
As we see in many organizations today, deriving meaningful insights from raw data is still a challenging task. Having the right data processing technology stack at your disposal will significantly simplify the data ingestion, storage, and processing tasks at scale, enabling you to make timely data-driven business decisions.
There are a variety of big data technologies on the market, including Apache Kafka, Apache Spark, Flink, Apache Storm, and others. This article will focus on two prominent technologies, Apache Kafka and Apache Spark, their architecture, and how they complement each other.
What is Apache Kafka
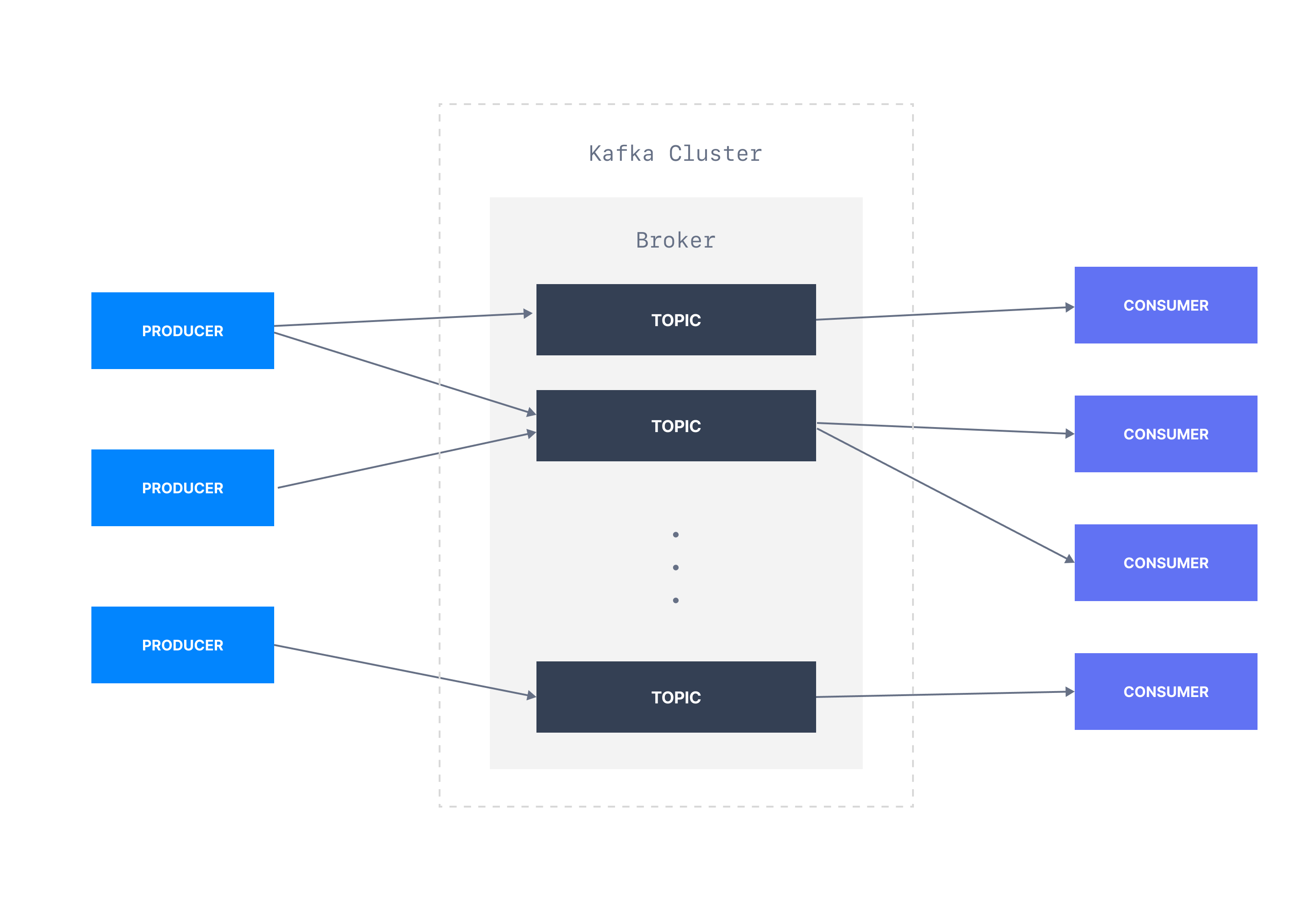
Apache Kafka is a distributed event streaming platform, which can ingest events from different source systems at scale and store them in a fault-tolerant distributed system called a Kafka cluster. A Kafka cluster is a collection of brokers who organize events into topics and store them durably for a configurable amount of time.
