
The movement of data is one of the fundamentals of the modern internet. Technologies like Apache Kafka fit into wider architectures called data pipelines, which describe how data moves from one place to another. In this blog, we’ll look at data pipelines and the various potential pipeline architectures. We’ll also explore the technologies behind data pipelines, their features, and how they are constructed.
What is a Data Pipeline?
A data pipeline is a continuous process that moves data from one system to another, while transforming the data into actionable formats. A common analogy for describing the concept of a data pipeline is that of water flowing through pipes. In this analogy, the source represents where water comes from, while the transformations represent the different filters needed to purify it before reaching its destination.
Data pipelines are used for many different purposes, including:
Data acquisition — getting data from data sources (e.g., databases) into the pipeline.
Data transformation — transforming unstructured data into structured data or vice versa, or transforming one type of structured data into another type of structured data (e.g., from JSON to XML).
Data cleaning — removing duplicates and other noisy information from the dataset.
Data enrichment — adding additional information to the dataset (e.g., adding names and addresses to address records).
Data aggregation — grouping records together so that you can perform analysis on aggregated groups rather than individual records (e.g., calculating average sales by city).
Data storage — storing incomplete datasets in some way that allows them to be accessed later or shared with others who might be interested in them (e.g., saving results in a database or sending them out over email).
What is Data Pipeline Architecture?
A data pipeline architecture is simply the description of what a data pipeline does and how it works. This can be in the form of a logical architecture, which describes the processes and concepts applied to a pipeline. For example, data is moved from a source to a database, processing occurs on the database, logs are captured using Change Data Capture (CDC), and data is delivered to a Business Intelligence (BI) tool. The alternative is a systems architecture which is a literal representation of the tools and platforms used in a pipeline, for example, the architecture is built with Elasticsearch & Apache Kafka and runs on AWS.
Thus if we were to sketch out the basics of creating a data pipeline, we could have a 4-step process:
A need to move data is identified within an organization
A logical data architecture is devised to solve the problem
