
The Case for Quality
The significance of ‘data’ and ‘events’ in modern systems cannot be refuted. As the production of data has grown exponentially, organisations have shifted towards architectures that can more effectively process large volumes of data with millisecond latency.
“In 2021, there were more than 10 billion active IoT devices” - source
We refer to these methods of system design as EDAs (event-driven architectures), or microservices architecture. At their core, they depend on a messaging backbone, which is often chosen to be Apache Kafka. This messaging backbone is responsible for delivering information between interlinked services. It also helps to decouple components within the system, empowering teams to own, scale and improve their ‘piece’ of the overall system with less dependencies.
With Kafka forming a fundamental part of systems that are often responsible for real-time decision making, it’s more important than ever to establish a robust testing framework. Such a framework will ensure you maintain product quality, reduce the risk of broken contracts, and can even eliminate the possibility of a production failure. But with distributed architectures and huge volumes of data, this can be a daunting task for even the most seasoned Apache Kafka expert. In this post, we’ll explore some methods you can use to test components within your Apache Kafka architecture.
Manual Testing
Suppose we want to collect geospatial data from those 10 billion IoT devices previously mentioned. The first step would be to create a Kafka topic and validate that we can produce and consume messages from it accordingly.
Kafka CLI
Let’s assume we’ve already started Kafka. If you’re unsure how to do this, I recommend visiting Conduktor Kafkademy for step-by-step instructions.
Using the Kafka Topics CLI, we can create a geo_events topic with 3 partitions and a replication factor of 1 via a Kafka broker running at localhost:9092.
$ kafka-topics.sh --bootstrap-server localhost:9092 --topic geo_events --create --partitions 3 --replication-factor 1
Great, now that our Kafka topic is created we can produce a sample record as a manual test. To do this, we utilize the Kafka producer CLI:
$ kafka-console-producer.sh --bootstrap-server localhost:9092 --topic geo_events > {"timestamp":"1647515491", "deviceId":"1234-e4b6-5678", "latLong":"38.8951,-77.0364"}
Finally, let’s use the Kafka consumer CLI to read data from our topic, confirming that we can collect our geospatial messages. We will use the --from-beginning option to consume all historical messages, which should include the sample produced in our prior step.
$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic geo_events --from-beginning > {"timestamp":"1647515491","deviceId":"1234-e4b6-5678", "latlong":"38.8951,-77.0364"}
Job done! To summarise, we’ve created a topic and manually tested that we can produce and consume data accordingly. That being said, the keyword here is ‘manual’. This might be sufficient for ad-hoc debugging, but not for something continuous and automated. Additionally, writing those commands was cumbersome for such basic functionality. Surely this can be achieved more easily?
Kafka GUIs
Not all users that need to interact with and test Apache Kafka data are comfortable utilizing CLI tools. Perhaps I’m a data analyst that needs only to sample some messages, or a QA engineer with no prior Kafka experience. In these cases, a GUI is your friend. Equally, they can increase the productivity of the most seasoned developers when it comes to everyday Kafka tasks.
The Conduktor DevTools GUI has a rich feature set to support manual testing. Not to mention it supports starting a Kafka cluster in seconds at the click of a button. To revisit our previous example, below demonstrates how to use the producer interface to push messages into the geo_events topic.

