
From the release of Apache Kafka 2.8.0, users have had early access to KIP-500, which removes the Zookeeper dependency from Kafka. The release of Apache Kafka 3.3.0 saw KIP-500 become production-ready, meaning Kafka now relies on an internal Raft quorum that uses a Kafka Topic to store metadata, and some Kafka servers act as Controllers. The new feature simplifies cluster administration and infrastructure management and makes the Kafka cluster more scalable.
In this article, we’ll first discuss what Zookeeper is. Next, we'll see what its role is in Kafka. Finally, what are the limitations of Zookeeper, and how does KRaft mode mitigate those limitations?
Zookeeper in Kafka
What is Zookeeper
Zookeeper is a service for maintaining configurations, naming, and distributed synchronization. Zookeeper allows distributed processes to coordinate with each other through zNodes. The performance aspects of Zookeeper allow it to be used in large distributed systems. The reliability aspects prevent it from becoming the single point of failure in big systems. Its strict ordering allows sophisticated synchronization primitives to be implemented at the client.
The main difference between Zookeeper and standard file systems is that every zNode can have data associated with it.
Zookeeper was designed to store coordination data: status information, configuration, location information, etc. This kind of meta-information is usually measured in kilobytes, if not bytes.
Zookeeper provides multiple features for distributed systems:
Distributed configuration management
Self-election / Consensus building
Coordination and locks
Key value store

The service itself is replicated over a set of machines that comprise it. These machines maintain an in-memory image of the data tree along with transaction logs and snapshots in a persistent store. Because the data is kept in memory, Zookeeper is able to get very high throughput and low latency numbers. The downside to an in-memory database is that the size of the database that Zookeeper can manage is limited by memory.
As long as a majority of the servers are available, the Zookeeper service will be available.
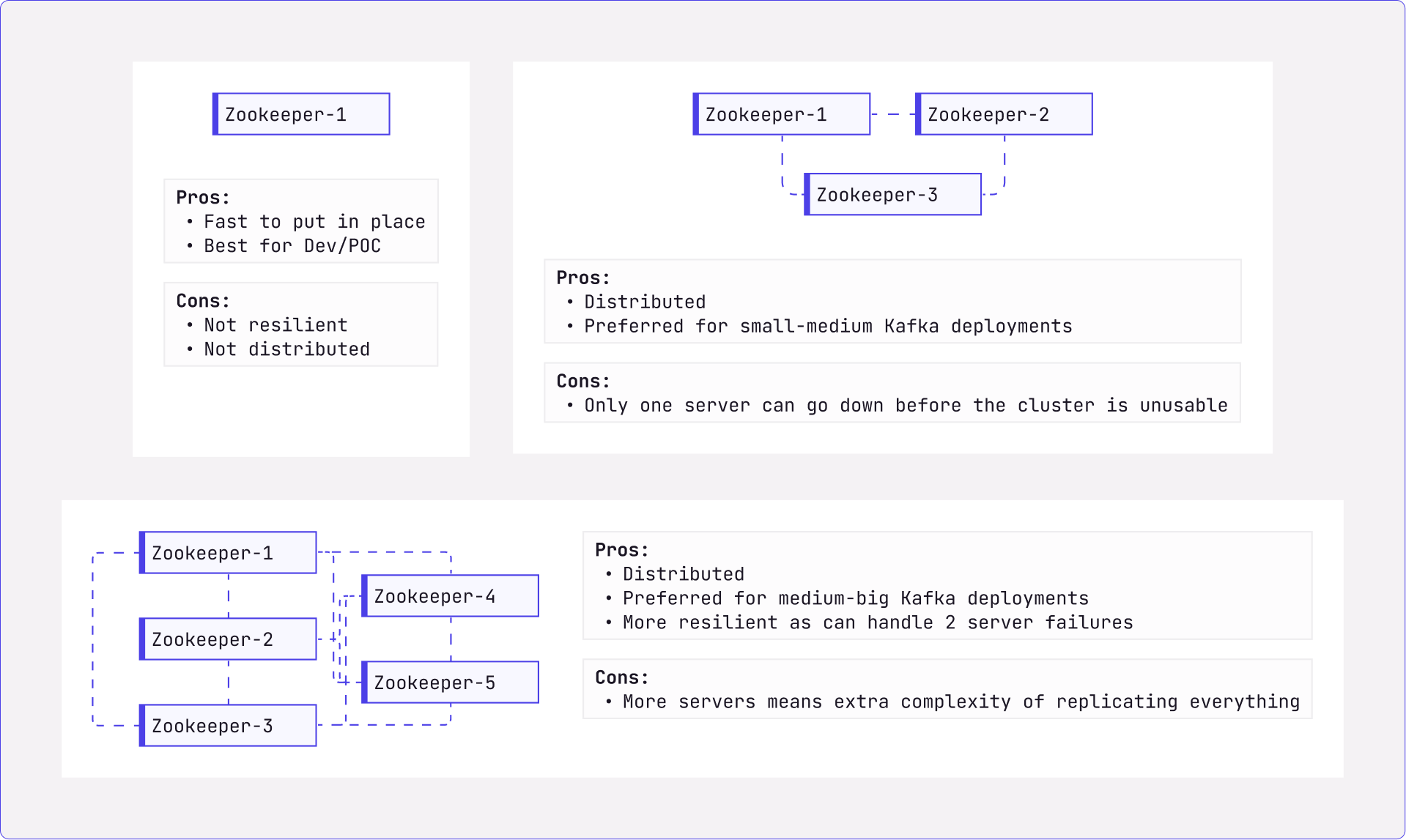
Zookeeper Quorum
Zookeeper needs to have a strict majority of servers to form a consensus when votes happen. Therefore a Zookeeper quorum can have 1, 3, 5, 7, and up to (2N+1) servers. This allows 0, 1, 2, 3, and N servers to go down without making the cluster unusable.
