# Delivery semantics for Kafka consumers
*Learn how offset commit strategies affect message delivery guarantees*
A consumer reading from a Kafka partition may choose when to commit offsets. That decision controls whether messages are skipped or read twice after a consumer restart.
**What you'll learn:**
- The three delivery semantics: at-most-once, at-least-once, exactly-once
- How to implement each strategy
- When to use each approach
- Best practices for production systems
## Delivery semantics overview

```mermaid
flowchart TD
subgraph AMO["At most once"]
A1["Receive message"] --> A2["Commit offset"]
A2 --> A3["Process message"]
A3 -->|"If fails"| A4["Message LOST"]
end
subgraph ALO["At Least Once"]
B1["Receive message"] --> B2["Process message"]
B2 --> B3["Commit offset"]
B3 -->|"If crash before commit"| B4["Message REPROCESSED"]
end
subgraph EO["Exactly Once"]
C1["Receive message"] --> C2["Process + Commit
in transaction"]
C2 -->|"Atomic"| C3["Message processed
exactly once"]
end
```
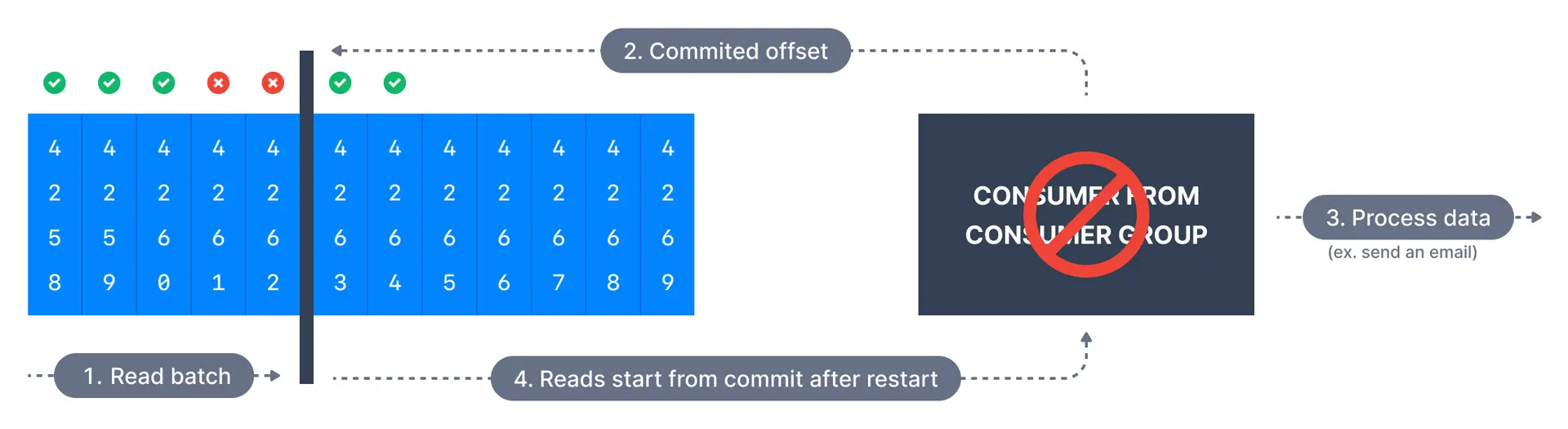
## At most once delivery
In this case, offsets are committed as soon as a message batch is received after calling `poll()`. If the subsequent processing fails, the message will be lost. It will not be read again as the offsets of those messages have been committed already.
```java
// At most once: commit before processing
Properties props = new Properties();
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "0"); // Commit immediately
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
consumer.commitSync(); // Commit first
for (ConsumerRecord record : records) {
process(record); // Then process - if this fails, message is lost
}
}
```
**When to use:**
- Non-critical data (metrics, logs)
- When message loss is acceptable
- When processing duplicates is more problematic than losing data
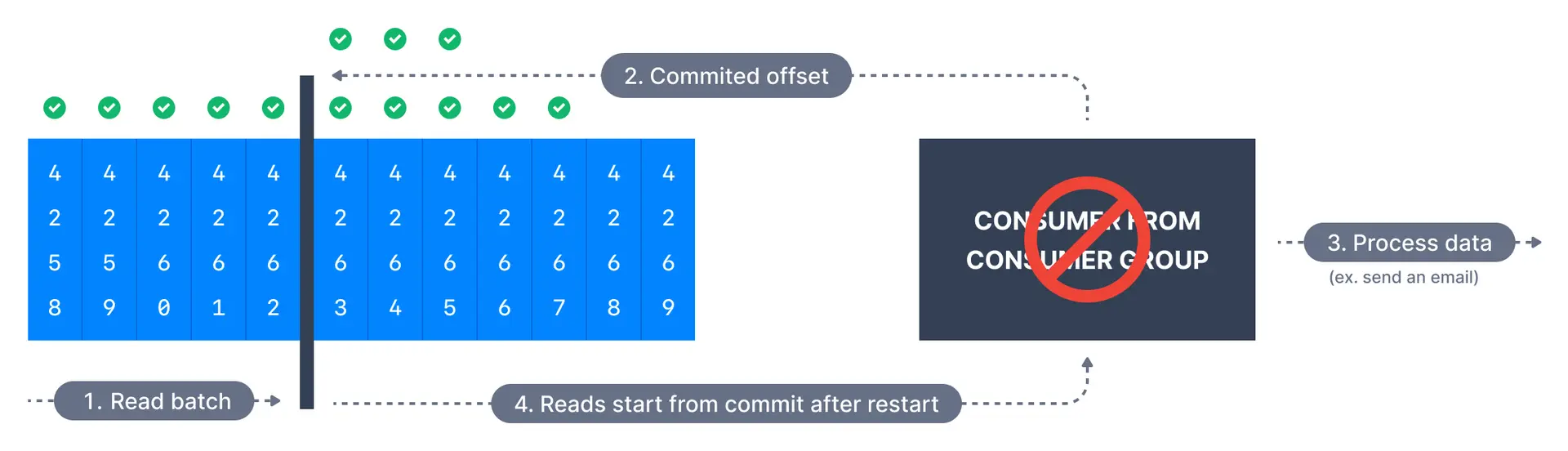
## At least once delivery (usually preferred)
In at-least-once delivery, every event from the source system will reach its destination, but sometimes retries will cause duplicates. Here, offsets are committed after the message is processed.