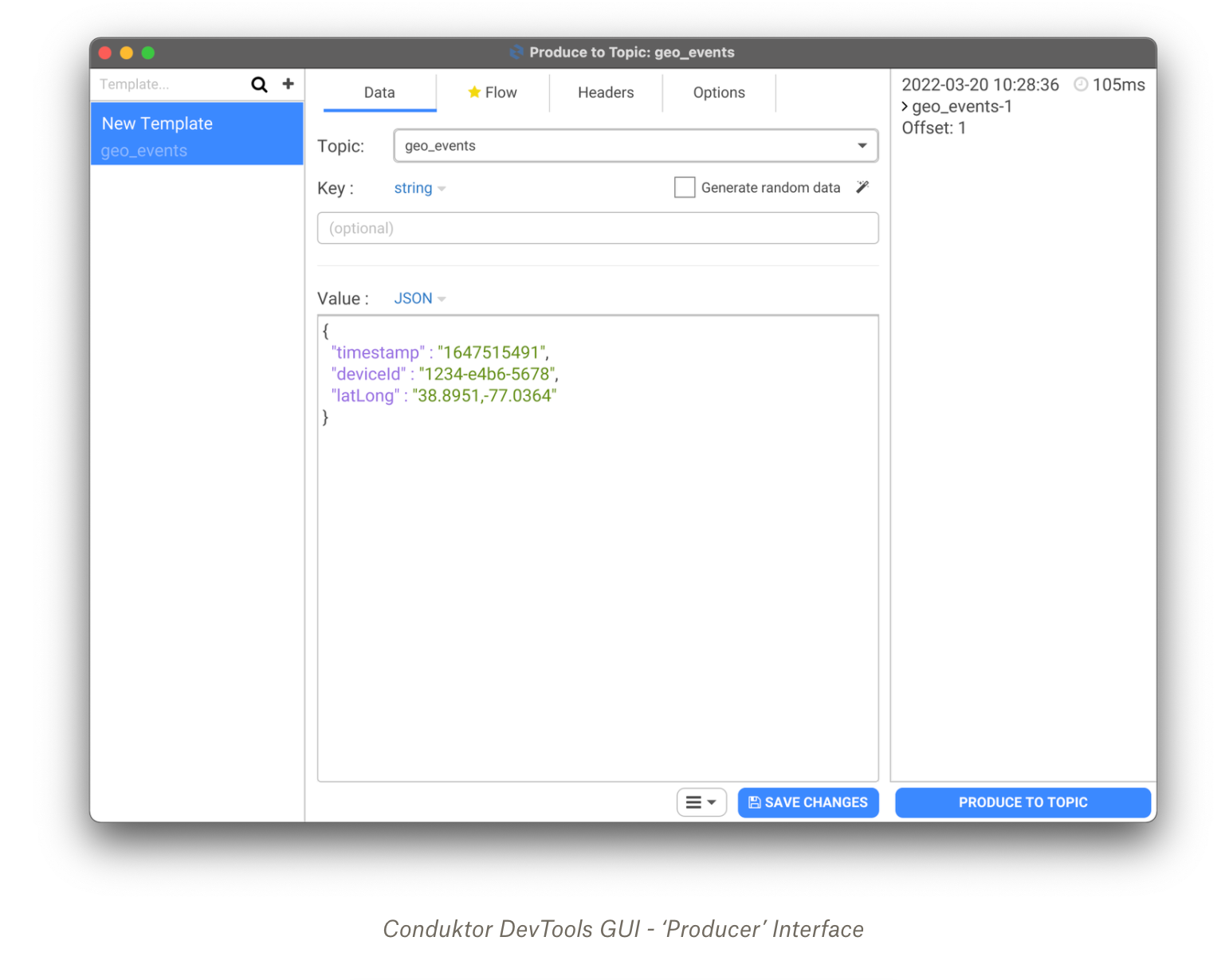
Not only can we forget about the Kafka CLI syntax, but we also gain new functionality such as ‘Flow’. This enables you to produce an automated stream of events with interval rules and lifecycle options. Already, you get an idea of how much more powerful our manual testing efforts can be.
The best part, we needn’t create any additional scripts. By simply navigating the options in the GUI, we can append headers to our messages, produce randomized data and configure settings such as acks (acknowledgements). This supports testing under more technical conditions. Pretty neat, right?
