Chaos Engineering for Kafka
Chaos engineering for Kafka is the practice of deliberately injecting failures (broker outages, latency spikes, message corruption) into streaming systems to verify resilience before production incidents occur. Proxy-based approaches enable this testing without infrastructure access or risk to actual data.
Streaming platforms fail in ways that batch systems never experience. A Kafka broker goes down during peak traffic, consumers lag behind as partitions rebalance, or corrupted messages propagate through downstream services before anyone notices. Chaos engineering for Kafka means proactively injecting these failures to discover weaknesses before they cause outages.
The challenge with traditional chaos engineering approaches: killing brokers or introducing network partitions requires infrastructure access and risks impacting production data. Protocol-aware proxies solve this by intercepting Kafka traffic and injecting failures at the client-visible layer, without touching actual brokers.
Why Kafka Needs Chaos Testing
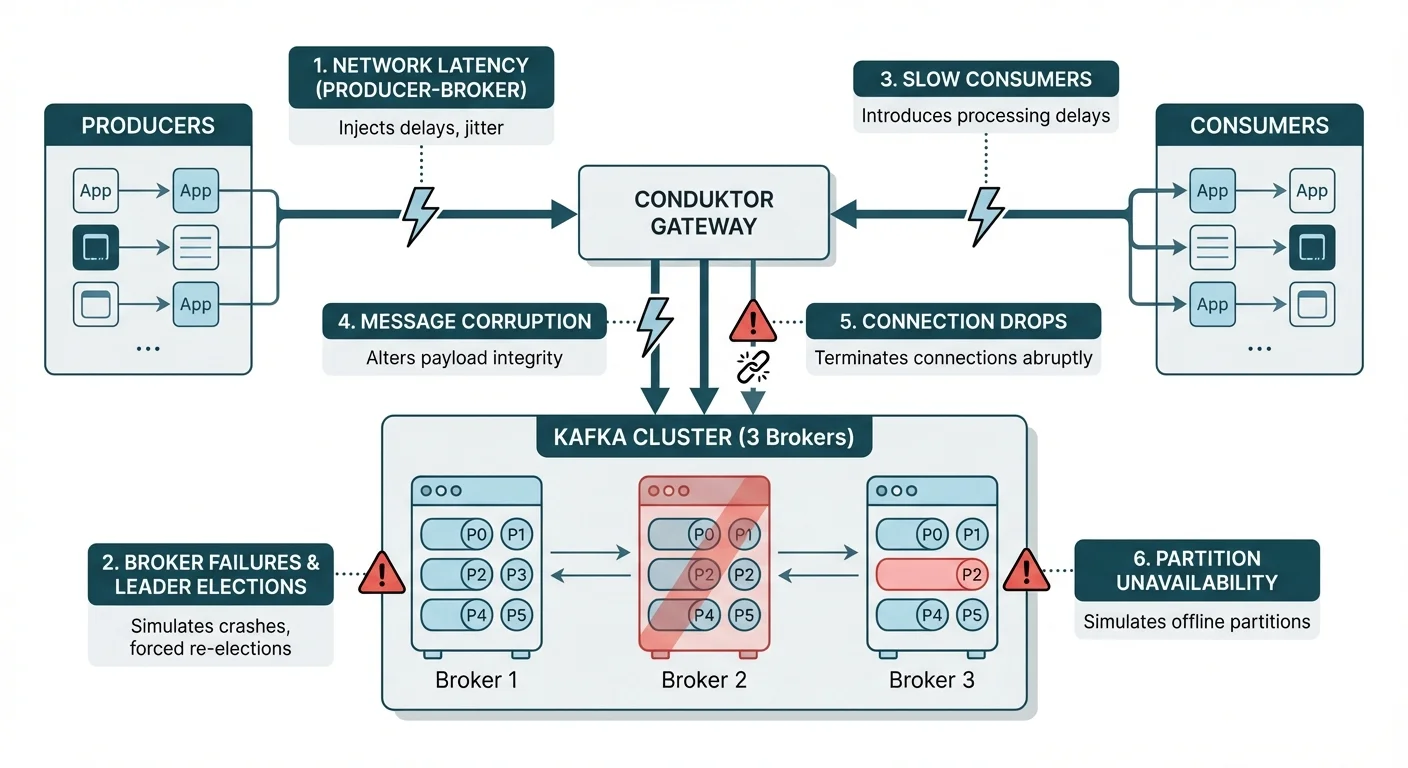
Kafka's distributed architecture creates failure scenarios that don't exist in simpler systems:
- Broker failures during rebalancing: When a broker goes down, Kafka elects new partition leaders and consumers rebalance. Applications must handle temporary
NOT_LEADER_OR_FOLLOWERerrors and connection resets gracefully. - Consumer lag cascades: A slow consumer triggers rebalancing, which causes other consumers to pause, creating a lag spiral that can take minutes to recover.
- Exactly-once semantics under failure: Idempotent producers and transactions behave correctly during normal operation, but what happens when brokers return stale
INVALID_PRODUCER_EPOCHerrors? - Schema evolution failures: A consumer receives a message with an unknown schema ID. Does it crash, skip the record, or enter an infinite retry loop?
Testing these scenarios in production risks data loss or service degradation. Testing them in staging often misses configuration differences. Chaos engineering bridges this gap by injecting failures in a controlled way.
