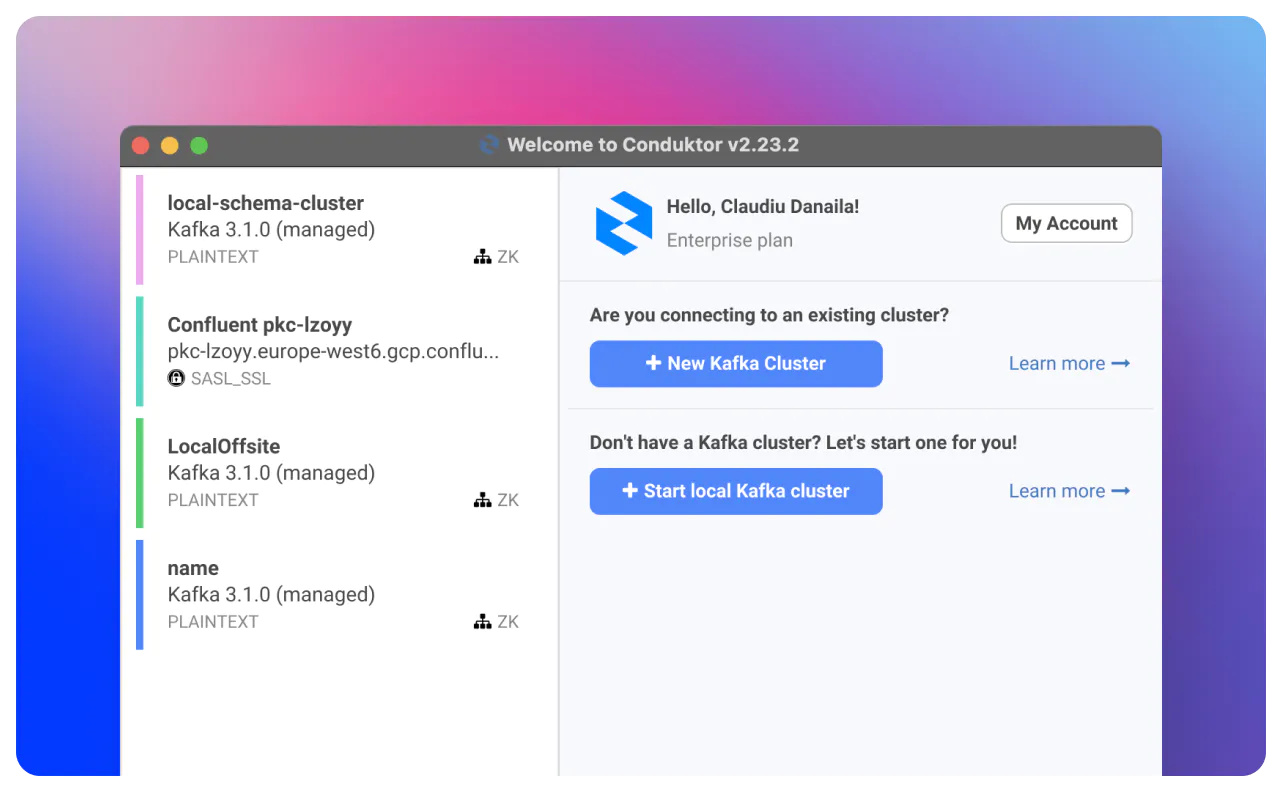
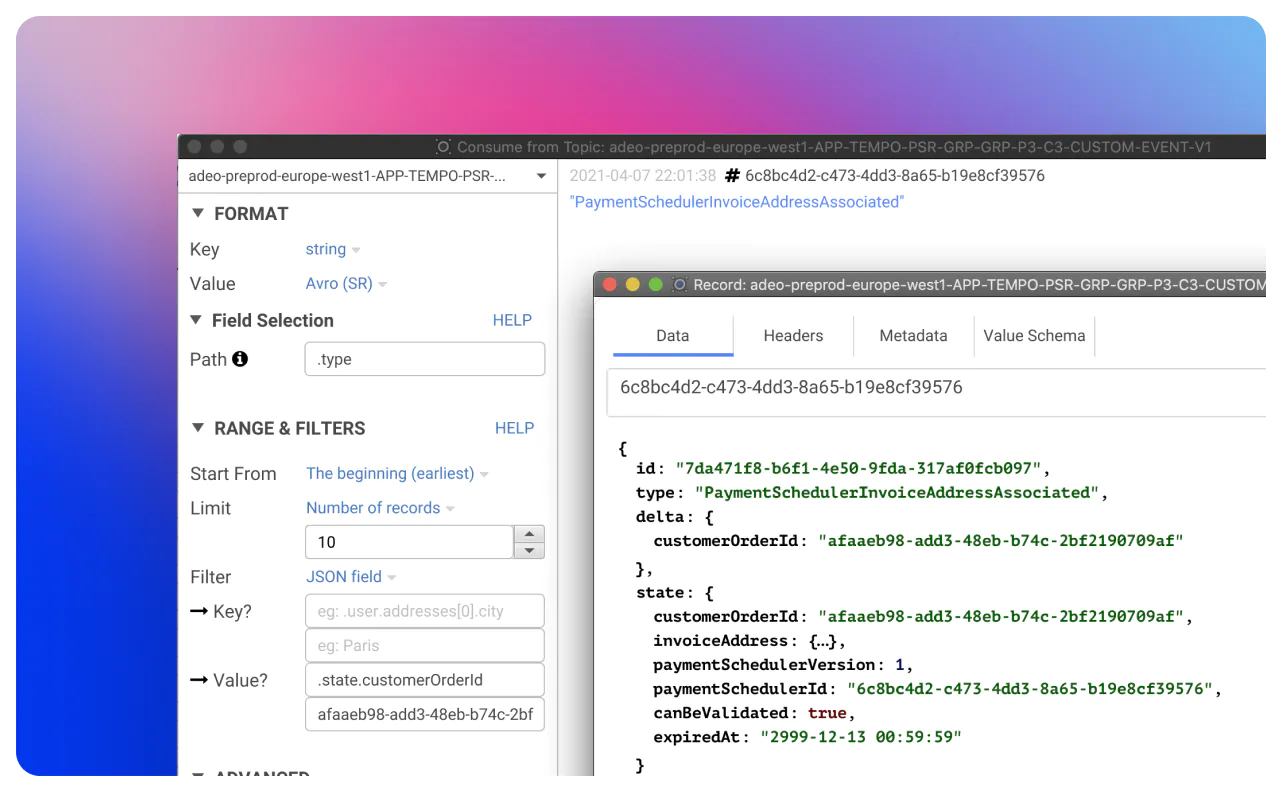
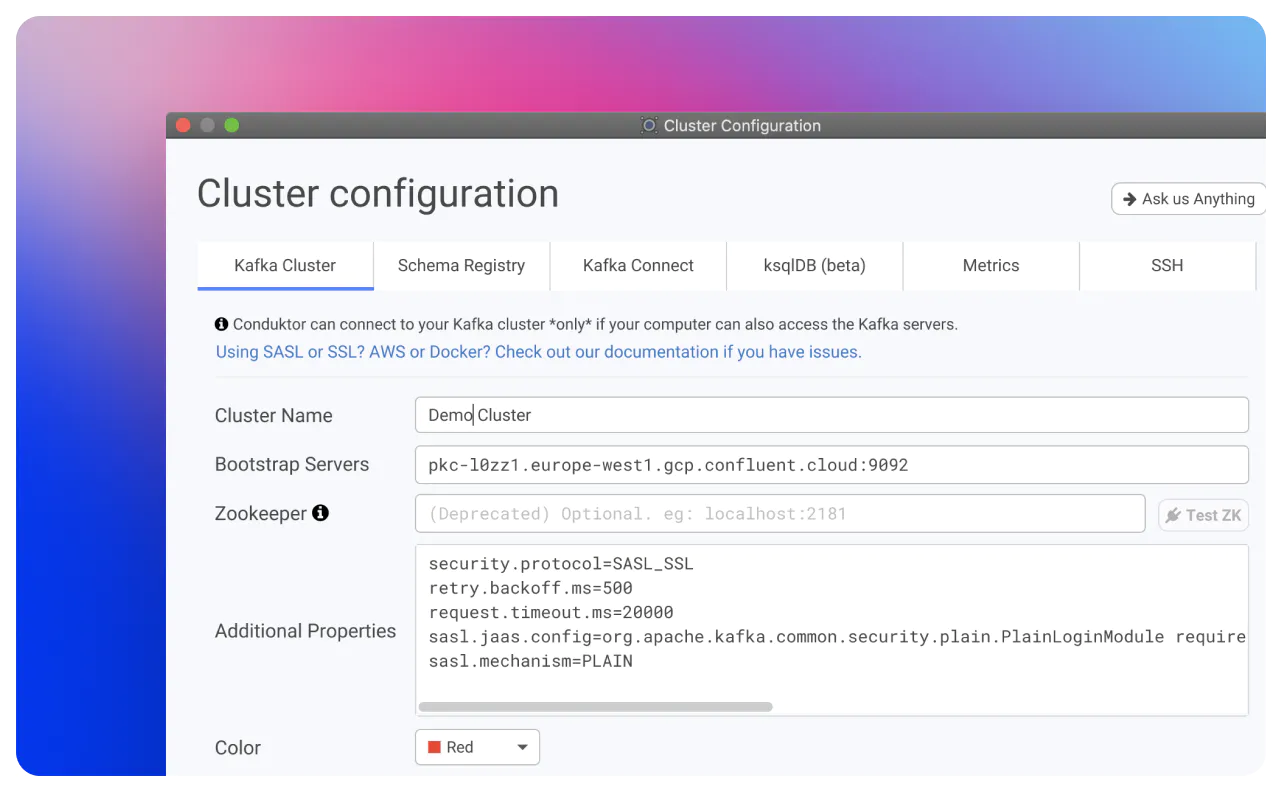
Start Conduktor for free
Explore, govern, and accelerate your Kafka journey with Conduktor Console & Gateway.
Copy the following command to start with Docker or talk to a Kafka expert to discuss your needs.
curl -L https://releases.conduktor.io/quick-start -o docker-compose.yml && docker compose up| Talk to a specialist