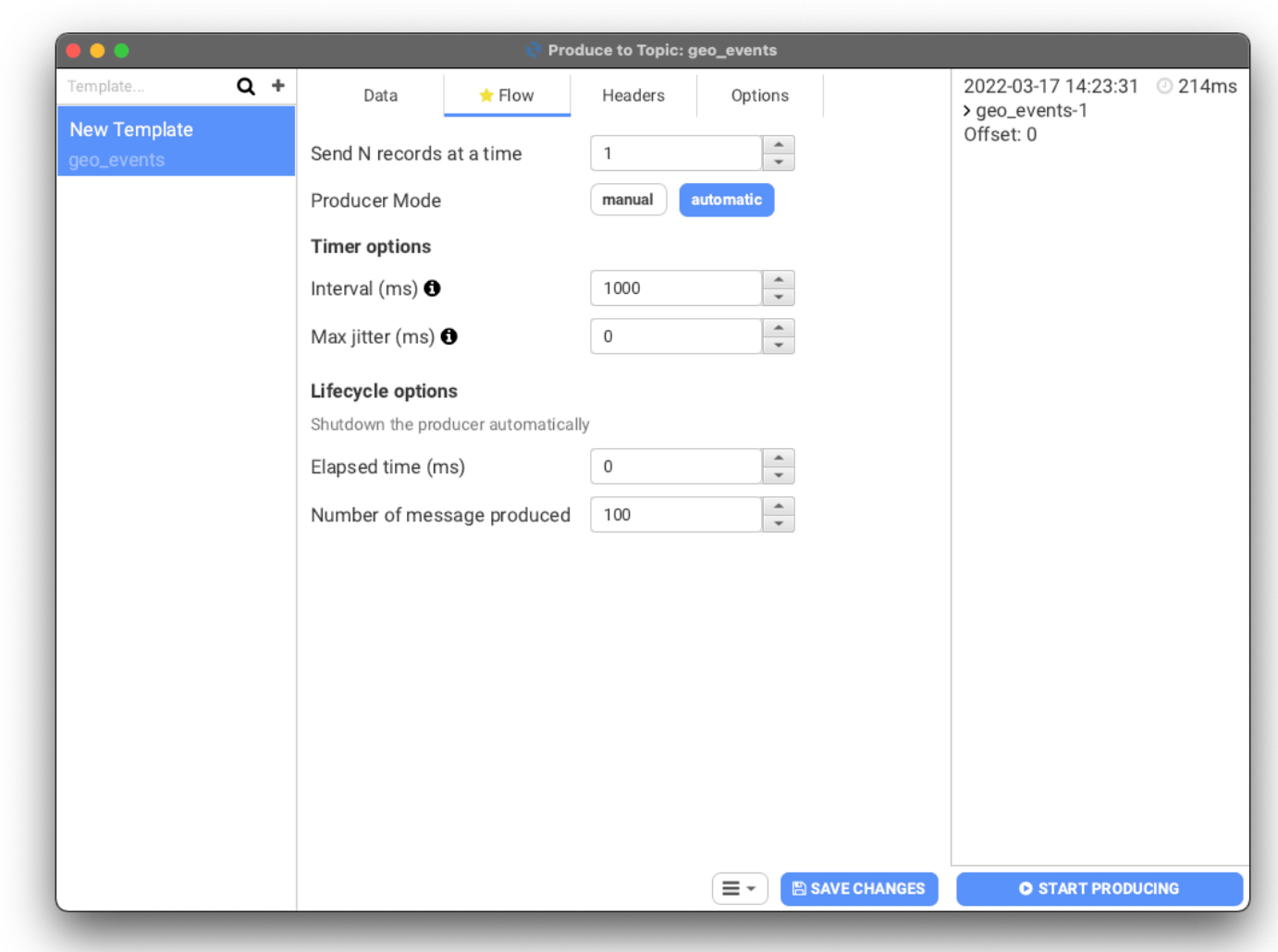
As for the consumption side of manual testing, there are complementary features whereby you might otherwise have to refer to a Kafka CLI cheat sheet. For example, configuring different consumption strategies, limiting the records you consume, or filtering your messages to intercept those that match certain criteria. Most importantly, your event stream will be displayed in an easily readable table that also surfaces record metadata.
While Kafka GUIs help advance our manual testing efforts, there are limits to how far we can go. Most organizations are now dependent on continuous integration and continuous delivery, therefore we need a mechanism for automated testing that can form part of the SDLC (software development lifecycle).
Integration Testing with Testcontainers
Advancing from our manual testing efforts, Testcontainers is a Java library that can be used to instantiate disposable Kafka containers via Docker. They provide ports for other languages such as Python and Go, and containers for other common databases such as Postgres and MySQL.

