transit gateways, or an LB per broker aren't the solution.
This post is about that one thing: reachability.
What a client does when it connects to Kafka
Outside of Kafka, to cross a network boundary you put an LB in front, assign it one address, and point clients at it. Done.
Kafka works differently. A client connects in two stages:
- Bootstrap. The client connects to any broker and asks one question: who's in this cluster?
- Direct connection. A broker answers with metadata, a list of every broker, each named by its own
advertised.listenersaddress. The client then opens direct connections to specific brokers at those addresses: the leader for each partition it writes or reads (or, with follower fetching, the nearest replica; KIP-392, Kafka 2.4+).
This is why a normal LB doesn't work with Kafka: one shared address in front of the cluster isn't enough, because the client has to resolve and route to every broker's advertised address exactly as the cluster returns it. If a broker advertises broker-1.cluster.internal:9092 (a private name that only resolves inside the cluster's VPC), a client in another network can connect to the bootstrap but fails the moment it connects to a broker using its advertised address.
🚫 "There's a route between the networks, so the client can reach the cluster."
The issue is assuming a network path is enough with Kafka; it isn't. A network route between the two isn't the same as Kafka reachability: the client still has to resolve and route to each broker's advertised address from where it sits. (Misconfigured advertised listeners are the classic version of this mistake.)
Couldn't the broker just advertise an address the remote client can reach? Yes and no. Brokers support multiple listeners, say one internal (private IPs) and one external (resolvable outside). But every listener is another port to open on every broker, and managed Kafka usually won't let you change them. Listeners don't scale to many independent networks across accounts and clouds, which is exactly the case here.
Why peering collapses as clients grow
VPC peering is great for connecting two VPCs. Past two, here be dragons:
- Point-to-point and non-transitive. Peering A and B each to the cluster doesn't let A talk to B. Every new client network needs its own peering directly into the cluster's VPC.
- The cluster's VPC turns into a hub. Ten client networks means ten peerings, ten route-table entries, and ten security-group conversations on a VPC that was never meant to be one.
- CIDR coordination. Peered VPCs can't have overlapping ranges, so every team has to coordinate address space.
- Managed Kafka caps it. Confluent Cloud, MSK, and Aiven limit how many peerings or PrivateLink attachments you get, and they don't let you rewrite broker listeners.
The big problem: every new client forces another change onto the cluster's VPC.
The proxy rewrites the addresses
A Kafka-aware proxy sits in the connection path, understands the protocol instead of just shuffling packets, and rewrites the broker addresses in the metadata response before the client ever sees them.
That's Conduktor Gateway. When a broker advertises kafka-internal:9092, the Gateway rewrites that address in the metadata response to its own, one the client can reach. Because clients connect to specific brokers (the partition leaders), the Gateway maps each broker to its own port, so traffic routes deterministically to the right broker behind it.
Credentials don't change for clients:
- They present the same SASL credentials they already have.
- They are forwarded to the broker, which still authenticates them as usual.
- Kafka ACLs or Confluent RBAC still decide what each client can do.
The proxy is stateless: it stores no credentials and adds no new auth model. From the client's side, the only change is one line:
# before: the client points straight at a broker it can't actually reach
bootstrap.servers=broker-1.cluster.internal:9092
# after: it points at the proxy, which hands back addresses it can
bootstrap.servers=conduktor-gateway.hub:9092In a real deployment, clients reach the Gateway through DNS: a single wildcard record points every per-broker hostname at one LB in front of the Gateway, TLS passes straight through it at layer 4 and terminates at the Gateway, and the Gateway routes each connection to the right Kafka broker behind it.