> **Idempotent Processing**
> Make sure your processing is idempotent (i.e. processing again the messages won't impact your systems)
```java
// At least once: commit after processing
Properties props = new Properties();
props.put("enable.auto.commit", "false");
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
process(record); // Process first
}
consumer.commitSync(); // Then commit - if crash before, messages reprocessed
}
```
**When to use:**
- Most production applications
- When data loss is unacceptable
- When you can handle duplicate processing
### Implement idempotent consumers
| Strategy | How it works | Example |
|----------|--------------|---------|
| **Unique ID check** | Track processed message IDs | Store ID in database before processing |
| **Upsert operations** | Use insert-or-update logic | Database upsert with message key |
| **Conditional writes** | Only write if not exists | Check-then-write with version check |
```java
// Idempotent processing example
void processIdempotently(ConsumerRecord record) {
String messageId = record.key();
// Check if already processed
if (processedIds.contains(messageId)) {
log.info("Skipping duplicate: {}", messageId);
return;
}
// Process the message
doProcessing(record);
// Mark as processed
processedIds.add(messageId);
}
```
## Exactly once delivery
Some applications require exactly-once semantics. Each message is delivered exactly once. This may be achieved in certain situations if Kafka and the consumer application cooperate:
- Achievable for Kafka topic to Kafka topic workflows using the transactions API
- For Kafka topic to External System workflows, use an idempotent consumer
```java
// Exactly once with Kafka Streams
Properties props = new Properties();
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG,
StreamsConfig.EXACTLY_ONCE_V2);
// Or with producer transactions
producer.initTransactions();
try {
producer.beginTransaction();
// ... produce messages ...
producer.sendOffsetsToTransaction(offsets, groupId);
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction();
}
```
**When to use:**
- Financial transactions
- Kafka Streams applications
- Critical data pipelines where duplicates cause problems
## Summary comparison
| Semantic | Commits when | Risk | Complexity | Use case |
|----------|--------------|------|------------|----------|
| At most once | Before processing | Data loss | Low | Metrics, logs |
| At least once | After processing | Duplicates | Low | Most applications |
| Exactly once | With transaction | None (if possible) | High | Financial, critical |
> **Bottom Line**
> For most applications, use 'At Least Once' processing and ensure transformations are idempotent.
## Automatic offset committing strategy
By default, consumers are configured with `enable.auto.commit=true` which means that offsets will be committed automatically on a schedule. This provides at-least-once delivery semantics.
```properties
# Default auto-commit settings
enable.auto.commit=true
auto.commit.interval.ms=5000 # Commit every 5 seconds
```
> **Auto-commit timing**
> With auto-commit, offsets are committed periodically regardless of processing status. If your application crashes after auto-commit but before processing completes, you may lose messages.
## Manual offset committing strategy
You can also choose to control when offsets are committed by setting `enable.auto.commit=false` and using the `commitSync()` or `commitAsync()` methods to manually commit offsets.
```java
// Synchronous commit - blocks until complete
consumer.commitSync();
// Asynchronous commit - non-blocking with callback
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
log.error("Commit failed", exception);
}
});
```
### Commit strategies comparison
| Strategy | Latency | Reliability | Use case |
|----------|---------|-------------|----------|
| `commitSync()` | Higher | Guaranteed | Critical data |
| `commitAsync()` | Lower | Best effort | High throughput |
| Batch + sync | Balanced | Guaranteed | Most applications |
> **See it in practice with Conduktor**
> [Conduktor Console](https://docs.conduktor.io/guide/monitor-brokers-apps) lets you monitor consumer offsets and lag per partition. Track commit progress and identify processing delays to validate your delivery semantics implementation.
## Next steps
- [Configure consumer settings](https://www.conduktor.io/kafka/kafka-consumer-important-settings-poll-and-internal-threads-behavior) for optimal performance
- [Configure auto offset reset](https://www.conduktor.io/kafka/consumer-auto-offsets-reset-behavior) for new consumers
- [Write a Java consumer](https://www.conduktor.io/kafka/complete-kafka-consumer-with-java) with hands-on code