
Apache Kafka is an open-source distributed system consisting of servers and clients, primarily used for data streaming. Since its initial development by LinkedIn in 2011, Apache Kafka has become the standard for enterprises and other businesses looking to build data streaming pipelines.
Apache Kafka is now used by more than 80% of the Fortune 100 companies. Kafka provides a simple message queue interface on top of its append-only log-structured storage medium. It stores a log of events. Data is distributed to multiple nodes. Kafka is highly scalable and fault-tolerant to node loss.
Kafka has been deployed in sizes ranging from just three nodes to thousands of nodes. It is used extensively in production workloads in companies such as Netflix, Apple, Uber, and Airbnb, in addition to LinkedIn. The creators of Kafka left LinkedIn to form their own company called Confluent to focus full-time on Kafka and its ecosystem. Apache Kafka is now an open-source project maintained by Confluent.
The Apache Kafka Architecture
Perhaps one of the reasons for the success of Kafka is that its architecture is actually relatively simple, while still being highly scalable and fault-tolerant. At its heart, Kafka is simply about moving data from a producer of data to a consumer of data, which is managed via a Kafka topic.
We won’t cover every aspect in detail here, as that would make this guide far too large, but you’ll find links to in-depth looks at each aspect of Kafka’s architecture.
Producers are external data sources outside of Kafka, typically applications that will integrate an Apache Kafka library in order to send data via Kafka’s Producer API. Apache Kafka supports all widely used programming languages.
Read in more detail about Producers here
Consumers are the applications that receive data from Kafka, by reading data from one or more Kafka topics. As with Producers, Consumer applications integrate a Kafka client library, with libraries available for almost all widely used programming languages.
Producers and Consumers exist outside of Kafka. Internally, everything in Kafka is organized into a Kafka Cluster. A Kafka Cluster contains Topics, which organize related events or messages. The data in the topics are stored in the key-value form in binary format. Kafka topics can contain any kind of message in any format, and the sequence of all these messages is called a data stream.
Topics themselves are organized into a number of partitions. A single topic may have more than one partition; it is common to see topics with 100 partitions, and you can have hundreds of thousands if you wanted.
The number of partitions of a topic is specified at the time of topic creation. Partitions are numbered starting from 0 to N-1, where N is the number of partitions. Each partition may live on different servers, also known as Kafka brokers.
Data in Apache Kafka is written and read in order, with new records appended to the end of a partition by producers. Consumers read in order from each partition, though if a consumer is reading from multiple partitions then message order cannot be guaranteed. The position of a record within a partition is known as the offset; consumers always read from lower offsets to higher offsets, and cannot read data backwards.
With these core concepts, we can illustrate a basic example of how the Kafka architecture functions:

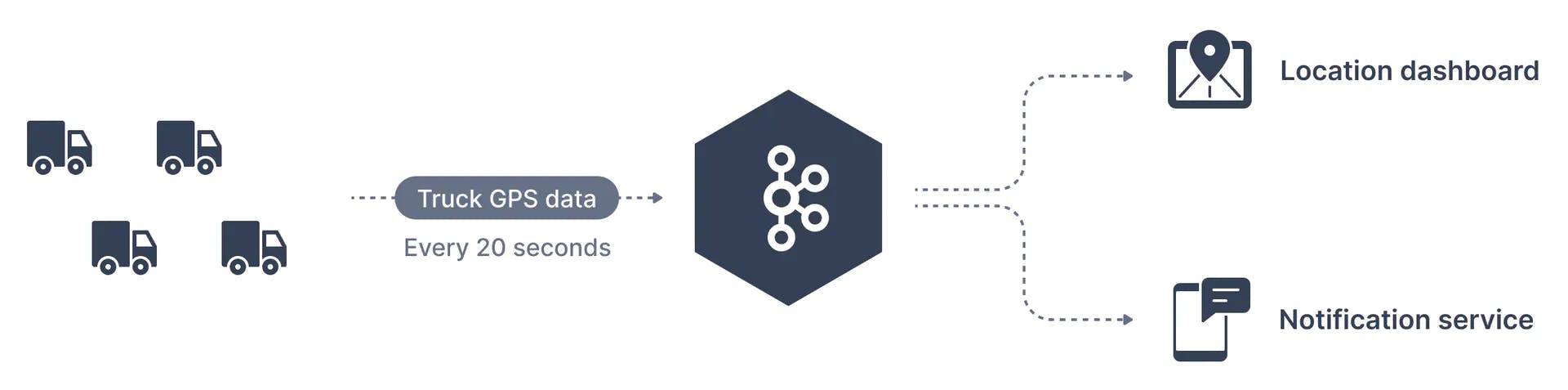
A traffic company wants to track its fleet of trucks. Each truck is fitted with a GPS locator that reports its position to Kafka. We can create a topic named - trucks_gps to which the trucks publish their positions. Each truck may send a message to Kafka every 20 seconds, each message will contain the truck ID and the truck position (latitude and longitude). In this case, the trucks (or rather, a GPS application inside of each truck) are the producers). There may be different consumers of the topic. For example, an application that displays truck locations on a dashboard or another application that sends notifications if an event of interest occurs.