One of the challenges we face with integration testing is ensuring that all dependencies are available for our test to run. Essentially, we want to replicate a ‘realistic’ environment for the test execution, and we want it to be available on demand. This is particularly relevant when we want to integrate tests in our CI pipeline.
For distributed systems that are dependent on Kafka, Testcontainers helps us spin up a cluster for the lifetime of an integration test. This means our Kafka is disposed of when the execution completes. To instantiate our Kafka container we can parse a Confluent docker image.
1DockerImageName KAFKA_TEST_IMAGE = DockerImageName.parse("confluentinc/cp-kafka:6.2.1");
2KafkaContainer kafkaContainer = new KafkaContainer(KAFKA_TEST_IMAGE);Once our Kafka broker is up and running, we are free to execute our integration tests. Safe in the knowledge that we have a self-contained environment that’s not being shared with other teams. In a single script, it’s now possible to automate the process of creating our geo_events topic, producing some sample records, consuming them, and asserting the data. You can find an example class in the Testcontainers repository. Below shows an adaptation for our use case.
1@Test
2public void testUsage() throws Exception {
3 try (KafkaContainer kafka = new KafkaContainer(KAFKA_TEST_IMAGE)) {
4 kafka.start();
5 testKafkaFunctionality(kafka.getBootstrapServers());
6 }
7}
8protected void testKafkaFunctionality(String bootstrapServers) throws Exception {
9 testKafkaFunctionality(bootstrapServers, 1, 1);
10}
11protected void testKafkaFunctionality(String bootstrapServers, int partitions, int rf) throws Exception {
12 try (AdminClient adminClient = AdminClient.create(ImmutableMap.of(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers)); KafkaProducer < String, String > producer = new KafkaProducer < > (ImmutableMap.of(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers, ProducerConfig.CLIENT_ID_CONFIG, UUID.randomUUID().toString()), new StringSerializer(), new StringSerializer()); KafkaConsumer < String, String > consumer = new KafkaConsumer < > (ImmutableMap.of(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers, ConsumerConfig.GROUP_ID_CONFIG, "tc-" + UUID.randomUUID(), ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"), new StringDeserializer(), new StringDeserializer());) {
13 String topicName = "geo_events";
14 String messageValue = "{\"timestamp\":\"1647515491\",\"deviceId\":\"1234-e4b6-5678\",\"latLong\":\"38.8951,-77.0364\"}";
15 Collection < NewTopic > topics = singletonList(new NewTopic(topicName, partitions, (short) rf));
16 adminClient.createTopics(topics).all().get(30, TimeUnit.SECONDS);
17 consumer.subscribe(singletonList(topicName));
18 producer.send(new ProducerRecord < > (topicName, null, messageValue)).get();
19 Unreliables.retryUntilTrue(10, TimeUnit.SECONDS, () -> {
20 ConsumerRecords < String,
21 String > records = consumer.poll(Duration.ofMillis(100));
22 if (records.isEmpty()) {
23 return false;
24 }
25 assertThat(records).hasSize(1).extracting(ConsumerRecord::topic, ConsumerRecord::key, ConsumerRecord::value).containsExactly(tuple(topicName, null, messageValue));
26 return true;
27 });
28 consumer.unsubscribe();
29 }
30}There are clear benefits of using Testcontainers for Kafka. Primarily, it provides an on-demand testing environment that we do not need to maintain or govern. Additionally, we can embed testing in the software development lifecycle. This ensures that test executions are a pre-requisite to code being deployed.
For all the positives, there are potential organizational challenges that come with utilizing Testcontainers. It’s a very developer-oriented approach, which assumes deep understanding of Kafka and its architecture. The best testing cultures encourage co-operation across product managers, data analysts, QA engineers, and developers. With no UI to support understanding, reporting, or orchestration of tests, this could reflect a technical barrier to adoption en masse.
Kafka Streams Test Utilities
Kafka Streams is a frequent choice for real-time stream processing. It’s a service where business logic is likely to be injected into Kafka-based applications. For example, a stateless operation like filtering a stream, or a stateful operation such as a windowed aggregation. To support testing of Streams applications, Kafka provides a test-utils artifact.