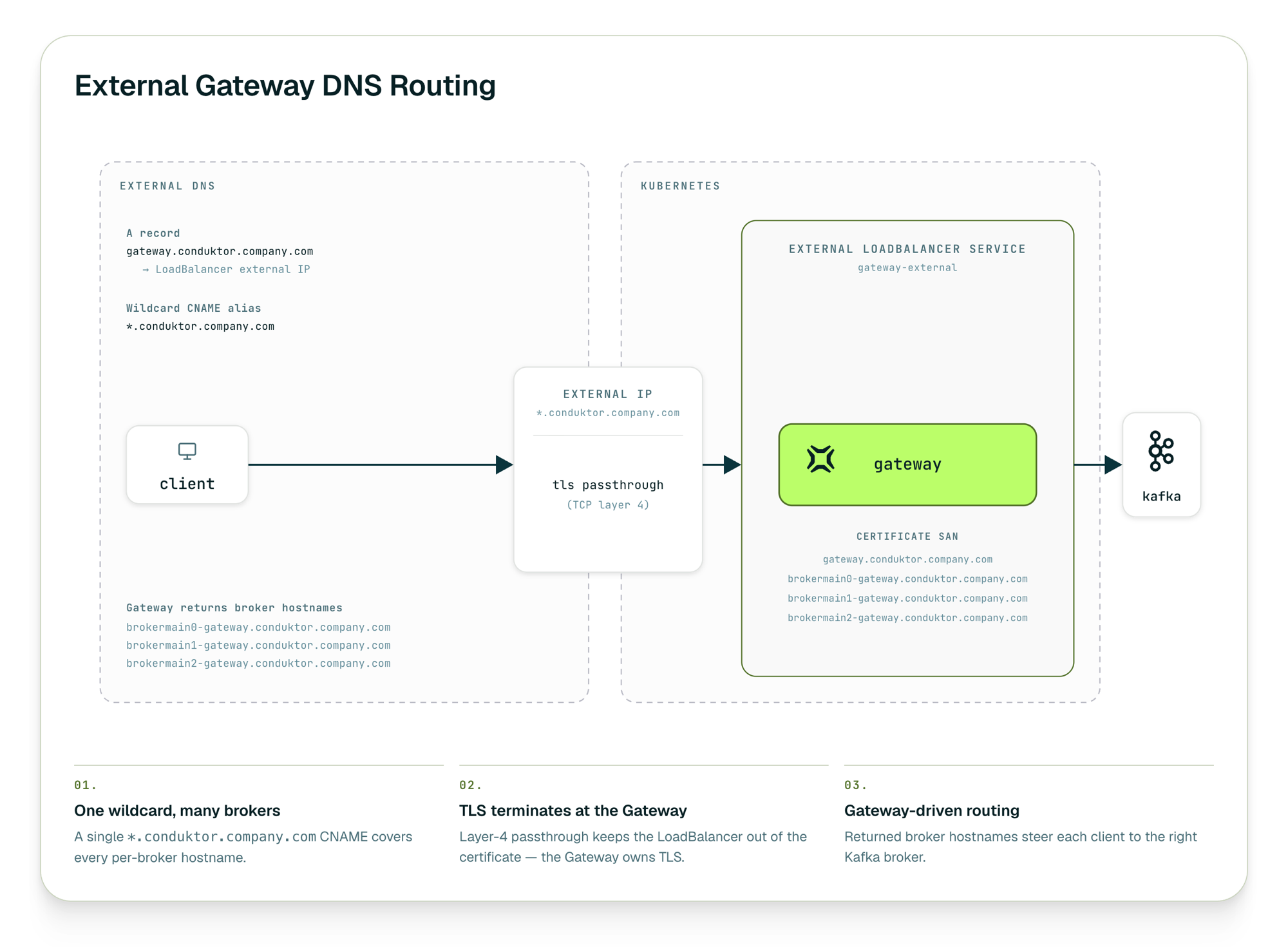
The Gateway is deployed in its own hub VPC, with peerings (or PrivateLink attachments) landing on the hub, never directly between a client and the cluster. The cluster keeps a single attachment no matter how many client networks reach in. New networks attach to the hub, and the cluster's listeners are never touched.
The Gateway isn't a substitute for a route: you still need network connectivity between the hub and each VPC. What it removes are the per-client peerings into the cluster, the broker reconfiguration, and the requirement that every advertised address be reachable from every client.
What about a transit gateway, or an LB per broker?
A cloud transit gateway. It's one hub that many VPCs attach to for any-to-any IP connectivity. But it operates at layer 3, moving IP packets with no awareness of Kafka, so every Kafka-specific problem is still there. It doesn't change what brokers advertise, so you're back to sharing private hosted zones across accounts. Overlapping CIDRs still break it without NAT. And it's confined to a single cloud provider, so a VPC in another cloud is out, and on managed Kafka you still can't touch the listeners.
A load balancer per broker. Because clients connect to specific brokers (partition leaders), you can't round-robin one balancer across the cluster. You need one NLB (or target group, or PrivateLink endpoint) per broker, plus advertised.listeners reconfigured: N pieces of plumbing to keep in sync, each with its own port, DNS record, and TLS SAN. Scaling or replacing a broker churns the mapping and forces a rolling restart. And on managed Kafka you usually can't set advertised listeners at all, so it's off the table before you start.
Side by side:
| Approach | Works at | Solves the advertised-address problem? | Works on managed Kafka? | Cross-cloud / on-prem? |
|---|---|---|---|---|
| VPC peering | L3 (IP) | No, every advertised address still has to resolve and route | Capped by provider peering limits | No, same provider |
| Transit gateway | L3 (IP) | No | No, can't change listeners | On-prem yes, another cloud no |
| NLB / PrivateLink per broker | L4 (TCP) | Only if you reconfigure advertised.listeners yourself | Usually not, listeners are locked | On-prem yes, another cloud no, per endpoint |
| Kafka-aware proxy | Kafka protocol (L7) | Yes, rewrites them automatically | Yes | Yes |
Reproduce it with the Docker quickstart
The Gateway Community quickstart reproduces this scenario: a Kafka cluster in a private Docker network the clients can't reach, two consumers in two separate "VPC" networks, and the Gateway as the only container joined to all three:
bash <(curl -fsSL https://releases.conduktor.io/gateway-community-quickstart)Check that a consumer can't reach the cluster directly. It can't even resolve the broker's name, because it lives in a different network:
docker exec kafka-consumer-a kcat -b kafka:9092 -L -m 5
# -> Failed to resolve 'kafka:9092'Next, the same consumer reads the data through the Gateway, using its own SASL credentials:
docker exec kafka-consumer-a kcat -b conduktor-gateway:9092 -t customers -C -e -c 3 \
-s value=avro -r http://karapace:8081 \
-X security.protocol=SASL_PLAINTEXT -X sasl.mechanism=PLAIN \
-X sasl.username=consumer-a -X sasl.password=consumer-a-secret
# -> readable recordsSame consumer, same credentials, one different bootstrap address. Now it works.
Finally, the log line that shows why: the Gateway rewriting the advertised address before the client sees it.
docker logs conduktor-gateway 2>&1 | grep "Rewriting METADATA"
# kafka:9092 -> conduktor-gateway:9092This is where the magic happens: the broker advertises an address the client can't reach, and the proxy rewrites it to one it can.
Cross-network reachability, for free
When you need a free Kafka proxy to connect clients to clusters sitting in other VPCs or across clouds, reach for Gateway Community. It rewrites the broker addresses and passes SASL straight through, so the next time a new network needs in, you don't touch the cluster at all.
And because it's the same proxy that powers Conduktor Gateway, nothing you set up now gets thrown away: if you later need to encrypt fields, enforce schemas, or isolate tenants on that same path, you turn it on with a key, not a migration.