A traffic company wants to track its fleet of trucks. Each truck is fitted with a GPS locator that reports its position to Kafka. We can create a topic named - trucks_gps to which the trucks publish their positions. Each truck may send a message to Kafka every 20 seconds, each message will contain the truck ID and the truck position (latitude and longitude). In this case, the trucks (or rather, a GPS application inside of each truck) are the producers). There may be different consumers of the topic. For example, an application that displays truck locations on a dashboard or another application that sends notifications if an event of interest occurs.
Kafka Brokers and Kafka Clusters
Above we mentioned that topics are held in a Kafka cluster, while partitions can live across multiple Kafka brokers. A single Kafka server is called a Kafka Broker. That Kafka broker is a program that runs on the Java Virtual Machine (Java version 11+) and usually a server that is meant to be a Kafka broker will solely run the necessary program and nothing else. An ensemble of Kafka brokers working together is called a Kafka Cluster.
Kafka brokers store data in a directory on the server disk they run on. Each topic-partition receives its own sub-directory with the associated name of the topic. To achieve high throughput and scalability on topics, Kafka topics are partitioned. If there are multiple Kafka brokers in a cluster, then partitions for a given topic will be distributed among the brokers evenly, to achieve load balancing and scalability.
Clusters can contain any number of Kafka brokers, from just one for simple tasks to thousands for major enterprise level data management.
Read more about brokers and clusters
Apache Kafka with Zookeeper
The management of a Kafka cluster is currently handled by Zookeeper (but it is worth noting that Zookeeper will be deprecated in future versions of Kafka and the management done internally).
Zookeeper is used for metadata management in the Kafka world. For example:
Zookeeper keeps track of which brokers are part of the Kafka cluster
Zookeeper is used by Kafka brokers to determine which broker is the leader of a given partition and topic and perform leader elections
Zookeeper stores configurations for topics and permissions
Zookeeper sends notifications to Kafka in case of changes (e.g. new topic, broker dies, broker comes up, delete topics, etc.…)
A Kafka cluster may have multiple Zookeeper servers, though it will require at least 3. One server will be the leader, handling all writes, while the others are followers and handle reads. Multiple Kafka brokers can be assigned to a single Zookeeper server.
Topic Replication
In Kafka, replication means that data is written down not just to one broker, but many. Every topic has a replication factor which determines how many times a partition is copied to other brokers. The replication factor is set at the topic level when they are created; a replication factor of 3 means that each partition in that topic will have a total of 3 copies, 1 on the original broker and 2 other copies on separate brokers on the cluster. This feature makes Kafka highly resilient since data will be preserved even in the face of broker failures.
Summing up the Kafka Architecture
To recap: producers are applications that write data to Kafka topics. Topics are made up of multiple partitions that can be spread across servers in a Kafka cluster. Consumers read data from partitions in order, tracking their position using the offset.
