
Introduction#
Initially conceived as a “technical pipe”, a means to distribute data quickly between various applications, Apache Kafka has rapidly evolved to become an integral part of an organization’s data architecture.
Its power lies not only in its ability to handle massive data streams but also in its transformative effect on organizational data culture. With Kafka, data becomes a shared and accessible resource, a common language that different parts of the organization can use to communicate. This democratization of data allows for more informed decision-making, improved operational efficiency, and increased opportunities for innovation across all levels of the organization.
However, as with any technology, Kafka comes with its own set of challenges. One of these is the default limit on the record size it accepts. Apache Kafka is set to handle records up to 1MB (see our Kafka Options Explorer with message.max.bytes). This limit can be increased... if you know what you’re doing, as you should update many other configurations now.
Let’s clarify the use cases here and how we tackle this issue seamlessly and with style.
Who is sending send large pieces of data into Kafka?#
Apache Kafka is agnostic to the content it handles. Its ability to understand and process “bytes” allows it to accommodate a wide range of data types and formats. Bytes can represent anything. Their value is in the eye of the beholder: text, JSON, Avro, Protobuf… or many other fancy things:
-
CSVs: coming from your preferred ETL
-
PDFs: because it’s the way your organization moves data
-
Large images: in domains like Healthcare or Traffic monitoring
-
Videos or chunks of videos: for processing, intrusion detection
-
Sounds
-
IoT sensors data
-
Machine Learning models
-
…
How can we combine the business necessity of processing large data records with the technical limitations of Apache Kafka?
Impact of producing large records in Apache Kafka#
-
You know it isn’t a best practice.
-
You know the storage attached to Kafka is costly, and due to the replication.factor of your topics, you’re doing to duplicate the large records 3x or 4x times.
-
Large messages stored in Kafka will lead to extended broker restart times, thereby diminishing Kafka’s performance and reliability.
-
They will dominate resources due to the Kafka broker’s threading model, alongside numerous behind-the-scenes configuration adjustments required to make it function. In the end, it’s challenging to comprehend the impact fully.
You feel it’s a bad bad idea to send large records; it’s Pandora’s box.
Catch-22: you understand all this, but business demands are business! You come up with a marvelous idea to avoid these problems…
Rely on an Infinite Storage: AWS S3#
Everybody smirked at your suggestion to chop your large message into bite-sized pieces at produce-time for later reassembly at the client side. We all had a good laugh, and all said “PASS” in unison! (a terrible idea)
You have another card to play: implementing the “Claim Check Pattern“. Let’s explain it step by step.
-
The application sends a large piece of data into some inexpensive storage like AWS S3. When sent, it receives the file’s S3 unique reference and sends that into a Kafka record instead.
-
The applications reading your topic retrieve this reference and access S3 to obtain the data.

It’s pretty straightforward and totally ignores the aforementioned issues about large Kafka records. Here, what we send into Kafka is a simple string like “s3://mybucket/myfile.pdf”. It’s very minimal.
One problem is about the governance to access S3. Your applications must be able to access it, have a login, a password, manage secrets, handle password rotations, etc.
Initially, these issues may seem nonexistent because you know your producers and consumers. However, as Kafka spreads into various Business Units of your company, this governance concern quickly becomes noticeable.
Conduktor: Seamless S3 offloading#
Our S3 Cold Storage plugin transparently implements this pattern. Applications don’t need to change anything. They normally send their large messages, and then some magic occurs.
Conduktor handles all the gibberish of moving to and retrieving from S3 and avoids any governance/security issues. The applications are not aware AT ALL of what is happening! It’s all done behind the scene.