Kafka provides APIs for reading and writing data. Applications such as web applications, IoT devices, and Microservices could use the Producer API to write events into a Kafka topic. Consumer applications like stream processors and analytics databases subscribe to a topic and read events using Consumer API. Multiple producers can simultaneously produce events to a topic, which leads to virtually unlimited scalability.

What is Apache Spark
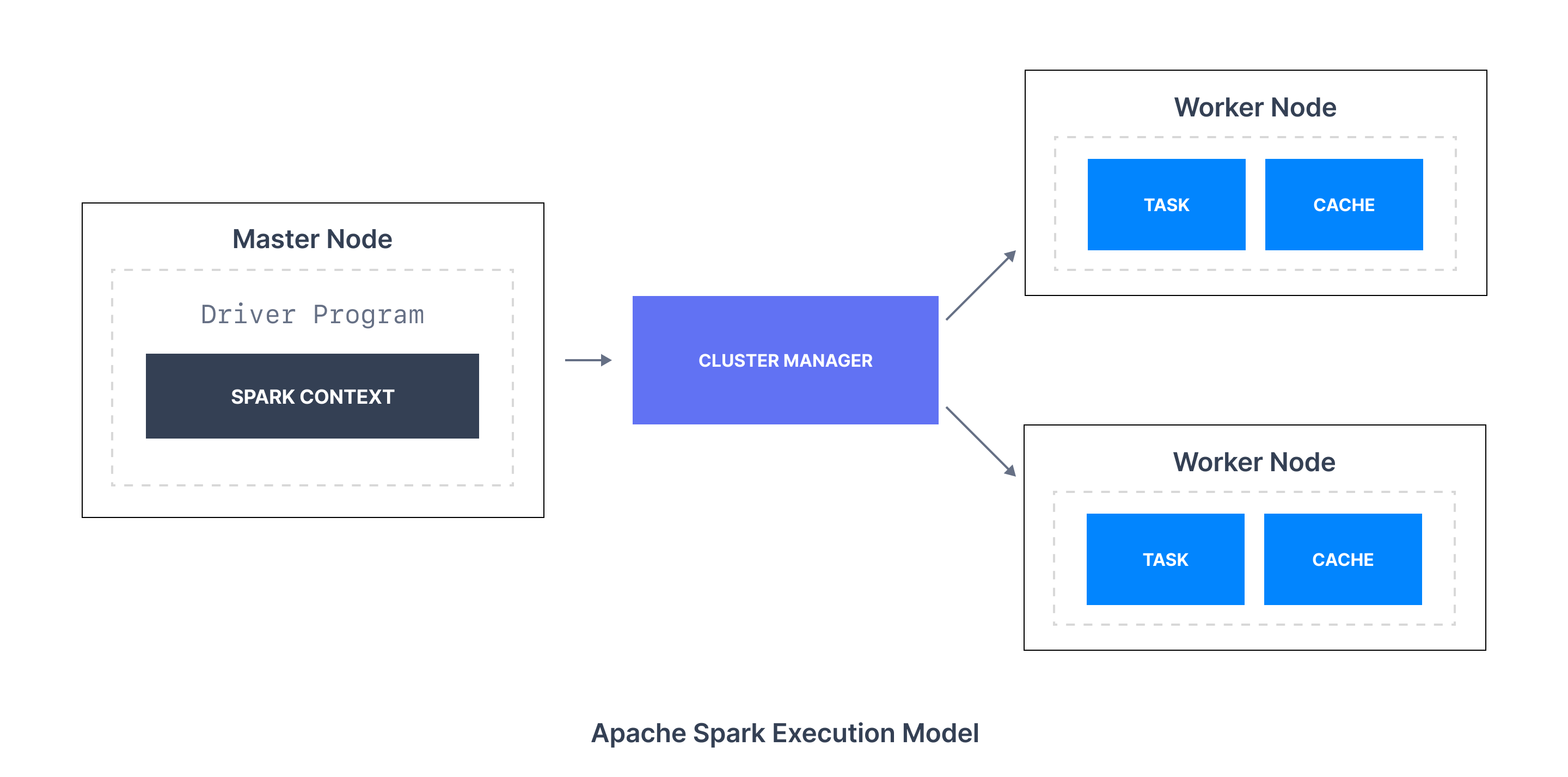
Apache Spark is an open-source, distributed computing framework used for resilient data processing on large-scale data sets. Spark is much faster than its predecessor, Hadoop, which works based on the MapReduce programming model. The secret for being faster is that Spark runs on memory (RAM), making it ideal for analyzing both batch and streaming datasets.