A single Kafka server is called a Kafka broker, and a Kafka cluster consists of a number of Kafka brokers. A broker can have multiple Kafka topics which receive the data, with each topic also having multiple partitions. Brokers are currently managed by Zookeeper. The diagram below illustrates the overall Kafka architecture:
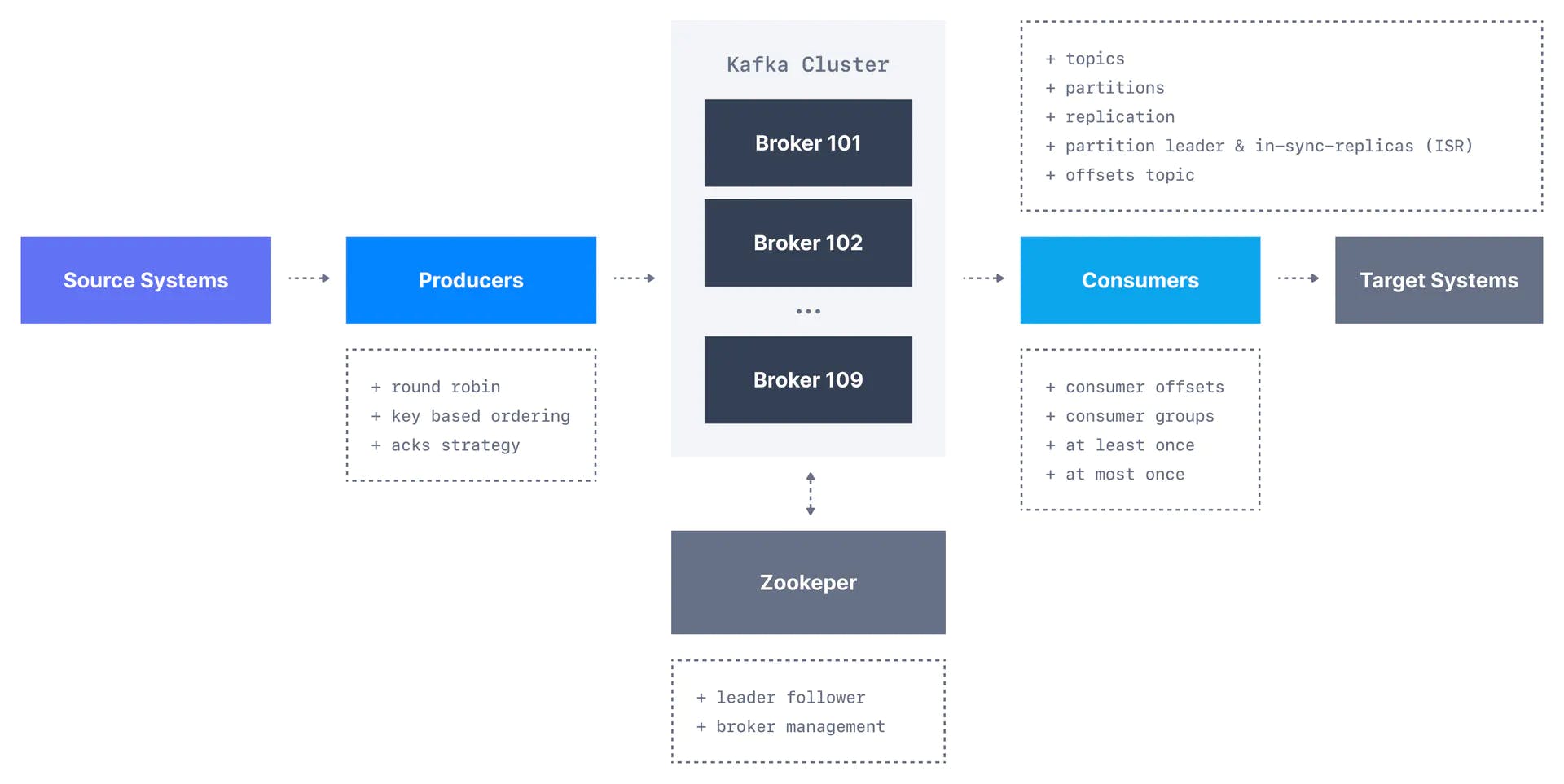
Take note from the above diagram that there are some relevant aspects that we have not mentioned in this article, such as consumer groups, but interested readers can check out our Kafka fundamentals series to learn more.
