Kafka Schema Governance: From Chaos to Confidence in 4 Steps
According to Confluent's 2025 Data Streaming Report, 68% of technology leaders cite data quality inconsistencies as their greatest data integration challenge. For Kafka environments, schema chaos is often the root cause.
If you've ever tried to make sense of data flowing through a large Kafka deployment, you've probably encountered a familiar problem: nobody really knows what's in the messages. A field gets renamed from user_id to userId and three downstream consumers break. A producer starts sending timestamps as strings instead of longs, and your analytics pipeline silently produces garbage.
This isn't a failure of intent. Teams want to do the right thing. But when you're moving fast, schema documentation feels like overhead. When producer teams are siloed, standardization feels impossible. And when there's no enforcement mechanism, good intentions quietly erode over time.
So how do you dig out of schema chaos? Here's the approach we recommend.
What is Kafka Schema Governance?
Kafka schema governance is the practice of enforcing consistent data structures across producers and consumers. It includes schema registration, validation policies, and access controls to prevent breaking changes from disrupting downstream applications.
Step 1: Start with Visibility, Not Enforcement
The instinct when facing governance problems is to immediately lock things down. Resist that urge. You can't fix what you can't see, and heavy-handed enforcement without understanding your current state will only create friction and workarounds.
Conduktor's Governance Dashboard gives you an honest picture of where you stand. What percentage of your topics actually have schemas registered? What serialization formats are in use across your organization? Which topics are your most critical, and do they have proper schema coverage?
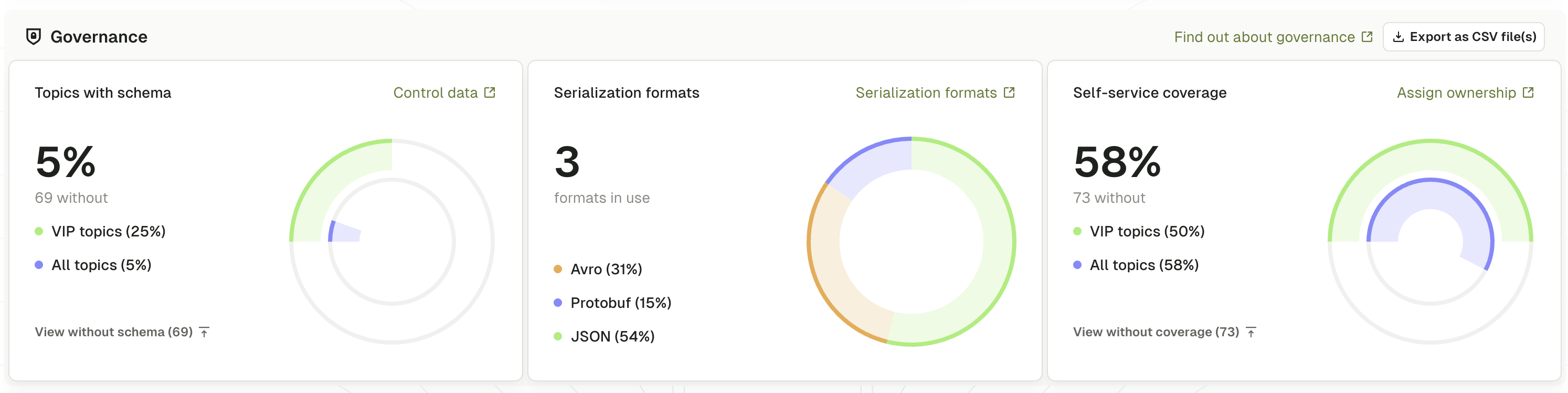
This baseline matters. It turns a vague sense that "governance is a problem" into concrete metrics you can track and improve over time.
Swiss Post faced this exact challenge across hundreds of Kafka topics serving multiple business units. They started by deploying visibility dashboards to measure schema coverage, identified the top producer systems responsible for the majority of violations, and worked with those teams on remediation, only then enabling enforcement for critical topics. The result: onboarding new consumers to existing topics went from days to hours because documentation was finally trustworthy.
