
This topic can feel like walking on a bed of nails: fail-over from one Kafka instance to another. So many things to know here!
Apache Kafka is renowned and massively used precisely because of its inherent resilience. You usually have nothing to do, just have many brokers, and the natural replication of data in Kafka makes the whole system safe and resilient.
Why are we even considering failover strategies here? It seems counterintuitive and unnecessary.
Are you familiar with the acronym: DRP? It’s a very serious procedure that all enterprises consider to ensure their business continuity in the event of massive technical problems. Its goal is to minimize downtime, protect valuable data, and facilitate the continuation of critical business functions after an unexpected event.
DRP stands for “Disaster Recovery Plan”.
The "D" stands for DISASTER#
What is a Disaster? It’s all bad things that are unpredictable:
-
earthquakes, hurricanes, floods, wildfires
-
human accidents, industrial incidents, terrorism, hackers
-
Covid…?
When your data is critical for you or your customers or due to regulatory requirements: you have to be prepared. Make a plan and test it! Disaster Recovery exercises are paramount. You must simulate a real disaster in a real production situation (“This is not a drill”) and see how your plan goes.
There are two important metrics to consider in a DRP:
-
RTO (Recovery Time Objective) is the target time for restoring operations after a disruption, specifying how quickly systems should be back online. e.g.: 4h
-
RPO (Recovery Point Objective) is the acceptable amount of data loss, indicating the maximum tolerable time gap between backups. e.g.: 1h
Netflix is famous for having introduced the Chaos Monkeys and the Chaos Gorilla to regularly break their systems on purpose to ensure they are always fully resilient. Note that we have a similar product for Apache Kafka: Chaos.
Is your Kafka a critical system in your organization? If yes, let’s continue and focus on concrete examples illustrating how and why to implement a Disaster Recovery (DR) plan using Apache Kafka.
Quick recap: Region and Availability Zones#
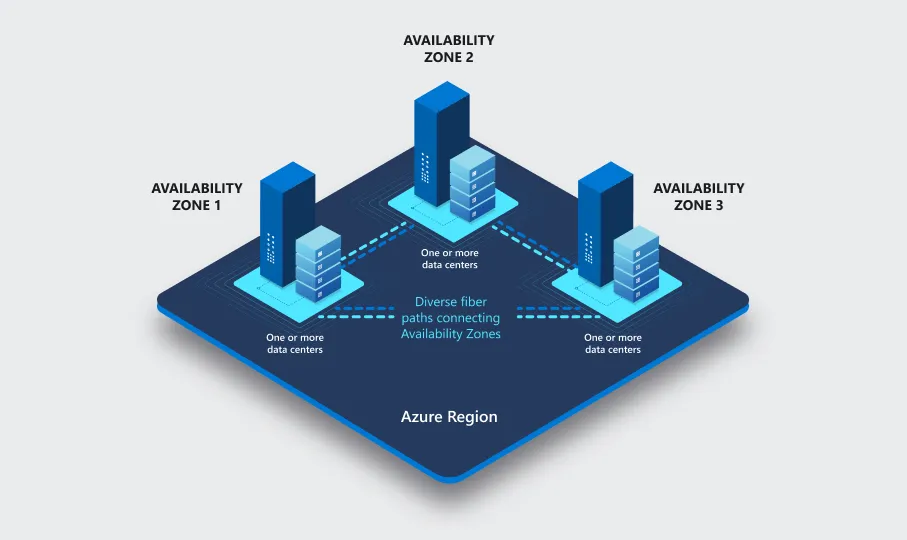
In AWS, “us-east-2” is a Region (US East (N. Virginia)). It is composed of 6 independent Availability Zones.
An Availability Zone (AZ) comprises separate facilities with their own power, networking, and cooling infrastructure. They are designed to be physically isolated from each other to provide redundancy and fault tolerance.
AWS us-east-2a is one of these Availability Zones and is itself composed of multiple physical Data Centers that are highly interconnected.
