
Apache Kafka is the dominant platform for data streaming, with the majority of large enterprises maintaining a Kafka ecosystem. However, it is not the only distributed messaging solution out there. We’ve previously compared Kafka with RabbitMQ and ApacheMQ, but in this blog we’ll be looking at how Kafka compares with Apache Pulsar. Like Kafka, Pulsar is maintained as an open-source solution by the Apache Software foundation. Though the two platforms were originally designed to solve wholly different use cases, there are now plenty of similarities between the two, and each can accomplish many of the tasks of the other.
What is Apache Kafka?
Apache Kafka is a distributed event streaming platform that can ingest events from different source systems at scale and store them in a fault-tolerant distributed system called a Kafka cluster. A Kafka cluster is a collection of brokers who organize events into topics and store them durably for a configurable time.
A Kafka topic is divided into several partitions. A partition holds a subset of events belonging to a topic. Incoming events are written to a partition sequentially, enabling Kafka to achieve a higher write throughput. Each partition is consumed by many consumers in parallel, with each consumer maintaining a unique view of the partition.
Message storage architecture and message consumption style make Kafka significantly different from typical message brokers. Also, Kafka doesn’t have the concept of queues. We will explore these differences further in the coming sections.
What is Apache Pulsar?
Apache Pulsar is a distributed messaging system that is also capable of handling message queueing. Pulsar is cloud-native and multi-tenant, capable of scaling up or down dynamically without downtime. The architecture of Pulsar is very similar to Kafka’s, with Pulsar also having clusters that are collections of brokers.