Spark has been designed around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. Developers write Spark applications in any supported programming language and deploy them on a Spark cluster to get a particular data processing job done.
What is Spark Structured Streaming
Before exploring Spark Structured Streaming, it is worth distinguishing between bounded and unbounded data.
Bounded vs. unbounded data
Bounded data is a finite dataset with a well-defined boundary, a start, and an end. Processing bounded data is relatively easy as it is a static dataset. Therefore, we can process them in batches. Bounded data is often called batch data. An example would be the customer orders collected over an hour, day, or month.
Unlike its “bounded” counterpart — batch data, unbounded data has no boundaries defined in terms of time. The data may have been arriving from the past, continuing today, and is expected to arrive in the future. Unbounded data is often called streaming data. An example would be clickstream events coming from a website; the data will continue to arrive as long as users browse.
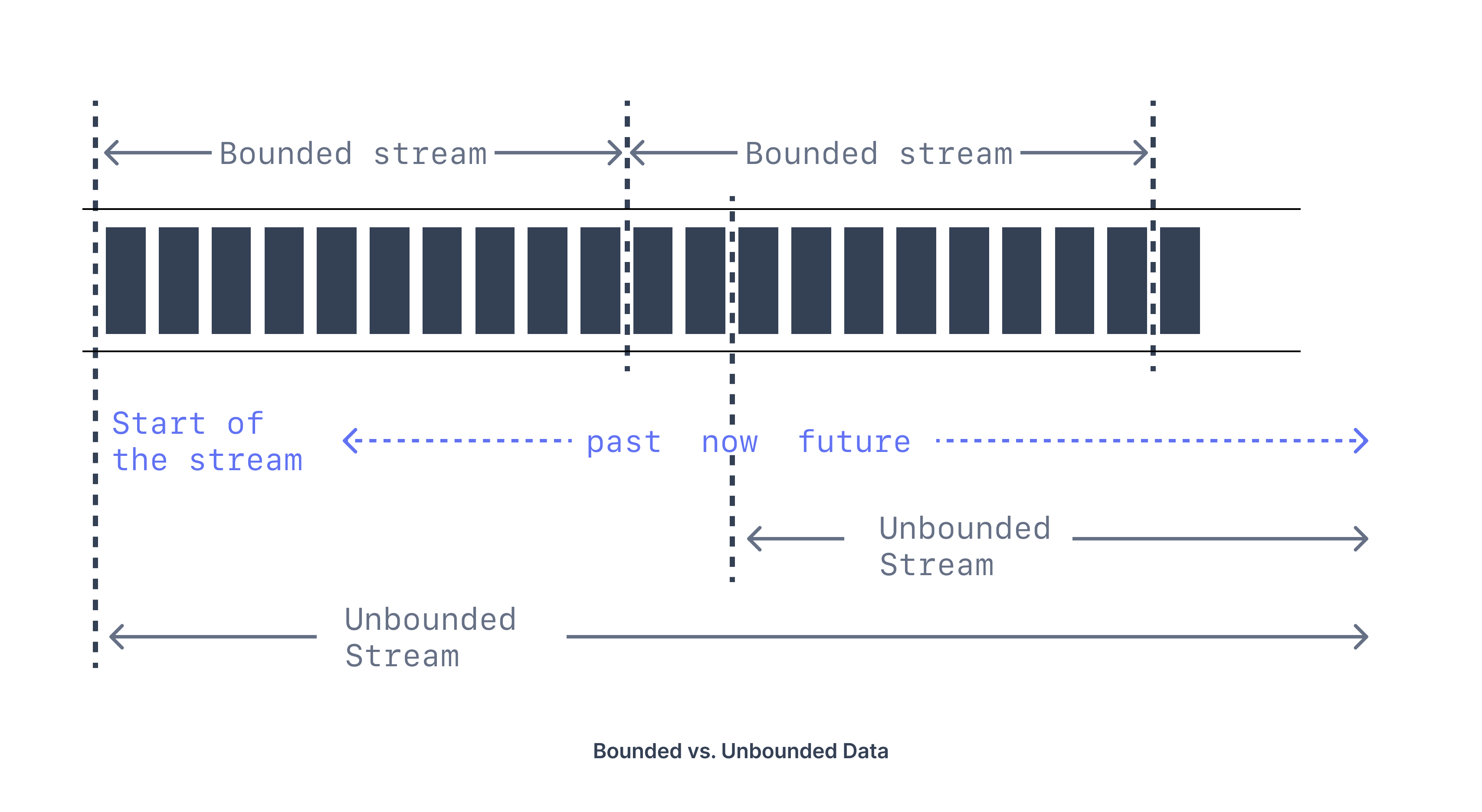
In reality, a lot of data is unbounded because it arrives gradually over time: your users produced data yesterday and today, and they will continue to produce more data tomorrow. Unless you go out of business, this process never ends, so the dataset is never “complete” in any meaningful way. --— Martin Kleppmann, Designing Data-Intensive Applications
Processing bounded and unbounded data requires different architectural paradigms, practices, and technologies--causing organizations to maintain two technology stacks.
Structured streaming: unified APIs for processing batch and streaming data
Structured Streaming is a scalable and fault-tolerant streaming processing framework built on the Spark SQL engine. It lets you express computation on streaming data in the same way you express a batch computation on static data.