Am I safe when an Availability Zone goes Down?#
You set up Kafka in a Region “us-east-2”. You’ve meticulously configured it to spread on 3 Availability Zones: us-east-2a, us-east-2b, and us-east-2c.
This is a robust production setup for Kafka, and it’s precisely how Kafka should be deployed. You’re safe.

If one Availability Zone goes down, you’re good because Kafka has inherently its data replicated to the two other AZ.
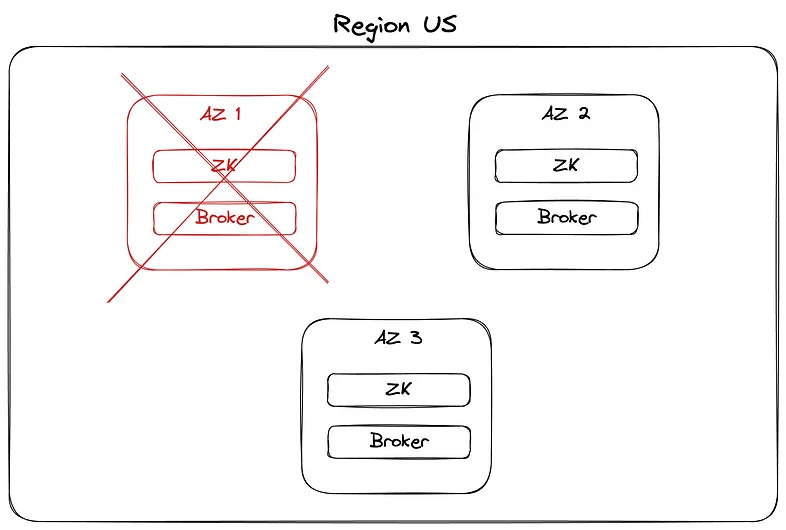
In Kafka terminology, your partitions have just lost an ISR: if replication.factor was setup to 3 (I hope for you), you now have only two replica of the data.
This is good enough: all data are still flowing, and nothing has been lost. What a success!
Am I safe when a Region goes Down?#
Let’s go bigger. A Disaster happens out of the blue, and the AWS Region where you’re hosting your primary Kafka just went offline!
If you hadn’t prepared for this, it’s not just a Disaster to you: it’s a Catastrophe.

It’s quite rare for entire regions to fall, but at the time of this writing, the latest region going down was … GCP Paris one month ago.
- https://www.theregister.com/2023/05/10/google_cloud_paris_outage_persists/ “Google Cloud’s europe-west9 region took a shower on April 25. As datacenters and water don’t mix, outages resulted.”
They are many regular outages on AWS or GCP 👀:
It’s more common that Availability Zones (AZs) fail, and you’ve only preemptively distributed your brokers and zookeepers among multiple AZs to survive the loss of an AZ. A Region outage is a bit more tricky to handle.
You could survive them by spanning your Kafka cluster on multiple Regions, right? (say us-east-1 and us-west-1). But there is a subtlety here: it will work if you have unlimited “pockets” and if you don’t care about latency.
- This would cost a fortune on cross-region networking to send data to another AZ.
Egress to a different Google Cloud zone in the same region: $0.01 per GiB Egress outside of Google Cloud: up to 0.2$ per GiB
- It would impact your latency dramatically. If you send data somewhere further, it takes more time. Physical constraints still apply, even in the Kafka world 😉.

Even if you span across regions to be protected and replicate data cross-regions, there is still one aspect that will drive your DRP to the ground… humans!
Never trust Humans#
Your DRP may plan for many worst-case scenarios that you expect from a technical/networking perspective, such as a network partition or encountering a bug in Kafka during an upgrade.