Common Kafka Failure Scenarios to Test
Effective chaos engineering targets specific failure modes rather than random disruption:
- Broker unavailability: Simulate
UNKNOWN_SERVER_ERRORorCORRUPT_MESSAGEresponses to test producer retry logic and consumer error handling - Leader election delays: Inject
LEADER_NOT_AVAILABLE,NOT_LEADER_OR_FOLLOWER, andBROKER_NOT_AVAILABLEerrors to validate client behavior during partition leadership changes - Latency spikes: Add 500ms-2s delays to produce and fetch requests to test timeout configurations and backpressure handling
- Message corruption: Append random bytes to message payloads to verify consumer deserialization error handling
- Duplicate messages: Return the same message multiple times to test idempotency in downstream processing
- Invalid schema IDs: Overwrite schema registry IDs with invalid values to test deserialization failure paths
Each scenario maps to a real-world failure. Broker unavailability mirrors hardware failures or network partitions. Latency spikes replicate cross-AZ network degradation. Duplicate messages simulate what happens when consumers crash before committing offsets.
Proxy-Based Chaos Testing with Conduktor Gateway
Traditional chaos tools require infrastructure access to kill processes or inject network faults. Conduktor Gateway takes a different approach: it sits between Kafka clients and brokers, intercepting the Kafka protocol and injecting failures at the application layer.
This architecture enables chaos testing without:
- SSH access to broker nodes
- Kubernetes privileges to kill pods
- Network-level fault injection tools
- Risk of corrupting actual topic data
Gateway's chaos interceptors simulate failures that clients experience, not infrastructure-level outages. The brokers remain healthy while clients receive error responses that match real failure scenarios. For complete interceptor documentation, see Chaos Testing in Conduktor Gateway.
Simulating Broken Brokers
Test how producers and consumers handle broker errors:
pluginClass: io.conduktor.gateway.interceptor.chaos.SimulateBrokenBrokersPlugin
config:
rateInPercent: 25
errorMap:
FETCH: UNKNOWN_SERVER_ERROR
PRODUCE: CORRUPT_MESSAGE25% of requests return errors. Monitor your application's retry behavior and alert thresholds.
Simulating Latency
Test timeout configurations under network degradation:
pluginClass: io.conduktor.gateway.interceptor.chaos.SimulateSlowBrokerPlugin
config:
rateInPercent: 50
minLatencyMs: 200
maxLatencyMs: 2000Half of requests experience 200ms-2s latency. Validates request.timeout.ms and session.timeout.ms settings.
Simulating Leader Elections
Test client resilience to partition leadership changes:
pluginClass: io.conduktor.gateway.interceptor.chaos.SimulateLeaderElectionsErrorsPlugin
config:
rateInPercent: 30Clients receive LEADER_NOT_AVAILABLE, NOT_LEADER_OR_FOLLOWER, and BROKER_NOT_AVAILABLE errors.
Simulating Message Corruption
Verify consumer deserialization error handling:
pluginClass: io.conduktor.gateway.interceptor.chaos.FetchSimulateMessageCorruptionPlugin
config:
topic: "orders.*"
rateInPercent: 10
sizeInBytes: 5010% of messages have random bytes appended. Tests whether consumers log errors or crash.
For all chaos interceptors, see Chaos Testing in Conduktor Gateway.
Running Chaos Experiments Safely
Chaos engineering requires discipline to avoid causing the very outages you're trying to prevent:
- Start with low failure rates: Begin at 5-10% and increase gradually. A 100% failure rate in production isn't chaos engineering, it's an outage.
- Scope experiments narrowly: Apply interceptors to specific virtual clusters, topics, or consumer groups rather than all traffic. Gateway's
scopeconfiguration limits blast radius. - Define success metrics before starting: "End-to-end latency stays below 2s" or "Consumer lag recovers within 60 seconds." Without measurable criteria, you can't determine if the experiment succeeded.
- Monitor during experiments: Watch broker metrics, consumer lag, producer error rates, and application logs in real-time. Abort if metrics exceed acceptable thresholds.
- Document findings: Each experiment should produce actionable results: configuration changes, code fixes, or increased confidence in existing resilience.
A typical experiment workflow:
- Define hypothesis: "If 20% of produce requests fail, producer retries will succeed and no messages will be lost"
- Configure interceptor with 20% failure rate on a non-critical topic
- Run load test while monitoring producer success rate and topic message count
- Verify message counts match (no data loss) and producer metrics show retries
- Remove interceptor and document results
Summary
Chaos engineering for Kafka validates that streaming applications survive the failures they'll inevitably encounter in production. Broker outages, latency spikes, leader elections, and message corruption all occur in real deployments. The choice is whether to discover resilience gaps during controlled experiments or during 3 AM incidents.
Proxy-based chaos testing with tools like Conduktor Gateway enables failure injection without infrastructure access, making it practical to run experiments regularly as configurations and applications evolve. Start with the failure scenarios that match your operational experience: if broker restarts have caused issues before, test leader election handling first.
The goal isn't to prove systems are perfectly resilient. It's to find the configuration values, retry policies, and error handling paths that need work before production traffic reveals them.
Related Concepts
- Zero Trust Architecture for Kafka: Security framework where chaos testing validates continuous verification mechanisms
- Chaos Engineering for Streaming Systems: Broader chaos engineering principles for Kafka, Flink, and other streaming platforms
- Disaster Recovery Strategies for Kafka Clusters: Planning for and recovering from cluster-level failures
- Exactly-Once Semantics in Kafka: Understanding delivery guarantees under failure conditions
Sources and References
- Conduktor Gateway Chaos Testing Documentation - Complete reference for chaos interceptors including configuration options and error types
- Apache Kafka Documentation - Design and Reliability Guarantees - Kafka's built-in failure handling and delivery semantics
- Principles of Chaos Engineering - Foundational principles from Netflix's chaos engineering practice
- Rosenthal, C., & Hochstein, L. (2020). Chaos Engineering: System Resiliency in Practice. O'Reilly Media