Apache Kafka APIs
5 core APIs are available for Apache Kafka:
1. Producer API
The Producer API, as you might expect, enables external ‘Producer’ Applications to publish data to Kafka topics within a Kafka cluster.
2. Consumer API
On the opposite end, the Consumer API is what enables external consumers to read data from Kafka topics by subscribing to topics.
3. Streams API
The Streams API allows stream processing applications to make use of streaming data stores in order to provide real-time analytics.
4. Connect API
The Connect API is designed for connectors which integrate popular systems with Kafka. It allows us to re-use existing components to source data into Kafka and sink data out from Kafka into other data stores.
5. Admin API
The Admin API enables users to manage and inspect topics, brokers, acls, and other Kafka objects.
The Advantages of Kafka’s Architecture
Kafka has a relatively simple architecture. There are only a few different parts, and once Zookeeper is deprecated everything you need to deploy a Kafka solution will be contained within Kafka itself. The simplicity of Kafka contributes to some of its advantages, enabling Kafka to be adapted for a variety of use cases and scaled as appropriate.
The key reasons to use Kafka are as follows:
Scalability: Multiple Producers and Consumers can read and write from Kafka at high speeds. Kafka can handle thousands of messages per second, providing access at very low latency - the system has a peak throughput of 605 MB/s and a p99 latency of 5ms. Furthermore, the spread of topic partitions across multiple servers enables consumers to take advantage of multiple disks.
Fault Tolerant: The replication of partitions across Kafka brokers makes the system resistant to individual failures, ensuring that a node going down will not cause data to be lost and will not interrupt the service.
Highly Integrated: Data provided by producers goes through Kafka and does not require any other supporting infrastructure. All widely used languages are supported and there already exist many pre-built connectors for applications, making set-up simple.
Kafka Limitations
While Kafka is both a powerful and flexible stream processing platform, it is not designed for every use case and does have some drawbacks.
Proxying millions of clients for mobile apps or IoT: the Kafka protocol is not made for that, but some proxies exist to bridge the gap.
Lack of Queues: Kafka is made of topics, not queues, unlike some alternatives, which means applications requiring message queues are not suitable.
Partition Numbers: The number of partitions in a topic is very static, having to be evaluated at topic creation - in other words, you will need to guess the right number of partitions. If adding a partition afterwards one thing to keep in mind is if messages are produced with keys. When publishing a keyed message, Kafka provides a guarantee that messages with the same key are always routed to the same partition. This guarantee can be important for certain applications since messages within a partition are always delivered in order to the consumer. If the number of partitions changes, such a guarantee may no longer hold.
Database Issues: Apache Kafka is a database, and can be deployed to augment traditional database platforms in many cases. However, it does lack some features. Long term tiered storage is not available by default. It is not a powerful query engine. Kafka is an event streaming log with no analytical capability built in and no complex query model.
Additional Kafka Libraries
Anyone who researches Apache Kafka will come across the likes of Schema Registry, Kafka Connect, Kafka Streams, and ksqlDB. These are technically not part of the internal Kafka architecture, but they are important additions to any Kafka ecosystem and it is worth having a brief understanding of what they can do:
Kafka Streams: Streams is a stream processing framework that enables real-time analytics and data transformation within Kafka.
Kafka Connect: Connect is an integration tool for Kafka, allowing the re-use of existing components to source data into Kafka and sink data out from Kafka into other data stores.
Schema Registry: Officially titled the Confluent Schema Registry, this registers data schemas in Apache Kafka in order to ensure that producers and consumers will be compatible with each other while evolving.
ksqlDB: ksqlDB is another stream processing option. As you can likely guess from the name, it enables SQL operations to be performed on Kafka topics.
How Conduktor Works with Apache Kafka
Conduktor is another addition to Apache Kafka, transforming the awkward CLI used by Apache Kafka into an intuitive and easy graphical user interface.