Step 2: Audit Before You Block
Once you understand your current state, the next step is understanding your violations, but still without blocking production traffic.
Conduktor's Data Quality Policies let you define validation rules and run them in audit-only mode. You can enforce that messages have valid schema IDs, validate payloads against their registered schemas, or write custom validation logic using CEL expressions (a lightweight expression language for conditions like "amount must be positive" or "currency must match known values"). In audit mode, violations get logged and tracked, but messages still flow through.
This gives you two things. First, you learn which producers are sending non-compliant data and how often - perhaps a legacy order service is sending 200 invalid messages per hour because it never registered a schema. Second, you build confidence that your rules are correct before you start enforcing them. There's nothing worse than blocking legitimate production traffic because of an overly aggressive validation rule.
Now you have data. The question is what to do with it.
Step 3: Drive Accountability with Data
With visibility into violations, you can have productive conversations with producer teams. Instead of a vague mandate that "everyone needs to use schemas properly," you can show specific teams their violation counts and work with them on remediation.
Conduktor tracks violations by producer, so you know exactly which systems need attention. Maybe one team is responsible for 80% of your schema violations because they're running an outdated producer library. That's where you focus first. The data transforms a political conversation ("your team isn't following standards") into a technical one ("here are 1,247 violations from your inventory service this week").
Step 4: Enforce at the Infrastructure Layer
Here's the key insight: you can't rely on every producer team to implement validation correctly on their own. With many different producer systems, likely written in different languages, maintained by different teams, and with different release cycles, client-side enforcement is a losing battle. As Conduktor CTO Stéphane Derosiaux puts it, "it's garbage in, disaster out."
Conduktor Gateway, a Kafka proxy, enforces schema validation at the infrastructure layer, sitting between your producers and Kafka. Every produce request passes through validation. If a message doesn't comply, it's rejected before reaching the broker. This works regardless of producer implementation: Java, Python, Go, or third-party connectors all get the same enforcement. The tradeoff is a small latency addition (typically 1-3ms per request), but for most organizations, guaranteed data quality outweighs marginal latency increases.
What happens when messages are blocked? Producers receive a retriable error, and failed messages can be routed to a dead-letter topic for inspection. Violations are logged with full context (topic, producer ID, schema ID, and validation error) so you can diagnose issues quickly. For incident scenarios, Conduktor Gateway supports temporary policy bypass, letting you restore traffic flow while investigating without disabling the entire validation layer.
This is how you make governance stick. Not through documentation and hope, but through infrastructure that makes non-compliance impossible.
Control Who Can Change Schemas
Validating data against schemas is only half the battle. With multiple producer teams, you also need to control who can register and modify schemas in the first place. Otherwise, one team's breaking change becomes everyone's production incident. Imagine a payments team removing a required transaction_id field or changing a long to a string. Every downstream finance application breaks. For regulated industries, this isn't just inconvenient; GDPR, SOC 2, and DORA all require demonstrable data quality controls.
Conduktor's Schema Registry Proxy adds fine-grained authorization on top of your existing schema registry. You define which teams can create new schemas, which can modify existing ones, and which have read-only access.
The proxy works with your existing Confluent registry without requiring migration. It's an authorization layer, not a replacement.
The Path Forward
Schema governance follows the 1:10:100 rule: every dollar spent validating data at the source saves ten dollars at transformation and a hundred dollars at consumption. The math is clear: the earlier you catch a violation, the cheaper it is.
But the real ROI isn't just in avoided costs. It's in velocity. When producers trust that their schemas are validated, when consumers trust that data matches expectations, teams stop spending cycles on defensive coding and firefighting. For a typical enterprise Kafka deployment, a single schema incident can cost 10-20 engineering hours to diagnose, coordinate, and remediate across affected teams.
The path is clear:
- See: Build visibility into your schema coverage
- Audit: Detect violations without disrupting production
- Converge: Use data to drive team-level accountability
- Enforce: Make non-compliance impossible at the infrastructure layer
That's how you move from schema chaos to schema confidence.
Ready to see your schema coverage score? Book a demo and we'll show you your Kafka environment's governance baseline, plus how to move from audit to enforcement without disrupting production.