What Kafka Users Actually Care About in 2024: Kafka Summit London Recap
Kafka Summit London 2024 highlights: real-time analytics, GitOps self-service, SQL over Kafka, and the shift from batch to streaming data.


We attended Kafka Summit London last week. It remains our favorite event for connecting with the community and understanding what problems people actually face. Confluent uses this summit to announce their vision, and this year was no exception.
The Industry Is Moving From Batch to Real-Time

Data streaming has become central to modern data architectures. The conversations have shifted. Five years ago, discussions centered on low-level Kafka details: deployment, scaling, settings, ksqlDB, event sourcing. Now the focus is on maximizing data value across organizations with minimal complexity.
The major data platforms have noticed. Snowflake, Databricks, and MongoDB are integrating streaming capabilities directly into their platforms. They want to process data streams without external services.

AWS Redshift streams directly from MSK. Snowflake ingests streaming data via Snowpipe for real-time analytics. Databricks combines big data and machine learning to process streams. MongoDB recently added real-time stream processing.
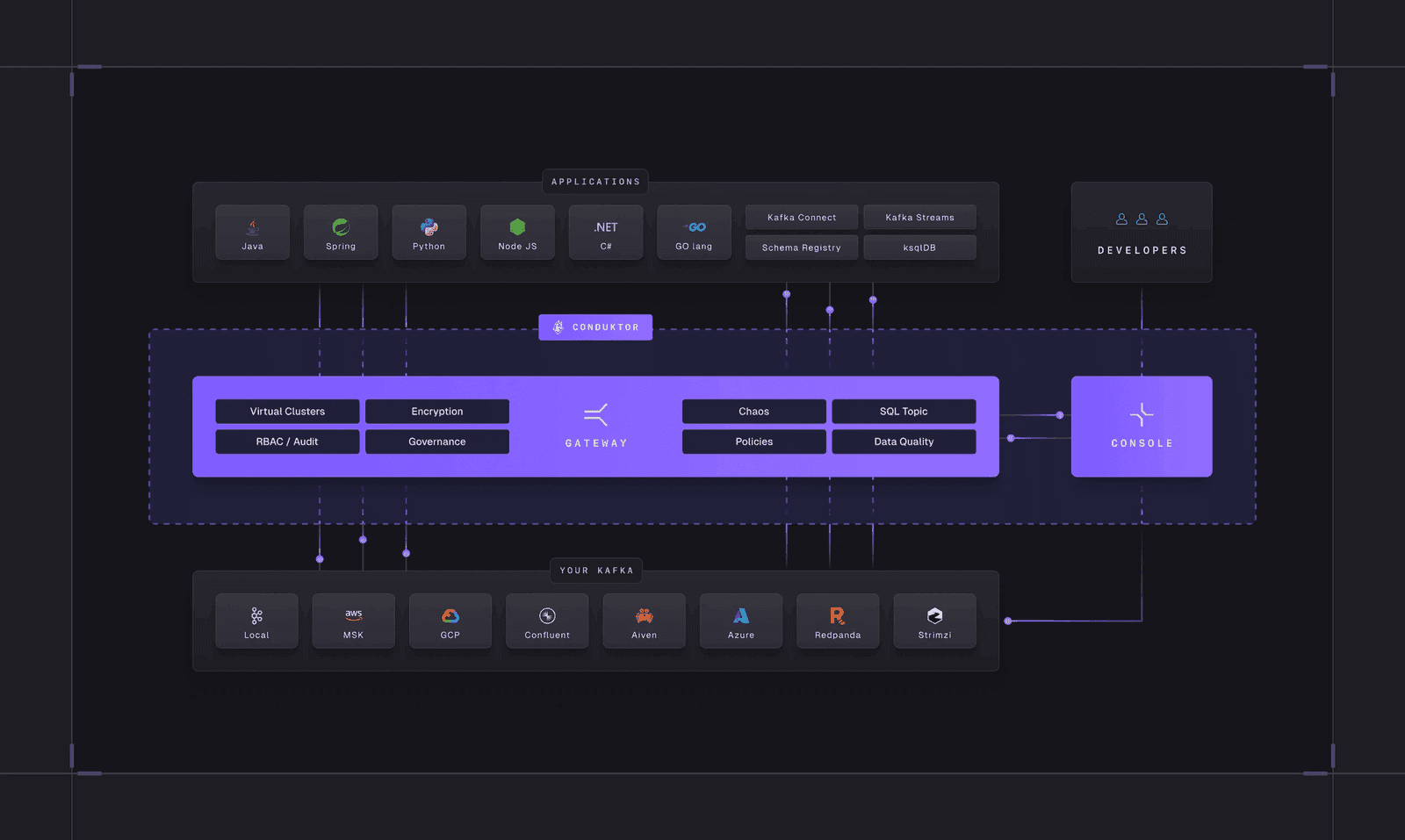
Confluent wants to bring data lake use cases into Kafka itself. Conduktor is moving in the same direction: we provide SQL access to Kafka data without pipelines or stream processing frameworks. The goal is to avoid building costly pipelines that duplicate data and create confusion about data ownership.
Confluent's Bet: Kafka as a Data Lake
Kafka Summit, organized by Confluent, naturally steers the discussions. Last year focused on Flink. This year, analytics took center stage. This shift matters more: analytics represents a costlier challenge within organizations, and there hasn't been real disruption in this space for years.
"Data streams are the abstraction that unify the operational estate and Kafka is the open standard for data streaming" — Jay Kreps, CEO Confluent
The data infrastructure landscape is experiencing several paradigm shifts. Separating compute from storage has become standard, with Amazon S3 as the de facto storage layer. Apache Kafka introduced tiered storage, and Warpstream pushed this even further.
Analytics led this model: store everything in data lakes, query flexibly with SQL, Parquet, and Apache Iceberg.
Confluent introduced TableFlow, which materializes Kafka topics as Apache Iceberg tables. (Iceberg appears to be the market leader; alternatives include Deltalake from Databricks and Apache Hudi, which suits streaming workloads better.)
This changes how we think about Kafka. Instead of 7 or 14-day retention policies, we might see infinite retention become standard. Pipelines that just move data without adding business value could disappear. The distinction between data-in-motion and data-at-rest is blurring.
What Attendees Told Us at the Booth
This was our best Kafka Summit yet. The conversations went deep. Some visitors stayed for 2-3 hours discussing their challenges. Most already knew Conduktor and were close to trying it in their organizations.
We spoke with tech leaders, architects, platform teams, and security professionals. As a collaborative Kafka platform, Conduktor connects all of them. The combination of Console and Kafka proxy for governance and security sparked genuine excitement. Many visitors had never considered some of these capabilities possible.
The features that generated the most interest:
- End-to-end encryption
- Multi-tenancy
- GitOps-based self-service
- Granular RBAC for users and applications
- Data quality controls integrated with Schema Registry
- Our upcoming SQL feature
Our Console received strong praise (NPS score of 80). The polish took time, but users noticed.