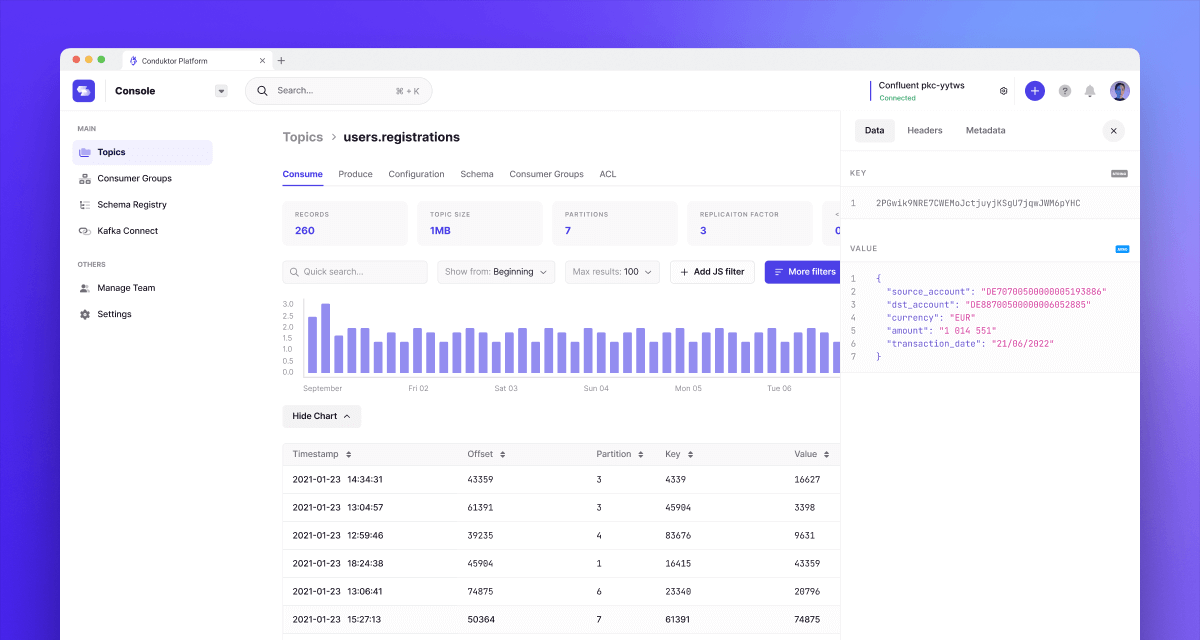
Conduktor is a complete tool for managing Apache Kafka, integrating with all of the key Kafka technologies, end-to-end. Kafka Connect support enables you to source and sink data with just a few clicks in Conduktor. The tool works with all of the major managed Kafka services, like Confluent Cloud, Amazon MSK, Aiven and more. Clusters can be started in seconds through the UI, with everything you need to take control of the ecosystem kept in one place.
Homepoint, a US-based mortgage lender and wholesaler, deployed Kafka along with a Change Data Capture (CDC) system to deliver automated redisclosures (changes to loan conditions). Debezium was used to handle their CDC, with Conduktor providing oversight across the entire architecture.
Using Conduktor UI enabled the team at Homepoint to monitor their Kafka ecosystem easily and effectively, offering live feedback and providing filtering options that allowed Homepoint to focus on single loans whenever they needed. Homepoint saw 20% process efficiency increases through the automation, with the company stating that they achieved savings in the hundreds of thousands thanks to Conduktor.
If you’re looking to get started with Kafka, or simply want to simplify and enhance your Kafka experience, start your free trial of Conduktor today.
Conclusion
Apache Kafka offers a simple yet powerful architecture that can handle a wide variety of use cases, operating at any scale while still providing outstanding performance and durable, reliable data handling. It has become the de facto standard for a number of important projects at major enterprises, being deployed for stream processing, activity tracking, logs aggregation, microservices, and data pipelines. It is not necessarily the best tool for every use, and there are alternative options out there; you may want to take a look at our articles on Kafka vs Pulsar or Kafka vs RabbitMQ vs ActiveMQ to see what other systems might be suitable. But there is definitely a good reason why Kafka is used in 80% of Fortune 100 enterprises.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.