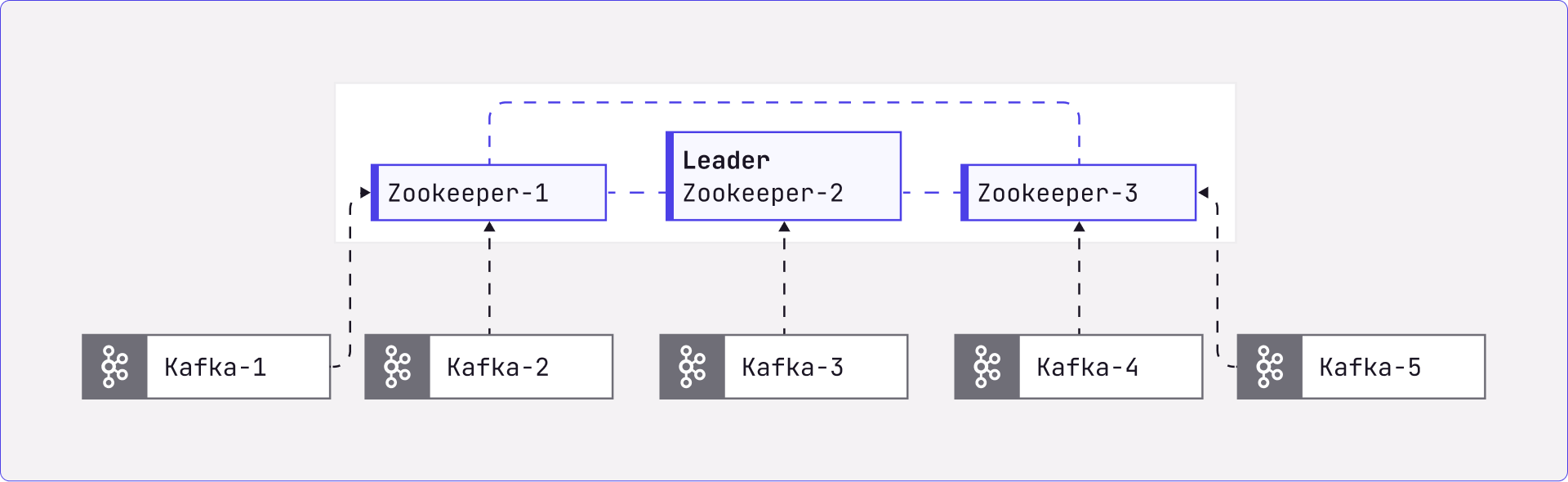
Role of Zookeeper in Kafka
Here are the things Zookeeper does for Kafka; actually, for any distributed system-
Brokers registration, with a heartbeat mechanism to keep the broker list updated
Maintaining metadata of topics
Topic configuration (partitions, replication factor, additional configs, etc.)
The list of in-sync replicas for partitions
Performs leader election for all partitions
Store metadata of Access Control Lists (ACLs), if security is enabled
Topics
Consumer Groups
Users
Store the Kafka cluster-id (randomly generated while the Broker registers the first time)
Zookeeper: Limitations and Challenges
Zookeeper seems an inseparable part of running a distributed system like Kafka but it has some limitations which are preventing Kafka from working to its full potential.
Let’s discuss some of those challenges here-
Two different systems - Zookeeper is an external system to Kafka which means that it comes with its own configuration syntax, management tools, etc. Therefore, if you want to deploy a Kafka cluster then you would also have to manage, deploy, and monitor Zookeeper as well.