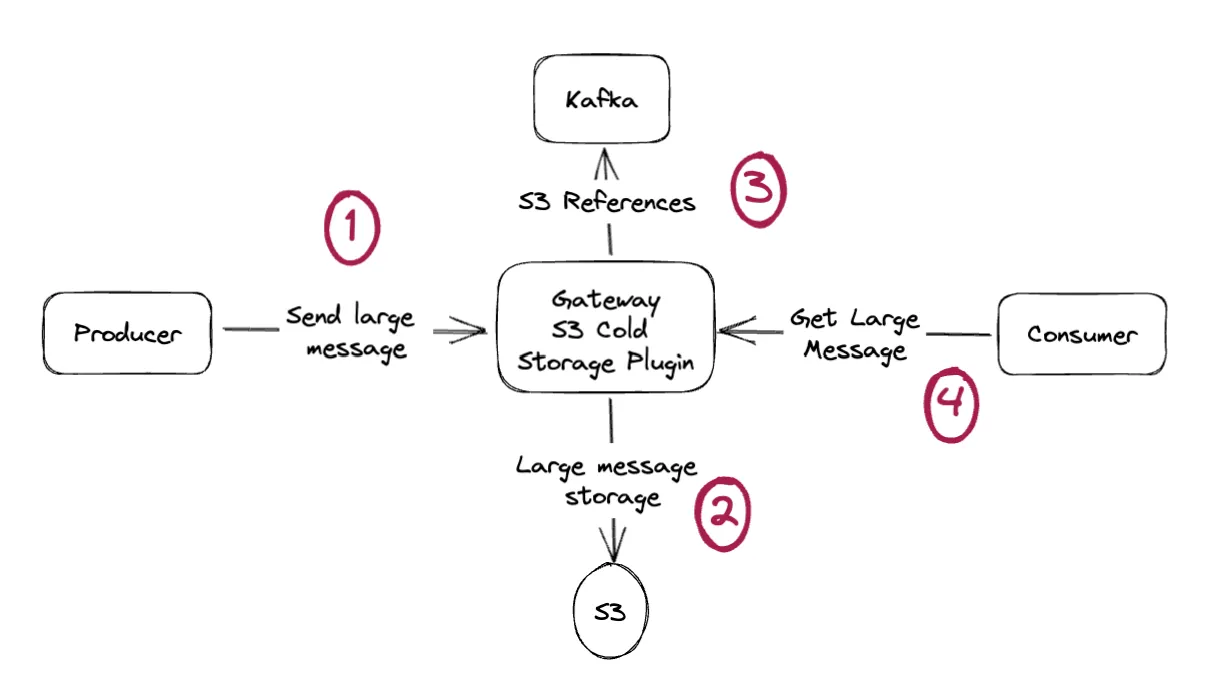
Kafka does not store large messages, but Producers and Consumers keep sending/receiving large messages seamlessly (from Conduktor).
-
The Kafka storage problem has been entirely voided
-
No duplication of large records in Kafka
-
No penalty on Kafka’s performance and reliability
Beyond records: batches#
We wrote the story by talking about individual records. But Kafka is not about records, it’s about batches of records.
Suppose you’re investing tons of logs or telemetry data, dozens of thousands per second. You’ve followed recommendations by setting linger.ms, a large batch.size, compression.codec and so on.
Given the vast amount of information passing through, your application hits the “batch.size” limit easily, and this is slowing down performances.
In a way, you are facing all the drawbacks discussed previously. You had adapted your configuration to optimize traffic and so forth. Still, now, you have to store large amounts of data in your Kafka, which is expensive regarding network, storage, and read operations.
What if we were to apply the same functionality (the claim check pattern) not on a single message but on an entire batch of records?
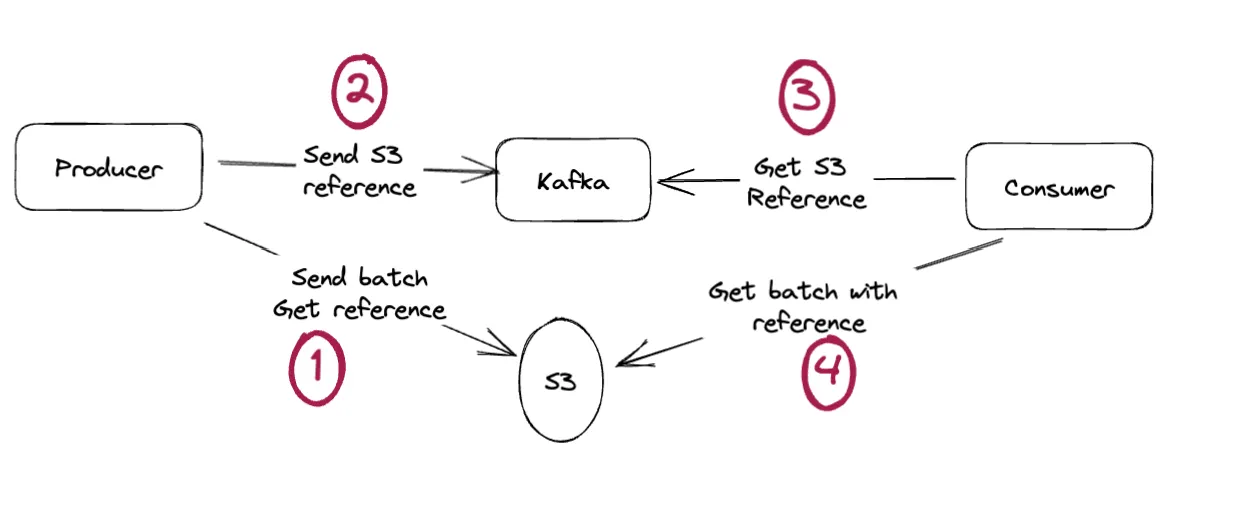
Kafka does not provide you any means to do 1 and 4, as record batches are very internal details, inaccessible and sensitive.