The test-utils package provides a TopologyTestDriver that can be used pipe data through a Topology … You can use the test driver to verify that your specified processor topology computes the correct result with the manually piped in data records - Source
To elaborate on the official Kafka documentation, the package enables us to produce messages to a mocked input topic, apply our computational logic (Topology), and check the result in a mocked output topic. The advantage here? We don’t need to depend on an embedded or external Kafka cluster.
Let’s revisit our geospatial data, and see how we can test a simple Streams application. Suppose we want to filter the geo_events topic for messages containing a specific deviceId.
1public static Topology filterStream() {
2 StreamsBuilder builder = new StreamsBuilder();
3 KStream < String, String > stream = builder.stream(INPUT_TOPIC);
4 stream.filter((k, v) -> v.contains("1234-e4b6-5678")).to(OUTPUT_TOPIC);
5 return builder.build();
6}Using the above topology to filter our stream, we can create a test case that will pipe data in from two different deviceId’s. We will then assert the outputs, validating that only the expected output, messageValid, reaches the outputTopic.
1@Test
2public void shouldFilterRecords() {
3 topology = App.filterStream();
4 td = new TopologyTestDriver(topology, config);
5 inputTopic = td.createInputTopic(App.INPUT_TOPIC, Serdes.String().serializer(), Serdes.String().serializer());
6 outputTopic = td.createOutputTopic(App.OUTPUT_TOPIC, Serdes.String().deserializer(), Serdes.String().deserializer());
7 String messageValid = "{\"timestamp\":\"1647515491\",\"deviceId\":\"1234-e4b6-5678\",\"latLong\":\"38.8951,-77.0364\"}";
8 String messageInvalid = "{\"timestamp\":\"1647799800\",\"deviceId\":\"9876-e1p3-6763\",\"latLong\":\"51.5072,0.1276\"}";
9 assertThat(outputTopic.isEmpty(), is(true));
10 inputTopic.pipeInput(null, messageValid);
11 assertThat(outputTopic.readValue(), equalTo(messageValid));
12 assertThat(outputTopic.isEmpty(), is(true));
13 inputTopic.pipeInput(null, messageInvalid);
14 assertThat(outputTopic.isEmpty(), is(true));
15}Great, so we have demonstrated that our filter logic is behaving as expected. In the first case, our message contains the desirable deviceId and we assert that it reaches the outputTopic. In the second case, when piping messageInvalid into our topology, we're able to verify that no message is produced in outputTopic.
The lightweight and readable nature of test-utils make the package a great asset for unit testing Kafka Streams applications. The provided input is processed synchronously and without external system dependencies. This makes it very straightforward to confirm your Topology is producing the desired results.
However, there is one major drawback. Because the process does not spin up a real Kafka, it makes it impossible to work with external applications to test dependencies. This limits how far our testing efforts can go with this method alone.
Testing ksqlDB Applications
If you're more accustomed to working with relational databases, the simplicity of using ksqlDB for stream processing will have been attractive. Much like Kafka Streams, it’s another service where business logic is applied to produce a desired output. Therefore, it’s important that we have a mechanism for testing the behavior of a ksqlDB application. There are two options in this space, and we will briefly discuss both of them.
ksqlDB Test Runner CLI Tool
The ksqlDB test runner depends on three files to validate the stream processing logic.