Error Prone- These two distributed systems require different configurations and the level of complexity increases, thus it is much easier for system administrators to make mistakes.
Duplication of work- Having two systems also leads to duplication of work— for example, in order to enable security features you would have to apply the relevant configuration to both services.
Additional Processes- Having an external metadata store is inefficient regarding resources as you need to run additional processes.
Limits Kafka Scalability- With Zookeeper, Kafka scalability is limited. Every time the cluster is starting up, the Kafka controller must load the state of the cluster from Zookeeper.
Fewer Partitions in the Cluster- The same happens when a new controller is elected. Given that the amount of metadata gets bigger over time, this means that the loading of such metadata becomes more inefficient over time and thus limiting the number of partitions the cluster can store.
The Zookeeper-based Kafka controller loads all the metadata synchronously on startup and during this time the cluster is unavailable. Also, it has to send all metadata to all the brokers.
KRaft - Kafka Raft
To overcome the challenges of Zookeeper in Kafka, a KIP (Kafka Improvement Plan) was submitted for Zookeeper-less Kafka (KIP-500) and version 2.8.0 introduced early access to Zookeeper-less Kafka, with KRaft becoming production-ready in version 3.3.0. In the latest release, ZooKeeper can be replaced by an internal Raft quorum of controllers.
How does it Work?
When Kafka Raft Metadata mode is enabled, Kafka will store its metadata and configurations into an internal topic called __cluster_metadata. This topic has a single partition and the leader will be on the active controller. This internal topic is managed by the internal quorum and replicated across the cluster. The nodes of the cluster can now serve as brokers, controllers, or both (called combined nodes).
When KRaft mode is enabled, only a few selected servers can serve as controllers and these will compose the internal quorum. The controllers can either be in active or standby mode which will eventually take over if the currently active controller server fails or is taken down.
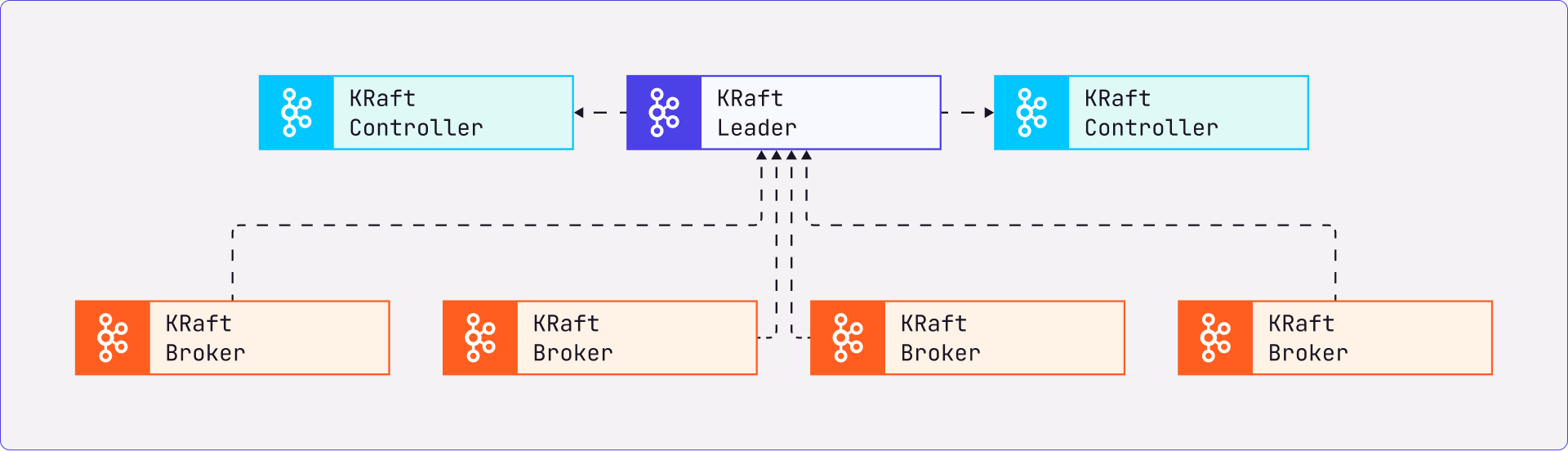
As we can see in the above diagram, Zookeeper nodes are replaced by KRaft Controllers. The starting up of the controllers will have the following process-
Some Kafka Brokers will be designated as KRaft controllers
These controllers will elect a leader
The leader will have all previously committed records
Kafka brokers will fetch metadata from this KRaft leader.
Now every Kafka server comes with an additional configuration parameter called process.roles. This parameter can take the following values:
broker: The Kafka server shall serve as a broker
controller: The Kafka server shall serve as a controller of the internal Raft quorum
broker,controller: The Kafka server shall serve as both a controller of the quorum and a broker
When process.roles is not configured, it is assumed that the cluster will run in Zookeeper mode.