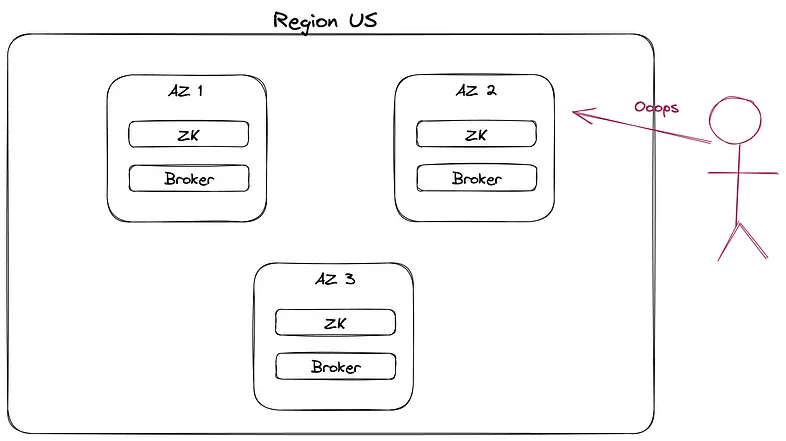
However, experience shows that an insider can trigger a DR by causing malicious or inadvertent data loss. Google can link to many examples! “deleting production database” is a thing.
Sure some developers/ops have already deleted whole AZ by mistake!
1$ terraform apply -auto-approve 2deleting eu-production-db … 3done 4 5Ctrl^C 6# Too late! Call 911!
For instance, Confluent strives to operate everything by software, not humans. https://www.confluent.io/blog/cloud-native-data-streaming-kafka-engine/#automated-operations
The system must be able to automatically detect and mitigate these issues before they become an issue for our users. Hard failures are easy to detect, but it is not uncommon to have failure modes that degrade performance or produce regular errors without total failure.
Failover: A massive investment#
Every business has a plan to enable failover and/or restore hot backups in case of disaster. Implementing a failover is always a colossal investment.
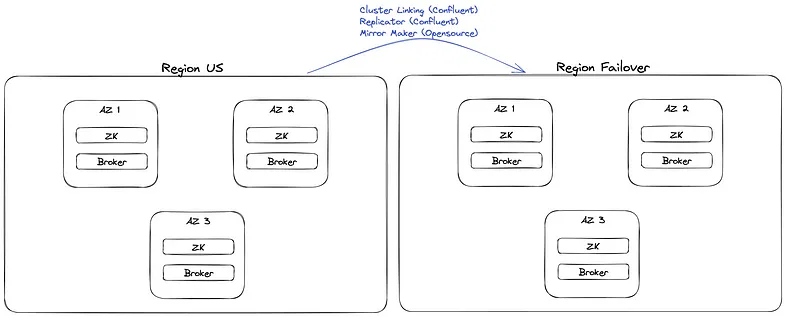
It generally means you must duplicate all your Kafka deployments, duplicating the total cost (infrastructure and maintenance).
You also have to ensure data replication between your Kafka instances. This means installing Mirror Maker (or purchasing commercial tools like Replicator or Cluster Linking), which increases your setup and networking costs.
On top of these infrastructure costs, rigorous governance and security measures for access points become imperative, as they must be identical:
-
Compliance and Regulatory requirements (GDPR, HIPAA): always safeguard sensitive data no matter where they
-
Authentication and Authorization: how do you manage the “switch” and make sure all your apps and people can still work properly during a failover?
-
Network Segmentation and Isolation: ensure the failover instances are accessible and follow the same networking rules. Easier to say than done
-
Monitoring and Auditing: a failover infrastructure must follow the same rules
When the Storm Hits#
Let’s focus on the dreaded moment: a Cloud region has fallen (let’s say, us-east-1 like… yesterday), a Kafka instance is inaccessible, and it’s time for the switchover.
Are you prepared and confident the transition will be smooth?
-
You know your data are available in the backup cluster
-
You know all the authorization, authentication, networking are good
-
You have the GO to proceed with the switchover
You send an URGENT internal notice, to all engineering:
Please update the bootstrap.servers to xxx:9092 for all your applications and restart them to connect to the failover Kafka cluster, thanks.
Things are not so easy in real-life:
-
multiple languages
-
multiple technologies
-
Kafka Connect, ksqlDB, CDC, etc.
-
Where is this config? In some application.yaml? Terraform? Ansible? Vault?
-
What are the procedures to update a config? Who needs to approve? The Tech Leader is on holiday, how to trigger the CI/CD again?