Structured Streaming is exposed to the developer through Dataset/DataFrame API in Scala, Java, Python, and R. With the DataFrame API, developers just describe the query they want to run, input, and output locations, and optionally a few more details. The underlying Spark SQL engine then runs its query incrementally, maintaining enough state to recover from failure, and continuously updates the result as streaming data arrives.
There's a significant difference between Structured Streaming and its predecessor, Spark Streaming, a micro-batch processing engine, which processes data streams as a series of small batch jobs. Since Spark 2.3, Structured Streaming supports a new low-latency processing mode called Continuous Processing, which can achieve end-to-end latencies as low as one millisecond with at-least-once guarantees.
How Kafka and Spark work together
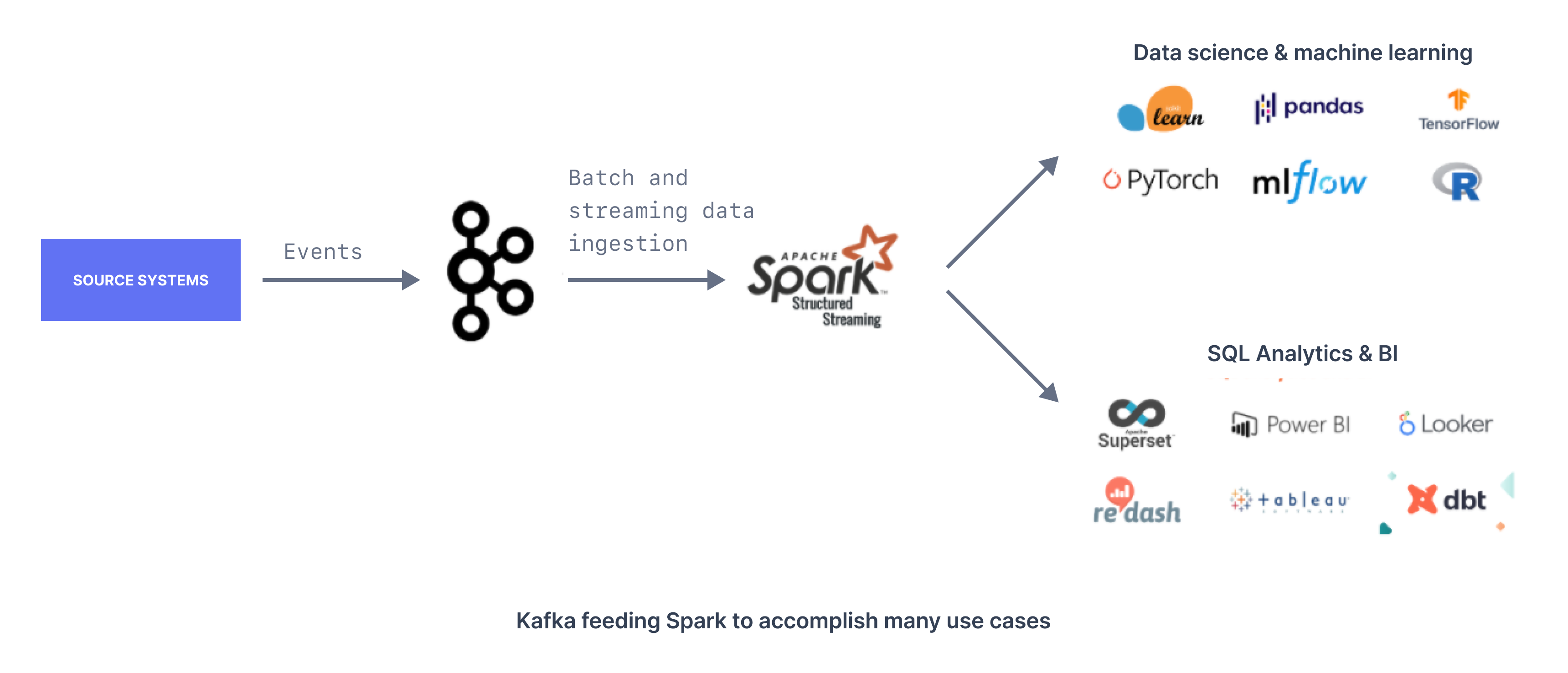
Kafka and Spark are entirely different technologies in their architecture and the use cases served. Despite being open-source and running on the JVM, Kafka and Spark have a particular thing in between--they complement each other very well.
Kafka provides durable storage for streaming data, whereas Spark reads and writes data to Kafka in a scalable and fault-tolerant manner. When combined, these technologies can be utilized to build large-scale data processing use cases.
This integration is made possible via Structured Streaming. For better understanding, let’s take a step back and dive deep into DataFrames, a fundamental data structure you can find in Structured Streaming.
Understanding DataFrames API
Developers access Structured Streaming functionalities through DataFrames. A DataFrame is a distributed collection of data organized into named columns in Spark. It is inspired by the data frames in R and Python (Pandas) and conceptually equivalent to a table in a relational database.