A physical data architecture is built upon the logical data architecture, describing the tools needed.
The data pipeline is implemented by the organization.
Of course, things are rarely so simple in the real world. Even if you proceed in such an ordered manner, the decisions you will need to make at each stage will be numerous and challenging, involving many different teams.
An Example Data Pipeline Architecture
Here’s what a data pipeline architecture might look like, showing the Change Data Capture (CDC) system for Homepoint, a US-based mortgage broker:

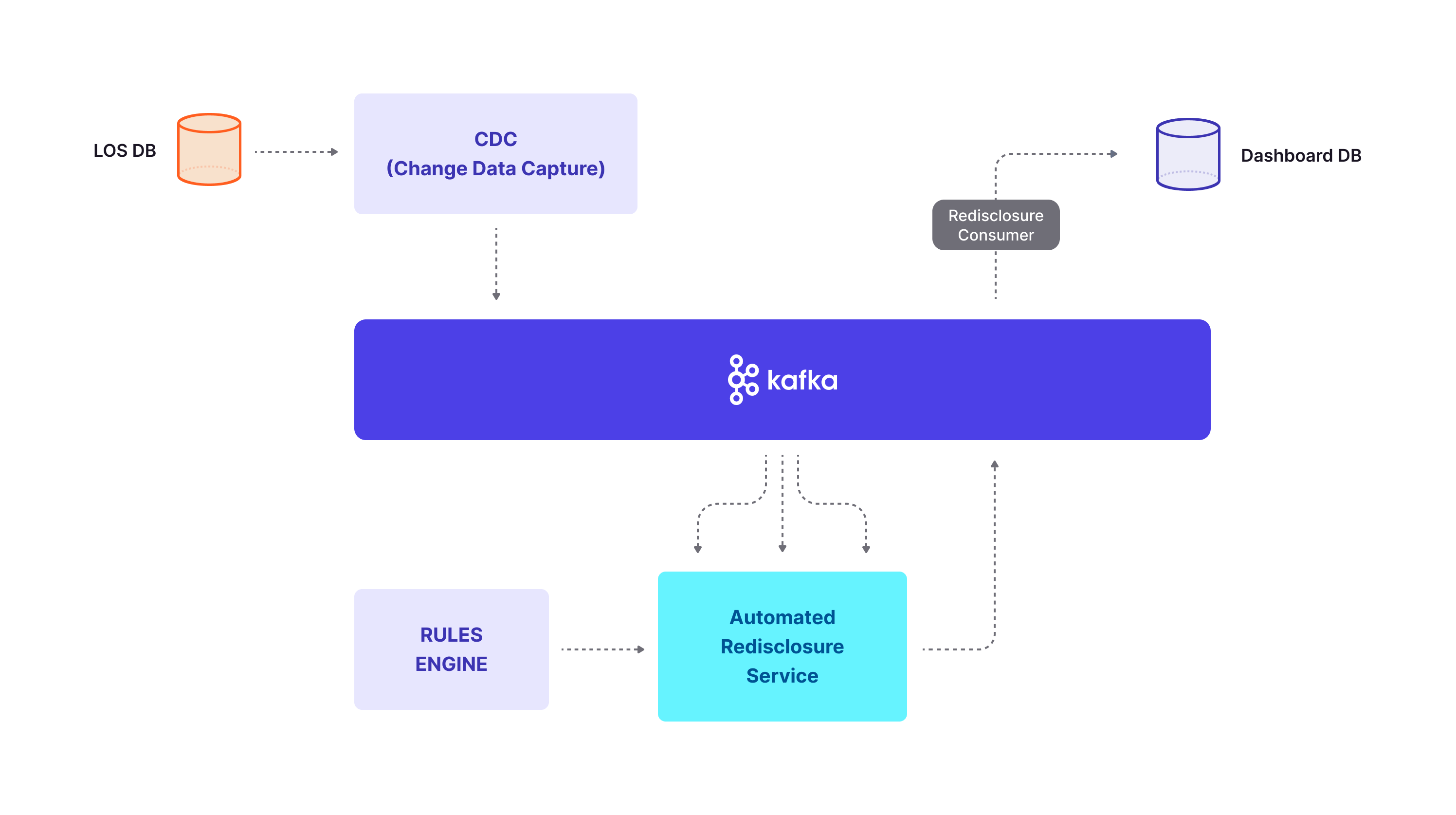
This pipeline illustrates how Homepoint transmits information about mortgage redisclosures (basically changes to a loan) automatically. The start of the pipeline is their Loan origination system database, with the end target being another database that controls dashboards for end users. Apache Kafka handles the movement of data throughout the pipeline.
Read more about Homepoint’s Kafka-based data pipeline here
Components of a Data Pipeline
Let’s return to the 4-step process we mentioned above. After you have identified the problem, you should create a logical data architecture to lay out how you could solve it. What would this look like?
There isn’t a set of guidelines or rules when it comes to the design of a data pipeline, and you’ll find a variety of terms used across different resources. We can’t provide a definitive list of components, but the following are common and will likely form the core of any pipeline.
Data Sources/Data Collection
Every pipeline will depend on there being some data collected somewhere. There are thousands of potential sources of data - any and every computer device, to name a few. Some typical business examples will include website events, pricing data, financial transactions, and user interactions.
Ingestion
The data that you have in your sources needs to be moved somewhere in order to accomplish anything with it - otherwise you just have a database, and not a pipeline. This is where a messaging system like Apache Kafka comes in, connecting to data sources and providing fault-tolerant, highly-scalable message queues on top of its append-only log-structured storage medium.
Typically, the end target for data ingestion will be object storage like Google Cloud Storage or Amazon S3, or databases like PostgreSQL or MySQL.
Transformation
Once your data is collected and ingested into your storage - typically referred to as a “data lake” - it needs to be processed into something usable. While some data profiling may take place in the initial collection of data, you will still be working with raw data. This data will need to be cleaned and altered for it to be ready for further analysis.