‘statements.sql’ should contain your SQL statements
‘input.json’ and ‘output.json’ to describe the input data and the expected output
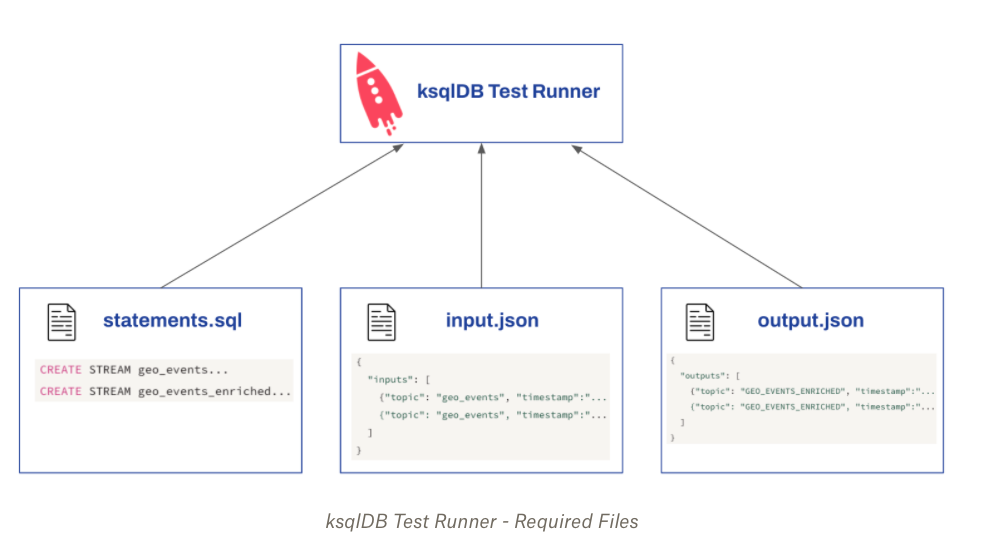
Similar to Kafka Streams test utilities, we do not require a running Kafka or ksqlDB cluster to execute these tests. The command line tool will take care of the evaluation and display a success or failure message in the terminal.
Perhaps we want to create an alias for certain IoT devices (e.g. a driver name that’s associated with the device), we could create that logic using ksqlDB:
1CREATE STREAM geo_events (
2 TIMESTAMP VARCHAR, DEVICEID VARCHAR,
3 LATLONG VARCHAR
4) WITH (
5 KAFKA_TOPIC = 'geo_events', VALUE_FORMAT = 'JSON'
6);
7CREATE STREAM geo_events_enriched AS
8SELECT
9 TIMESTAMP,
10 DEVICEID,
11 LATLONG,
12 CASE WHEN DEVICEID = '1234-e4b6-5678' THEN 'Joe Bloggs' WHEN DEVICEID = '9876-e1p3-6763' THEN 'Jane Doe' ELSE 'Unknown' END AS DRIVERNAME
13FROM
14 geo_events EMIT CHANGES;Next, we could define our input data (input.json):
1{
2 "inputs": [
3 {
4 "topic": "geo_events",
5 "timestamp": 1647515491,
6 "value": {
7 "TIMESTAMP": "1647515491",
8 "DEVICEID": "1234-e4b6-5678",
9 "LATLONG": "38.8951,-77.0364"
10 }
11 },
12 {
13 "topic": "geo_events",
14 "timestamp": 1647799800,
15 "value": {
16 "TIMESTAMP": "1647799800",
17 "DEVICEID": "9876-e1p3-6763",
18 "LATLONG": "51.5072,0.1276"
19 }
20 }
21 ]
22}Lastly, the expected output of our records post-enrichment (output.json). This is inclusive of the enriched values that are added via the CASE statement in our 'statements.sql' file:
1{
2 "outputs": [
3 {
4 "topic": "GEO_EVENTS_ENRICHED",
5 "timestamp": 1647515491,
6 "value": {
7 "TIMESTAMP": "1647515491",
8 "DEVICEID": "1234-e4b6-5678",
9 "LATLONG": "38.8951,-77.0364",
10 "DRIVERNAME": "Joe Bloggs"
11 }
12 },
13 {
14 "topic": "GEO_EVENTS_ENRICHED",
15 "timestamp": 1647799800,
16 "value": {
17 "TIMESTAMP": "1647799800",
18 "DEVICEID": "9876-e1p3-6763",
19 "LATLONG": "51.5072,0.1276",
20 "DRIVERNAME": "Jane Doe"
21 }
22 }
23 ]
24}Finally, all that would be required is to execute the test via the ksqlDB test runner
ksql-test-runner -s statements.sql -i input.json -o output.json
In the case of a failure, the terminal will provide insight into the actual output versus the expected output. However, in this case, our test is successful and the output will confirm this:
>>> Test passed!
Testing ksqlDB via Postman
Another option for testing ksqlDB applications is to use a REST client. Postman provides a GUI that reduces some of the complexities of interacting with the ksqlDB server. Using Postman, it’s possible to inspect stream metadata, select data, and insert data using SQL statements.