DataFrame can read from and write data to various locations over popular file formats such as JSON files, Parquet files, and Hive tables. These locations include local file systems, distributed file systems (HDFS), cloud storage (S3), and external relational database systems via JDBC. In addition, through Spark SQL’s external data sources API, DataFrames can be extended to support any third-party data formats or sources. Existing third-party extensions already include Avro, CSV, ElasticSearch, and Cassandra.
Constructing a DataFrames requires only a few lines of code. The following is a Python example that reads a JSON file from an S3 bucket. A similar API is available in Scala and Java.
1users = context.load("s3n://path/to/data.json", "json")
2Once constructed, DataFrames can be used for distributed data manipulation.
3# Create a new DataFrame that contains “young users” only young = users.filter(users.age < 21)
4# Alternatively, using Pandas-like syntax young = users[users.age < 21]
5# Increment everybody’s age by 1 young.select(young.name, young.age + 1)
6# Count the number of young users by gender young.groupBy("gender").count()
7# Join young users with another DataFrame called logs young.join(logs, logs.userId == users.userId, "left_outer")
8Apache Kafka support in Structured Streaming
DataFrames can read from and write data to Kafka like other data sources. Structured Streaming integration with Kafka (version 0.10 and higher) provides a unified batch and streaming API to view data published to Kafka as a DataFrame. When processing unbounded data in a streaming fashion, we use the same API to get the same data consistency guarantees as in batch processing.
Kafka integration helps Spark to deliver three data processing styles.
Process streaming data
Process batch data
Replace Kafka Connect
Stream processing on Kafka data
Kafka integration enables building stream processing applications with Structured Streaming. Spark engine constructs a DataFrame from a Kafka topic using the spark.readStream.format(“kafka”) method.
The following is a Scala example reading data from a Kafka topic, "foo".