A typical Pulsar cluster will have three types of nodes: brokers receive and dispatch messages, BookKeepers handle persistent storage of messages, and ZooKeepers take care of coordination between nodes. Apache Kafka also uses ZooKeeper, but this feature will be replaced in newer versions of Kafka.
The reliance on both BookKeeper and ZooKeeper gives Pulsar a more complicated architecture than Kafka overall, particularly once ZooKeeper is replaced. However, Pulsar does support message queueing, unlike Kafka.
Kafka vs Pulsar
Given their similarities, it is unsurprising that Kafka and Pulsar could be deployed for the same use cases. However, there are key differentiators that should influence the choice of platform.
Message Consumption
The first difference we can observe between Pulsar and Kafka is related to how messages are handled. Though both systems transfer messages from producers to consumers via brokers, in Kafka messages are pulled from the server by consumers. In Pulsar, consumers need to subscribe to topics, with messages pushed to subscribers.

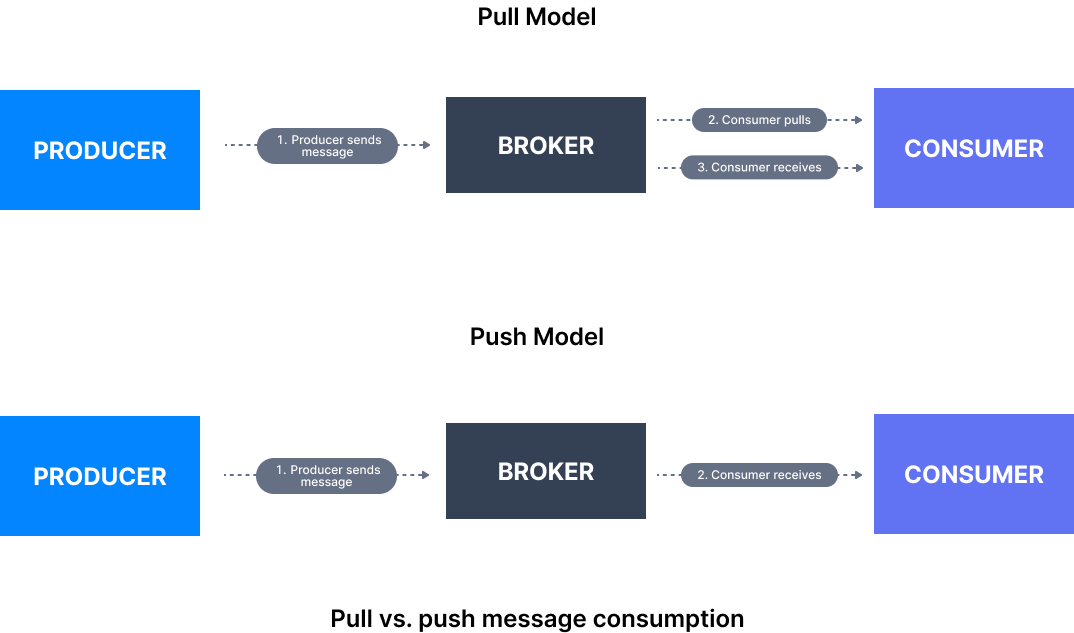
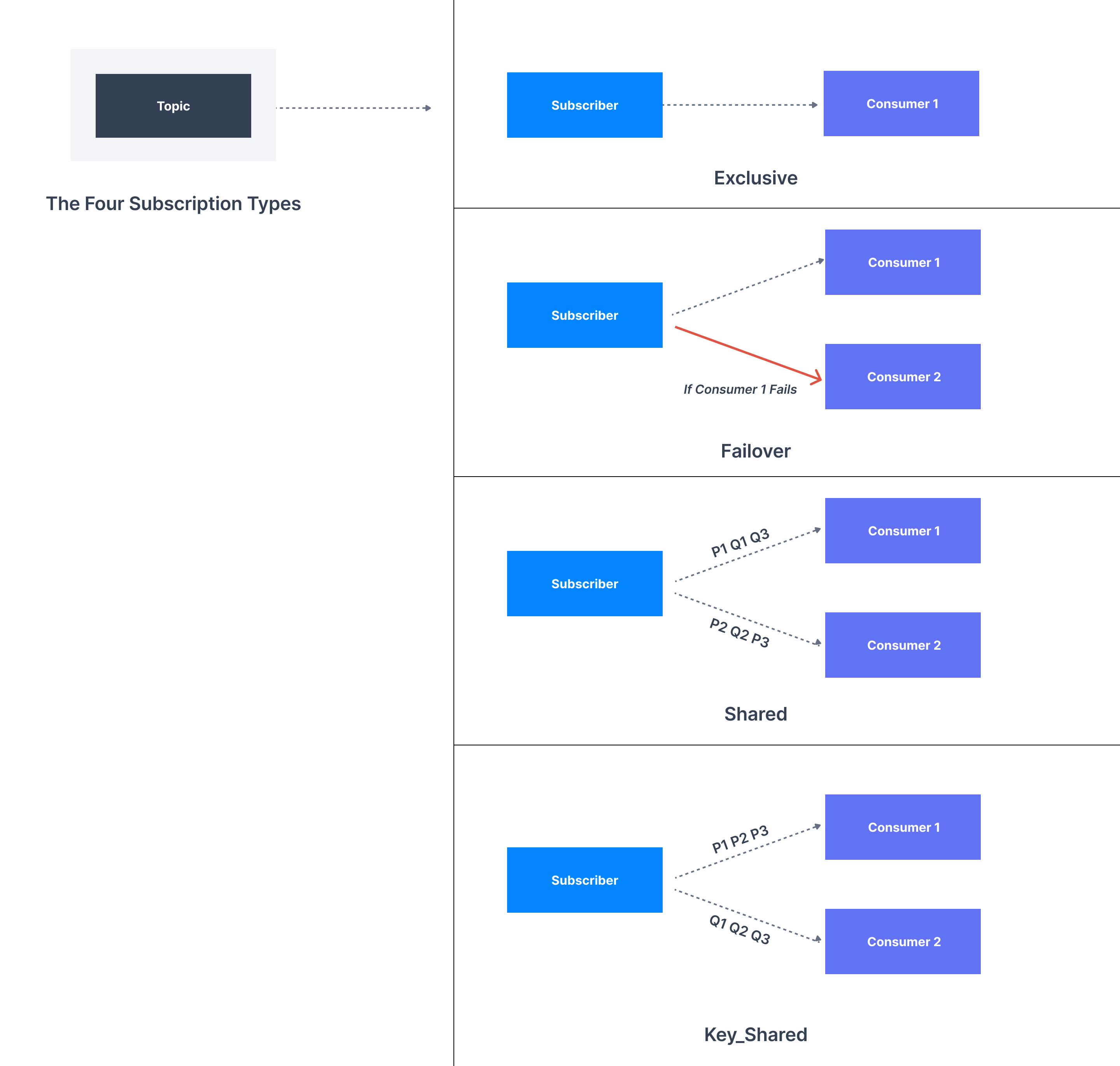
As with ActiveMQ and RabbitMQ, this enables Pulsar to support message queues where Kafka does not. When records are pushed to a topic in Kafka, you can either consume them directly or with a consumer group. In Pulsar, there are more options. Pulsar offers 4 subscription types: Exclusive, Failover, Shared, and Key_Shared:
Exclusive is the default method. Only one consumer can subscribe to an Exclusive topic.
With Failover, multiple consumers can attach to the same subscription, with one defined as the master consumer. If the master consumer disconnects, messages are passed to the next consumer in line.
In Shared, multiple consumers can subscribe to the same topic, with messages delivered in a round robin format. This means that strict message ordering is not guaranteed.