How does it overcome the challenges with Zookeeper?
Now let’s discuss how KRaft mode can overcome some of the challenges with Zookeeper.
Scenario | With Zookeeper | Problem | Solution: with KRaft |
Controller Failover | After a controller wins the election, it fetches all the topics and partitions and sends LeaderAndISR and UpdateMetaData to all the brokers | Let’s consider you have a huge cluster with lots of partitions: this process can take a lot of time and the cluster will be unavailable during this time | With KRaft mode, once a controller wins the election it starts getting the request from the brokers so there’s no wait time on loading all the topics, etc. again |
Node Restart | A rolling node starts with no metadata and can only be available once it fetches all the metadata | Fetching metadata can take longer when there are many partitions available in the cluster, which will make the node become unavailable for some time | With KRaft mode, the rolling node needs to fetch only the metadata that it doesn’t have in its local cache. It does so using the metadata offset |
Zookeeper Dependency | Kafka and ZooKeeper are two distinct services, so in order to administer a Kafka cluster one needs to understand how Zookeeper works as well | Understanding of additional service i.e. Zookeeper. One has to set up security, monitoring, etc. for Zookeeper as well in order to secure the cluster | With KRaft mode, Kafka has been unified and it is not dependent on Zookeeper to store the metadata. The learning curve will be shortened and engineers can now focus only on Kafka |
Scalable Architecture | In ZooKeeper mode, Kafka had to store its metadata in zNodes. Every time the cluster was starting up or a controller election was happening, Kafka Controllers had to read all the metadata from the Zookeeper service which was inefficient | Cluster unavailability during the fetching of metadata resulting in hosting limited partitions per cluster | With KRaft mode, deployments can now support more partitions |
Easy Setup | One has to configure Zookeeper as well in order to run Kafka. This is required even for doing a small proof of concept | Running extra services even for a small setup | With KRaft mode, you no longer have to start multiple processes |
Migration Strategy: Zookeeper to KRaft
Starting with KRaft is easy and one can setup the Kafka cluster in no time, but what about when the existing cluster runs with Zookeeper? How will the migration happen? What would be the operational changes required?
Answers to all these questions are available in KIP-866. This Kafka Improvement Plan lists the approach to migrate from Zookeeper quorum to Raft quorum without any impact to partition availability and with minimal impacts on operators and client applications. The implementation will be available as early access starting from Apache Kafka version 3.4.0 (Check the Release plan).
Migration itself is a vast topic and still under development but the following are the steps to migrate from Zookeeper to Raft quorum-
Preparing the cluster - Upgrade the cluster to the version where migration-related implementation is available. This release will have additional configurations required by Zookeeper and Kraft Controllers in order to communicate with each other during the migration phase.
Controller migration - The migration only supports dedicated KRaft controllers as the target deployment. A new set of nodes will be provisioned to host the controller quorum.
Broker Migration - The brokers are restarted one by one in KRaft mode. During this rolling restart, if anything is not correct there will be an option to roll back the brokers in Zookeeper mode.
Finalizing the Migration - Once the cluster has been fully upgraded to KRaft mode, the controller will still be running in migration mode and making dual writes to KRaft and ZK. Once the operator has decided to commit to KRaft mode, the final step is to restart the controller quorum and take it out of migration mode by setting zookeeper.metadata.migration.enable to "false" (or unsetting it)
Conclusion
The removal of Zookeeper dependency is a huge step forward for Kafka. The new KRaft mode feature will extend the scalability capabilities of Apache Kafka and also shorten the learning curve since now teams won’t have to worry about ZooKeeper any longer. Now, system administrators will find it easier to monitor, administer, and support Kafka. Developers will have to deal with a single security model for the whole system. Moreover, we have a lightweight single-process deployment to get started with Kafka.
The roadmap for Kafka Raft and Zookeeper removal-
Kafka Version | Release Summary(for KRaft and Zookeeper) |
2.8.0 | First KRaft Release (For development and POC purposes) |
3.3.0 | KRaft is now Production-ready with this version |
3.4.0* | Upgrade from Zookeeper (early access) |
3.5.0* | Zookeeper mode will be deprecated |
4.0.0* | Removal of Zookeeper mode |
* Denotes future versions
For users of Conduktor Platform, all versions of Apache Kafka continue to be supported, meaning you can continue to use Zookeeper quorum, or switch to Raft quorum without any issues. If you haven't yet tried Conduktor Platform, you can sign up for free and try it out now. If you don't want to put up with the hassle of Zookeeper, why accept any Kafka flaws when you don't have to?
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.