1val df = spark.readStream.format("kafka")
2 .option("kafka.bootstrap.servers", "localhost:9092")
3 .option("subscribe", "foo")
4 .option("startingOffsets", "earliest")
5 .load()The DataFrame can then be used for further data manipulation as usual. Assuming that the foo topic consists of a list of words, we can calculate the frequency of each word and write it to a file as follows.
1df.select(explode(split($ "value".cast("string"), "\\s+")).as("word"))
2 .groupBy($ "word")
3 .count)
4.writeStream
5 .format("parquet")
6 .option("path", "/example/wordCount")
7 .option("checkpointLocation", "/streamcheckpoint")
8 .start.awaitTermination(30000)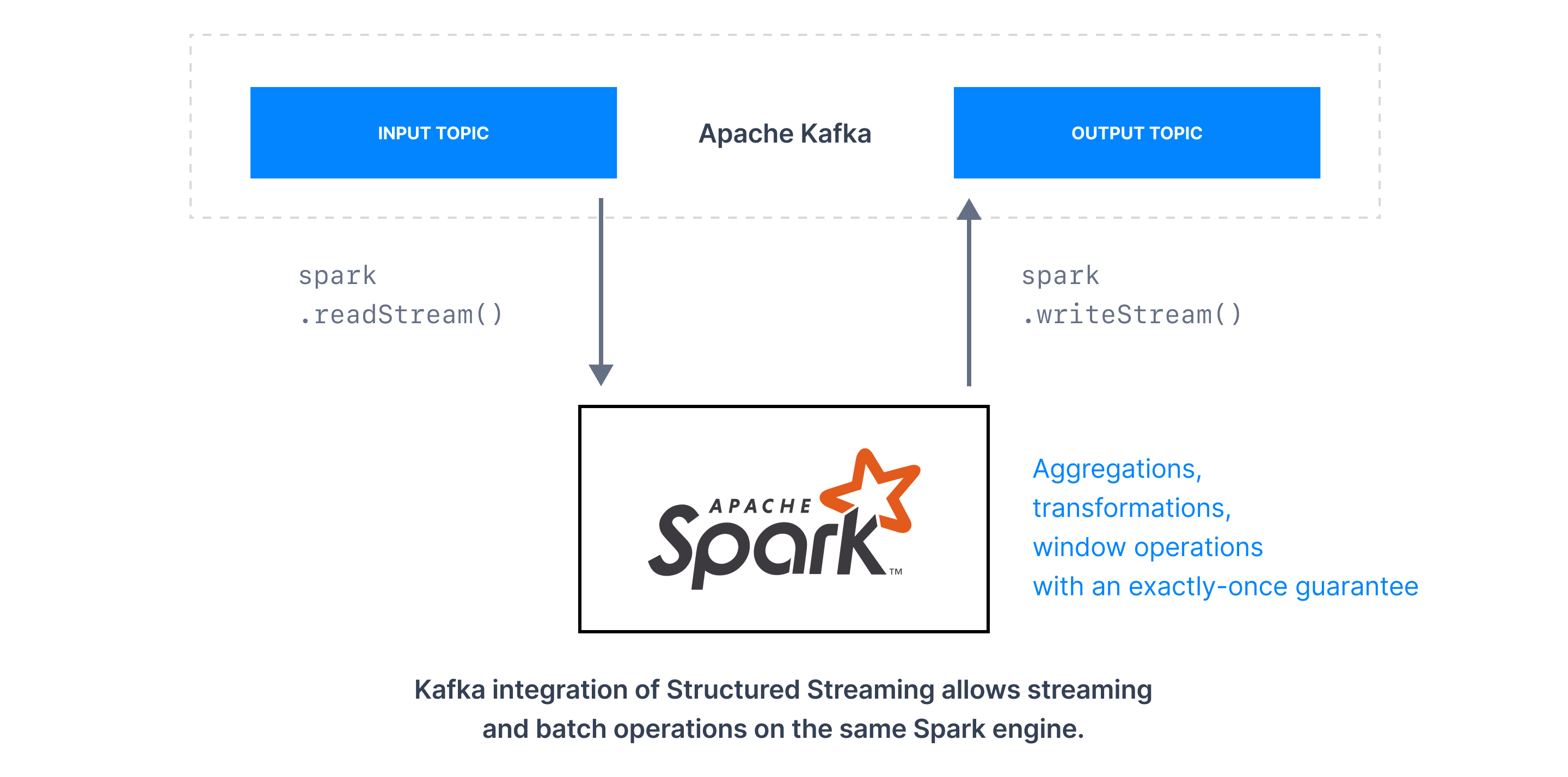
Stream processing applications have two variations in their processing style as follows.