Conduktor does it. Sending a whole batch to S3 and storing a unique file reference into Kafka for this batch? Done. And again, totally seamless for consumers: they will receive the expected records one-by-one on poll(), totally unaware of the magic that happened.
We all have this problem: it’s just waiting to appear#
If you are still reading, are you asking yourself: “I don’t have this problem. I don’t need this Claim Check pattern.”?
Let’s run through an exercise:
-
You have a Kafka Streams application that counts the number of words.
-
It’s the simplest example to get you started with Kafka Streams, and you can find it here: WordCountLambdaExample.java
Everything runs smoothly; it’s highly efficient, you have a word list with an occurrence, and everything seems perfect. Kafka Streams stores every word and its count.
Let’s tweak the business requirement: we need to add more contextual information for each word: their position in the sentence, their location on the page, the chapter name, etc.
Now you have a problem, especially with the most common words. Their state will grow like crazy. These words will rapidly accumulate much information, and you might hit the message size limits imposed by Kafka.
It might seem like an unusual exercise, but it highlights a potential issue we are all facing in our applications: state explosion.
No matter you’re doing a Spring application, a Kafka Streams, etc., the size of your data is often outside of your control because it depends on the business itself:
-
For an e-commerce website: a user ordering hundreds of items: your ‘order’ data will transform into a multi-megabytes JSON!
-
A support ticket system: too many comments, multi-megabyte JSON!
-
A “like“ system: too many people liked a post, you now have arrays with thousands of IDs taking megabytes
In production, your application will halt because it can’t emit messages anymore (over the limit of Kafka). The application will crash, some pods will restart, and users are complaining it doesn’t work. Panic ensues. After some investigative work, you and your Ops team identify the problem — the messages have grown too large. As a corrective measure, you manually change the maximum message size for this specific topic.
You restart your producer applications, it works! … but now the rest of the applications (consumers) may also have issues with your large data (longer time to load in memory and to process). Your Kafka infrastructure will also pay the price (as explained above).
The real problem isn’t with Kafka but instead with a design mistake that could take much time to fix. Your quick fix with your Ops team, where you changed the maximum allowed size, could ultimately hold you back.
Conduktor will:
-
Move messages to S3 seamlessly
-
Protect your Kafka infrastructure and performances
-
Alert you in the audit log if such matters happen
-
Buy you time to correct your application design
Cloud Kafka Providers: Limitations#
It’s worth noting that if you’re using a Cloud provider to manage your Apache Kafka, you likely don’t have the flexibility to set the maximum batch size as you desire.
-
You’ve chosen Azure Event Hub for Kafka, your maximum size is capped at 1MB. What do you do if you need 1.1MB?
-
With AWS Managed Streaming for Kafka (MSK), the maximum size is capped at 8 MB. So, what happens if you have 8.1 MB?
-
Confluent Cloud allows messages from 8MB on Standard instances and up to 20 MB on Dedicated instances.
What happens to performance and resiliency? What happens if you need more?
Conclusion#
In essence, Conduktor’s S3 Cold-storage plugin is about offloading data to:
-
protect your Kafka infrastructure and performance
-
avoid costly governance and security issues
-
enable functionalities that don’t exist in Kafka
-
save tons of money
-
extricate yourself from challenging situations requiring time to handle a situation you did not expect.
We hope you enjoyed this article and that it gave you some ideas for your Kafka infrastructure. Contact us if you want to discuss your use cases. We are Kafka experts and want to build out-of-the-box and innovative solutions for enterprises using Apache Kafka, so we are very interested in your feedback.
You can also download the open-source version of Gateway (which does not support our enterprise features) and browse our marketplace to see all the supported features.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.