-
Who is taking care of this application? The team has been dismissed!
-
… It’s Christmas time, no one is around!
Do you feel the stress rising just by being besieged by all these questions you could ask yourself?
Before Disaster hits:

- Manual update and restart of ALL your systems:

All this to say: you could have invested like crazy in your plan, but when it’s time to execute it, it will go nowhere, and money will burn.
That isn’t very encouraging.
How to failover between Kafka clusters? The right way.#
When it’s time to failover, never rely on humans. Rely on automation. Systems have no emotions; they won’t stress during such dark times.
Conduktor Gateway is one solution to answer this challenge at scale.
It sits in front of your central cluster and your fallback clusters. All your applications and systems communicate with Kafka through the Gateway, seamlessly (totally transparent).

Everything goes right until the Disaster hits!
Fortunately, the Gateway will automatically notice the unavailability of the central Kafka cluster and will switch the traffic to your fallback clusters. It’s like a Load Balancer, except it’s not a Single Point of Failure (it’s distributed), it speaks Kafka, and has plenty more valuable features.
You can read find many use-cases on our blog.
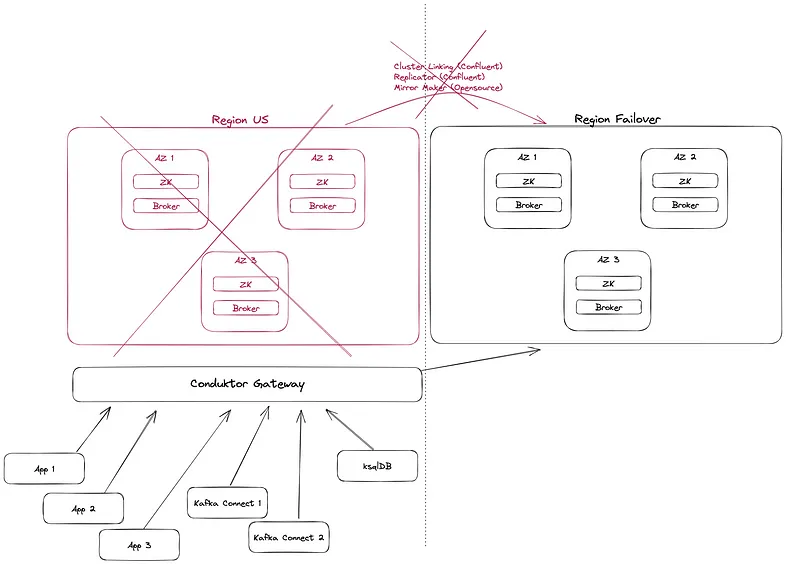
In an instant, all your applications, Spring Boot, Kafka Streams, Kafka Connect, ksqlDB, now communicate with the failover cluster WITHOUT any interruption or change of configuration.
NOTHING TO DO.
No stress. The business continues as usual. It’s a non-event.
When the Disaster is passed, you can switch back to the other side seamlessly again. It’s like almost no one knew what happened. This is called failover automation, and it’s glorious.
Conclusion#
Just yesterday, the AWS east-1 region had a massive outage (Amazon US-East-1 region’s bad day caused problems if you wanted to order Burger King or Taco Bell via their apps.) that affected many major companies.
It’s a good reminder that while the Cloud is incredible, we always need a solid plan B. Even if you are on-premise, your Kafka is running on some machines: what if they stop suddenly?
This is why Disaster Recovery Plans are critical for all enterprises, and many regulations ask for them.
As they are very stressful for people, and often barely tested or gradually forgotten as time passes, automation should be key in automating failover situations. This is what Conduktor Gateway is achieving.
—
We hope you enjoyed this article and that it gave you some ideas for your Kafka infrastructure. Contact us if you want to discuss your use cases. We are Kafka experts and want to build out-of-the-box and innovative solutions for enterprises using Apache Kafka, so we are very interested in your feedback.
You can also download the open-source version of Gateway (which does not support our enterprise features) and browse our marketplace to see all the supported features.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.