Event-at-a-time processing - One event is processed at a time. For example, an event payload is evaluated for a pattern. If found, it is routed to a different system, otherwise dropped. That is also called stateless event processing.
Event stream processing - A series of aggregate functions are applied to a stream of events aggregated over a time window. For example, consider calculating the average temperature of temperature sensor readings over the last minute. That is called stateful event processing.
Structured Streaming supports building both stateless and stateful applications. One great aspect it offers is that the developer is free from underlying streaming infrastructure. Once the application is deployed, the underlying Spark SQL engine ensures end-to-end exactly-once fault-tolerance guarantees so that developers do not have to reason about low-level aspects of streaming.
In Kafka’s ecosystem, this behavior is similar to what is offered by Kafka Streams and ksqlDB, two popular technologies for building stream processing applications on Kafka data. This means Spark Streaming can replace existing Kafka Streams/ksqlDB applications at some point.
Batch processing on Kafka data
We can also create a DataFrame from a Kafka topic to process data in batch mode. That is useful for scenarios when historical data stored in a compacted Kafka topic is processed for backfilling or training ML models.
Like streaming mode, a DataFrame can be constructed from a Kafka topic, but we use spark.read.format("kafka") instead of readStream.
1val df = spark.readStream.format("kafka")
2 .option("kafka.bootstrap.servers", "localhost:9092")
3 .option("subscribe", "foo")
4 .option("startingOffsets", "earliest")
5 .load()Once constructed, the DataFrame can be used for further data manipulation.
DataFrames as a replacement for Kafka Connect
Kafka Connect allows Kafka to connect the external source and target systems for reading and writing data. A connection is established through a Connector, a reusable library that embeds the logic for connecting to a particular system and performing IO. S3, Elasticsearch, HDFS, and JDBC are some notable connectors in the Kafka ecosystem that enables the integration of different enterprise systems through Kafka.
We can achieve the same with Structured Streaming through DataFrames. As we saw above, DataFrames’ ability to read from and write to different data sources enables applications to easily combine data from disparate sources.
Developers can use DataFrames to read from one data source, process it in the middle using a streaming or batch application, and finally, write the output to a different system. That makes Structured Streaming an excellent choice for building ETL pipelines and enterprise integration use cases.

Use cases for Kafka and Spark
As we discussed, Kafka and Spark integrate very well via Structured Streaming. While Kafka provides scalable and durable storage for streaming data, Spark provides fault-tolerant computation on the data coming from Kafka.
Combining these technologies allows us to build large-scale data processing use cases.
Exploratory data analysis: Data scientists and analysts prefer working with notebooks as they provide ad-hoc querying and interactive data visualization capabilities. Spark integrates well with popular notebooks like Zeppelin and Jupyter as an interpreter to perform fast, on-demand computations on large data sets.
Stream processing applications: With Structured Streaming, applications can process data from Kafka as it arrives. That makes Spark ideal for building real-time data processing use cases such as anomaly detection, real-time personalization, event-driven Microservices, and streaming ETL pipelines.
Batch analytics - Spark can process data stored in Kafka as a batch. Typically, historical events stored in a compacted Kafka topic can populate new databases, backfill existing systems and run analytical workloads.
Training machine learning models: Spark can be combined with MLlib to train machine learning models with data coming from Kafka, either in real-time or batch mode.
Data pipelines - Spark’s ability to consume data from Kafka as a stream or batch allows for building ETL data pipelines.
Conclusion
This article introduces two Apache projects that have been popular in the big data processing space, Apache Kafka and Apache Spark. It gives you an overview of their architecture and the areas they overlap in functionality.
The key takeaway here is that Kafka and Spark are not two technologies that compete. Instead, they complement each other well with Structured Streaming. Having that in mind will always help you make better decisions when planning your next large-scale data-intensive application.
If you're looking for a way to streamline Apache Kafka management, try Conduktor today.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.