Transformation may involve a number of different steps, from compression and aggregation to filtering and combination.
Consumption
Your transformed data is now ready to be consumed, which will involve transferring it to suitable targets. Data warehouses may store cleaned data ready for BI or analytics at a later date, but data can also go directly to BI and analytics tools, and potentially directly to applications that require real-time data.
Data Pipeline Architecture Patterns
Moving beyond the core building blocks of a data pipeline architecture, there are a handful of common patterns that are used frequently.
ETL Data Pipelines
One of the most common forms of a data pipeline is an ETL (extract-transform-load) pipeline, which is used for batch data workloads, like data replication across a pipeline. An ETL pipeline could synchronize source databases with downstream data systems such as caches, search indexes, etc. These pipelines are scheduled to run at weekly, daily, or hourly intervals, typically performing batch workloads.
In an ETL pipeline, data is ‘extracted’ from a data source, ‘transformed’ into an appropriate form, and ‘loaded’ into the target destination.
ELT Data Pipelines
There is an alternative to ETL, known as ELT. ELT stands for Extract-Load-Transform. Essentially, the difference between ETL and ELT is just order; with ELT pipelines, data is loaded into a target system to be transformed later, instead of being transformed prior to loading. So, what’s the point? Why choose one over the other?
ELT is the newer implementation, and its primary advantage is speed - you can implement an ELT pipeline easily, just dumping unstructured data into your storage without having to worry. However, one of the reasons why ELT was not used in favor of ETL was related to storage as well - storage cost. In the past, storage was a lot more expensive, and it is only with the boom in low cost storage, particularly cloud, that ELT has become viable. ETL helped keep costs down as your transformed data was well-defined with no excess.
That is not to say that one approach is definitely better than the other. The ELT approach can give rise to tech debt as unmodelled data is loaded into your storage and query times grow until you eventually are forced to remodel it properly. Taking the time to define your needs ahead of time helps to prevent this kind of issue.
Data Warehouse Pipelines with ETL
The traditional method of building a data pipeline was to build around a single data warehouse, using ETL to move data from sources to destinations. A warehouse, unlike a data lake, takes in only structured data that requires a consistent schema to implement. This is one of the main drawbacks of this implementation as modern data flows are increasingly unstructured and complex.
Data Lake Pipelines with ETL
Centralized data lakes are an important component of modern data architecture. They provide a single, unified place where all of your organization's data can be stored and accessed.
In this pattern, you would use an ETL tool to ingest data into the centralized data lake. For example, if your organization has many different sources of data spread across multiple systems, you could use a tool like Talend or DataStage to pull the data from each source and load it into the central repository. Once there, you could then query, analyze and visualize the data using tools such as Tableau or Alteryx.
This pattern has a number of advantages over other options:
It's relatively easy to set up because there is only one source of truth for your organization's data. This means that anyone who wants to access or transform the data will only have to deal with one system instead of several.
It provides a consistent view of all your organization's relevant information whether they're looking at historical or current records. This allows users to make better decisions because they aren't limited by incomplete information sets or missing pieces of context that might otherwise cloud their judgement.
Data Mesh Pipelines
Data mesh pipelines are similar to centralized data lake pipelines but use multiple data stores instead of just one. Each component of the pipeline may be hosted on its own server, with each component connected to all others by a network of pipes (hence the name “data mesh”). The end result is that each component has access to all of your enterprise’s data sources, including cloud services like Amazon S3 and Salesforce PaaS.
The advantage of this architecture over centralized pipelines is that you can scale up by adding more microservices instead of increasing parallelism.
Batch vs Streaming vs Lambda Architecture
ETL pipelines are a form of batch data pipelines, in which data processes are scheduled to occur at intervals. However, often you will need real-time pipelines that can enable quicker action than batching. For example, above we described a common ETL use case, in which changes to data are replicated across all the systems in a pipeline. Change Data Capture is a real time solution for data replication, which enables downstream consumers to act upon changes quickly.