In Key-Shared, multiple consumers can again subscribe to the same topic, but messages are given keys that determine the consumer they are delivered to, allowing you to maintain message ordering.
Message Retention
Both Kafka and Pulsar can store messages indefinitely, though with slightly different methods. Kafka messages are durable by default, but have a retention period set by log.cleanup.policy. The default for this policy is a week. Pulsar uses Apache BookKeeper to handle persistent storage, which is a distributed write-ahead log system.
BookKeeper creates nodes called Bookies that are assigned to individual brokers; each broker can have any number of bookies. However, BookKeeper manages storage independently of brokers, meaning you can increase capacity through BookKeeper itself, without needing to add more brokers.
Message Tiering
Perhaps the crucial advantage of BookKeeper is that it enables tiered storage out-of-the-box for Pulsar. Kafka can support tiered storage but it is not available by default, meaning that Pulsar can deliver storage cost savings by moving older data to cheaper storage solutions.
Relying on an object storage service like S3 to persist older messages also prevents performance problems on live data when consuming a topic for old data.
Stream Processing
Kafka has some significant advantages in stream processing. Kafka Streams and ksqlDB enable developers to build scalable applications that can deliver all necessary stream processing functions, like joins, windowing, and aggregations. Kafka can further enhance its stream processing capabilities through the Kafka Streams API.
Pulsar is far more limited, relying on Pulsar Functions. Functions offers basic functionality but is not a true stream processing solution. It will often need to be supported by another system like Apache Flink or Apache Storm, adding further complexity to an already complex ecosystem. However, Pulsar can perform SQL on streaming data thanks to its integration with Trino.
Message Queueing
As we mentioned above, one difference between Kafka and Pulsar is that Pulsar supports message queues. Pulsar allows the selective acknowledgment of messaging, meaning that multiple consumers can consume from one topic and process messages in parallel. With Kafka, you can only commit all messages up to a given offset. It is not possible to acknowledge individual messages.
Data Connectors
The Kafka Connect framework enables Kafka to support a wide range of external data sources. Kafka Connect comes with “connectors” to different ecosystem components that enable moving a large data collection into and out of Kafka - connections are known as ‘sources’ and ‘sinks’ for data that is moved in and out respectively. Organizations like Confluent have created dozens of connectors for Kafka connect, greatly simplifying development work by allowing users to quickly integrate legacy databases into Kafka or populate BI tools with just a few commands.
Pulsar matches this capability through Pulsar IO, but ultimately still lags far behind Kafka for support. Kafka Connect offers more than 400 connectors, while Pulsar is still in the dozens. This gap is likely to close with time, and developers can still build their own connections for Pulsar, but it is a big advantage for getting started with a Kafka project.
Support
If there is one reason why Kafka is the more mature and widely used platform, it is down to its enterprise and community support. Quite frankly, Kafka has more resources and more people behind it. Enterprises like Confluent, Amazon, Red Hat, and Aiven contribute to the development of the Kafka platform while also contributing hundreds of blog posts, tutorials, podcasts, and more. Of course, these enterprises offer managed Kafka services and cloud offerings that take away a lot of the complexity of dealing with Kafka. And users can further simplify the management of Kafka through tools like our own Conduktor Devtools, which provides an intuitive GUI that gives complete oversight of your Kafka ecosystem.
If you’re looking to learn anything about Kafka or ask questions, there are already loads of high quality resources. We provide hours of video lessons from Stephane Maarek, as well as the Kafkacademy for those who prefer written guides and tutorials. There are thousands of Kafka questions on Stack Overflow, hundreds of Kafka meetups, and dozens of ways to learn and test Kafka projects.
Unfortunately, Pulsar cannot match the Kafka community. Though there are some companies offering Pulsar services and supporting development, they do not have the size and resources of the likes of Confluent. The community is much smaller and you can’t expect the same quality in learning resources or other content. Even Pulsar’s biggest client, Tencent, makes much greater use of Kafka.
Conclusion
There is justifiably some excitement around Pulsar. It supports many of Kafka’s use cases while bringing important features out of the box. However, it is fair to say that Pulsar is still in the early stages of maturity. For those looking at a managed offering, there is simply no competition between Kafka and Pulsar. If you are evaluating the respective open-source offerings, there may be situations where Pulsar is more suited to your personal use case, and it is true that more features and better support will come with time.
If message queuing is required for your project, then Pulsar is a good option, particularly if ActiveMQ and RabbitMQ cannot cover all of your needs. For anything that involves streaming, Kafka is still the clear leader. Pulsar may one day catch up with Kafka’s feature set, but it simply isn’t there yet.
To get more out of Apache Kafka, try Conduktor for free.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.