
When we think of real-time streaming applications we usually think of data processing, map-reduce, hive, sparks, and data analytics. While this is true for streaming applications, there is another set of streaming applications where data is consumed from upstream, processed through some business logic and then sent downstream. Kafka Streams is a simple library built on top of Kafka that is used for the second type of streaming applications or microservices, which are more focused on the core application domain and less on analytics.
In Kafka Streams, a "Stream" represents the unbounded stream of data, which is consuming data from a Kafka topic. It might be working with one or more partitions based on parallelism built in an application.
Kafka Streams is developed on top of Kafka to hide some of the basic details about creating producers, consumers, managing transactions, and error handling; hence developers can focus on just writing code related to business logic.
Any JVM application which uses the Kafka streams library is considered a Stream application working with real-time data.
While using Kafka streams, the upstream needs to be a Kafka topic and the downstream could be a Kafka topic, API call, or database.
Let’s look at a few important keywords to help understand Kafka streams:
Source topics: Topics from which data is consumed. It's also called upstream for Kafka Streams applications.
Sink: Downstream where data is published/stored after processing. It could be another Kafka topic, database, or calls to external services.
Topology: DAG(Directed Acyclic Graph) which contains information about source topics, tasks, and sink topics. Nodes represent stream processors/operations and edges represent the stream of data.
Stream processor/tasks: Operations to be performed on data consumed from source topics. A few common operations to be performed on data could be: Filter, Map, Join, and Aggregate and they all become part of a single topology.
KStream: Represents an abstraction on records flowing through the topics. Compared to a database table, every new record coming is an INSERT operation.
KTables: Represents an abstraction on a changelog stream. Compared to a database table, every new record coming is an UPSERT operation. If a key already exists the record is updated, otherwise one is inserted.
Internal topics: KStream supports stateful operations; to store the intermediate state of these operations it creates internal topics also known as stream topics.
Local state store: Intermediate states are stored in a local DB(by default rockDB) for faster access which is maintained by KStream itself. States between internal state and the local DB are synced at certain time intervals.
Using Kafka streams library an application defines topology by specifying source topics, operations to be performed on records, and the sink to publish/store data.
The bootstrapping details about creating Kafka consumers and producers are hidden and an application is focused on implementing the core business domain.
A basic topology will look like the following:

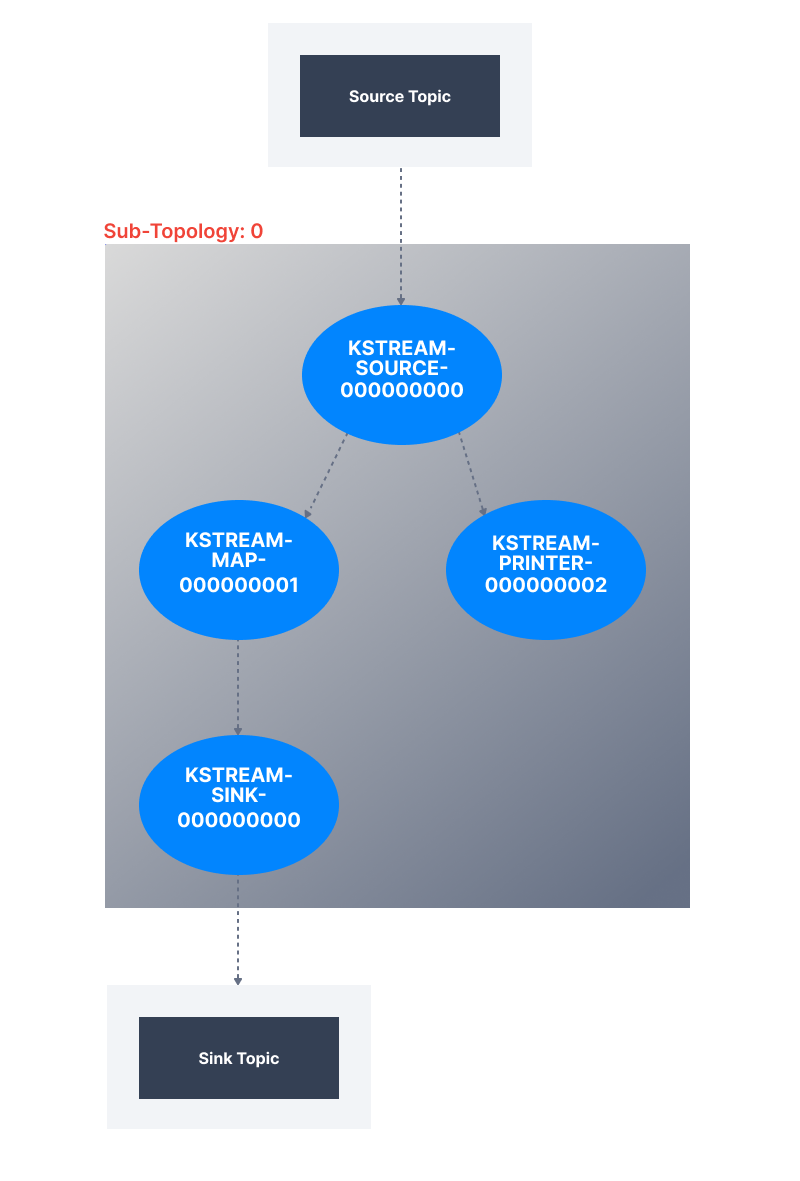
And the corresponding code for it will be:
1public Topology getTopology(StreamsBuilder kStreamBuilder) {
2 final KStream < String, User > userList = kStreamBuilder.stream("source-topic");
3 userList.map((k, v) -> KeyValue.pair(k, new User(v.getName(),
4 v.getFavoriteNumber() + 1, v.getFavoriteColor()))).to("sink-topic", Produced.with(Serdes.String(), new AvroSerde()));
5 System.out.println(" USers from topics -------");
6 userList.print(Printed.toSysOut());
7 return kStreamBuilder.build();
8}Advantages of using Kafka Streams in building real-time applications
Having a stream and database together: When implementing any stream applications, a database is also needed. So databases and streams go hand in hand. Kafka streams provides this functionality through KStream and KTable. In Kafka streams, a database can be seen as both a stream and a table which enables it to perform operations like aggregations. KTable represents a changelog topic where each record is an update on the previous record, hence why it behaves like a database table.