Real time data pipelines are known as streaming data pipelines. Stream processing technologies like Apache Flink, Apache Storm, and Apache Samza are often deployed in streaming pipelines in order to handle real-time data transformation. Apache Kafka is sometimes referred to as a stream processing technology, but this is incorrect. You can use the Kafka Streams library for stream processing with Kafka, but Kafka itself was not designed for it.
Lambda Architecture is essentially a combination of batch and stream processing, providing a hybrid approach. This is often deployed for big data use cases where you will want to perform batch processing of large, indexed data sets but still have access to real time views of recent, unindexed data.
Data pipeline technologies and techniques
In every stage of a data pipeline, there are corresponding technologies that handle the processes required for the pipeline to function. Planning a logical data pipeline architecture still leaves you with nothing to work with. You will need to create a physical data pipeline architecture that eventually leads to the implementation of your pipeline.
We have already mentioned a number of potential technologies above, such as Apache Kafka, Apache Flink, or MySQL, but we have barely covered a fraction of the different technologies that are in use all around the world. A full accounting of every different technology would be many times longer than this entire article. And we have only briefly discussed the techniques that might be used in a data pipeline, like ETL and CDC.
When it comes to choosing what technologies and techniques you will use in a pipeline, you don’t necessarily need to know every single option out there. Rather, what is important to understand is how you will allocate the resources you have available. In every case, there are options to do-it-yourself, to turn to open source solutions, or to pay for SaaS providers. Naturally, each option has different costs associated. You are going to be trading off employee time against company money depending on how much work you take on yourself vs how much you pay other companies to do it for you.
Each technology you might deploy will also have a web of connected applications, libraries, and tools that you might need. In every case, you will also need to decide how much investment your individual data pipeline technologies require.
An Implementation Example
Let us use Kafka as an example. Kafka is very widely used as an event-driven messaging system in many modern data pipelines. It is not the only solution to this use case - you could use alternatives like RabbitMQ, ActiveMQ, or Apache Pulsar. However, if we assume you are using Kafka, the first decision you are likely to face is whether you will provision your own Kafka clusters using open source Kafka, or turn to a managed Kafka provider like Confluent, Amazon MSK, or Aiven.
At the same time, you will need to decide on the scope of your Kafka implementation. As we mentioned above, Kafka can take on stream processing tasks by making use of Kafka Streams. Another library, kSQL DB, allows you to perform SQL-like operations on data in Apache Kafka. If you wanted, you could use Kafka for transformations in your data pipeline and some companies even deploy it as their single source of truth, using it practically as a database. There is nothing wrong with this approach, but there will be a sacrifice from not using specialized technologies for these use cases.
Once you’ve decided on these aspects of your Kafka deployment, you will then need to think about tooling. You can do everything in Kafka through the command line, but it is very clunky and practically no organizations rely on it long term. Most instead rely on Kafka user interface tools. You’ll also need to think about your development environment. How will you monitor your Kafka? How are you going to test your Kafka pipeline? Will you need encryption on the data going through it? Who’s going to have visibility, and what will their roles be?
Fortunately, there is an all-in-one solution for all of these issues - Conduktor Platform. Conduktor Platform provides an intuitive and powerful user interface for handling all of the day-to-day operations that Apache Kafka requires. But it also goes far beyond that, providing a visual testing interface that can handle all Kafka testing needs end-to-end. Monitoring and alerting are built-in and integrate seamlessly with other monitoring solutions. End-to-end encryption can be delivered with a single API call. And those are just a handful of the capabilities available with the Platform.
You can start using the Platform for free with no time limit - just head to our Get Started page. If you’re considering using Kafka in your data pipeline, why not see how much simpler we can make it for you?
Conclusion
Data pipelines are the backbone of modern IT. Practically every application, website, and technology is going to involve data pipelines at some point. However, deciding on an architecture and executing it is far from easy. There are a huge number of different approaches, different use cases, and different technologies that can be applicable. This blog has only scratched the surface of everything there is to know. If you do eventually decide on Apache Kafka as one of your pipeline technologies, Conduktor is here to help.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.