We have a long roadmap. We pick our fights and move step by step. Praise is good, but tell us where we should improve.
The Six Challenges Kafka Users Keep Raising
Conduktor simplifies things; and we need this simplicity in our landscape. It helps speed up our daily operations, and helps us with credit card data (PCI DSS) by encrypting the topics. Conduktor, in one sentence, for me, is Kafka made simpler.
— Marcos Rodriguez; Domain Architect at Lufthansa
Here are the recurring themes from booth conversations:
Governance and Security: Managing data access, securing sensitive information, and maintaining data quality at scale. Organizations need reliable "golden data" for decision-making.
Self-Service and Monitoring: The market wasn't ready a few years ago. Now there's clear demand for self-service governance and monitoring to simplify resource lifecycle management and give product teams autonomy without losing control.
Data Encryption: Regulations have made encryption a common requirement. The community wants solutions that simplify encryption while offering flexibility, especially for transactional data and data shared across networks.
SQL Access to Kafka: Kafka clients exist for all major languages and integrate with many technologies. But you can't query Kafka directly; you can only consume sequentially. This works for streaming but fails for analytics. Teams build aggregated views using ksqlDB, Spark, or Flink, but these are brittle, complex, or expensive. We're exploring SQL access over Kafka without extra frameworks. This intrigued visitors.
Adoption and Scaling: Many attendees are new to Kafka or scaling their usage. Others are migrating from RabbitMQ. The goal is leveraging technology for business outcomes, not technology for its own sake.
Better Consoles and UIs: Developers need better insights, awareness, and controls. Platform teams need security, visibility, RBAC, audit capabilities, and the ability to restrict or enhance user experiences deliberately.
GitOps Self-Service for Developers and Platform Teams
Conduktor offers multiple interfaces:
- Graphical user interface (UI)
- Application programming interface (API)
- Command-line interface (CLI, coming soon)
- Terraform (on the horizon)
Our approach follows GitOps principles: automated, auditable, and repeatable operations. Platform teams and product teams manage their resources (clusters, groups, permissions, policies, alerts) and Kafka resources (topics, subjects, connectors) through a unified definition mechanism.
Example: authorizing an application to access a Kafka cluster with specific permissions:
apiVersion: "v1"
kind: "ApplicationInstance"
metadata:
application: "clickstream-app"
name: "clickstream-app-dev"
spec:
cluster: "shadow-it"
service-account: "sa-clickstream-dev"
resources:
- type: TOPIC
name: "click."
patternType: PREFIXED
- type: GROUP
name: "click."
patternType: PREFIXEDCommon Kafka Mistakes and How to Avoid Them
Our Customer Success team presented the typical issues they encounter with users. Watch for the recording.
Topics covered:
- Poison pills: A malformed record causes consumers to fail, forcing developers to shift offsets via CLI or Conduktor
- retention.ms too small: Causes too many open files and memory issues on brokers
- Producer misconfiguration: Improper acks, idempotence, and delivery.timeout.ms settings cause data duplication and data loss
- Upgrade strategies: Best practices for upgrading Kafka clients and brokers, managing ACLs
- Naming conventions: Structures your resources and enables self-service by defining owners based on prefixes
Naming conventions have the most organizational impact. Producer configuration is the most common pitfall because producers bear responsibility for data quality and continuity.

See You at Current 2024 in Austin
Thanks to everyone who visited us at Kafka Summit. Connecting in person beats Google Meet.
Next stop: Current 2024 in Austin.