Assuming your ksqlDB server is started locally on port 8088, you can configure a POST request to the below endpoint. Note you may need to update the proxy settings in the Postman application.
http://localhost:8088/ksql
Next, you can add your SQL statements in the body of the request. Below demonstrates how to retrieve metadata about created streams.
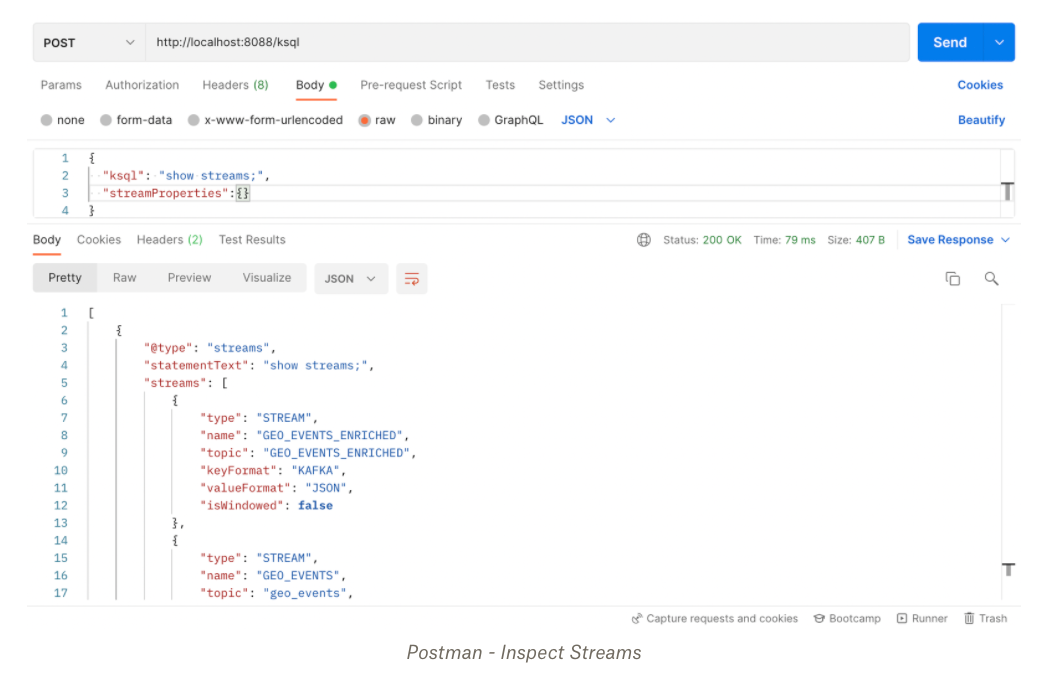
Assuming we want to insert a record into our geo_events topic, we could amend the KSQL statement accordingly:
1{
2 "ksql": "INSERT INTO GEO_EVENTS VALUES('1647515491', '1234-e4b6-5678', '38.8951,-77.0364');",
3 "streamProperties": {}
4}There are significant limitations to how far your testing efforts can go using ksqlDB and REST clients. The Postman sandbox is a JavaScript environment and is generally single-threaded (meaning it can only process one command at a time). These efforts are once again manual and better suited only for ad-hoc debugging.
Conclusion
As we have demonstrated, testing different components within our Apache Kafka architecture is more than possible. At times, it does feel like the process is manual, fragmented, or even incomplete. Not to mention it comes with a degree of learning and ramp-up to familiarise yourself with the different approaches.
To build a robust testing culture, it’s important that business people, QA engineers, and developers work together. These minds think differently; while an engineer might be concerned about working code, a product manager is more likely to think about the end users’ experience. Only together can they ensure complete coverage of testable scenarios through appropriate business rules.
At Conduktor, we think there is an opportunity to do better in this space. Our aim is to provide intelligent and complementary tooling that simplifies complex and mundane operational tasks relating to the Kafka ecosystem. That’s why we’re working on a game-changing new product to supercharge test automation and quality management of Kafka-based architectures.
If you'd like to see for yourself, get Conduktor for free.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.