Stateful and stateless processing: One of the examples of a stateful operation is aggregation, like aggregating the number of clicks for a user where an application might need to maintain count. Kafka streams provides a simple Aggregates API to achieve a lot of stateful operations. Local state store, changelog topics and KTables make it easy to achieve stateful processing even if it's across transactions. Examples of stateless operations and transformations include filter, which is performed on every record and which can also be achieved through APIs provided by Kafka streams.
Windowed operations: Kafka streams provides APIs for the use cases required to perform stateful and stateless operations for incoming records within certain durations, for example, the number of orders processed in the last minute or performing the join operation for records coming in 2 topics for the last 30 seconds. Kafka streams support for windowed operations avoids the need to have a separate DB to maintain states or intermediate results.
Fault tolerance: Fault tolerance of the system can be achieved by specifying custom error handlers through properties and Kafka streams takes care of handling recoverable and non-recoverable exceptions internally without writing a single line of code. Kafka streams use internal topics and local state stores to save intermediate states. In case of error, instead of starting the entire process from the beginning, it can be restarted from the last saved intermediate state, hence improving performance in error scenarios.
Transactions support: Kafka Streams supports both at least once or exactly once semantics for transactions, which can be configured by simple properties. In case of errors, retrying entire transactions from source to sink can be achieved by just specifying the property for prcocessing.guarantee.
Considerations
It's easy to use Kafka streams and it provides so many features out of the box which is definitely not easy while using plain Kafka. When deciding to use Kafka streams, below are a couple of factors that need to be considered:
Increased configuration complexity: One of the complexities with Kafka is having too many configurations and relationships between those configurations, preventing you from achieving the best performance for a given load. When working with Kafka streams along with Kafka configurations, the configurations and relationships between them must be considered.
Difficulty in debugging: Kafka Streams becomes a black box on top of Kafka, and in case of errors it does not provide much in the way of logs to understand what should be going behind the scenes. Entire topologies get broken into multiple tasks during execution making it more difficult to understand the origin of a problem.
Internal topics: Kafka streams maintains internal topics to support KTables, windowed operations, etc. These internal topics might start consuming a considerable amount of space and cause multiple I/Os between Kafka and applications, potentially degrading performance. Internal topics and their usage needs to be understood very well in order to optimize performance for space- and time-critical applications. Unnecessary usage of KTables will create more internal topics which might cause performance issues in an application.
Local state store size: Similar to internal topics, implementation and usage of local state stores is a little complex. If one application instance starts processing a large amount of data, the local state store might grow considerably, and this extra space needs to be considered while calibrating infrastructure for applications.
Stateful operations behavior: With Kafka streams, performing stateful operations is easier but sometimes it might cause performance issues or errors in a system. If operations start causing transactions to timeout or message size becomes too large to handle, then problems will occur.
Complexity of the built-in topology: As one topology could be a combination of many sub-topologies, just by looking at the code it's very difficult to understand how execution will be carried out, how internal topics will be used and how local state store will be used. You might have to depend on external tools which can provide a better pictorial presentation of topologies to understand the usage of internal state stores and topics.
Data duplicity: Though Kafka streams supports exactly-once semantics, in one specific scenario while performing a join between two KTables it will end up generating duplicate records. This is documented as a known issue (KIP) with no solution yet.
Having worked with Kafka streams for over a year, I think it's a good library to be considered if solutions involve Kafka but consider having small topologies where transactions can be short and simple, can be understood easily, and do not cause timeouts.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.