
Gone are the days when organizations used to make decisions based on emotions and experience. With the inception of modern data analytics and machine learning technologies, organizations are transitioning into data-driven, real-time business decision-making.
Technologies for collecting, storing, and processing business events in real-time are getting more critical than ever. Apache Kafka and AWS Kinesis are two event streaming platforms that enable ingesting a large number of events each second and storing them durably until they are analyzed.
This article compares Kafka and Kinesis across five dimensions. Hopefully, it will provide you with a useful reference for picking between them in the future.
Apache Kafka - An overview
Kafka was originally developed at LinkedIn as a publish-subscribe system. But, it has evolved into a distributed, fault-tolerant, and scalable event streaming platform.
Kafka is designed to operate as a distributed system that could span multiple data centers. A Kafka cluster is a collection of brokers who organize events into topics and store them durably for a configurable amount of time.
Kafka provides a set of APIs for reading and writing data. Applications such as web applications, IoT devices, and Microservices could use the Producer API to write events into a Kafka topic. Consumer applications like stream processors and analytics databases subscribe to a topic and read events using Consumer API. Multiple producers can simultaneously produce events to a topic while many consumers already consume from the same topic. That leads to virtually unlimited scalability.

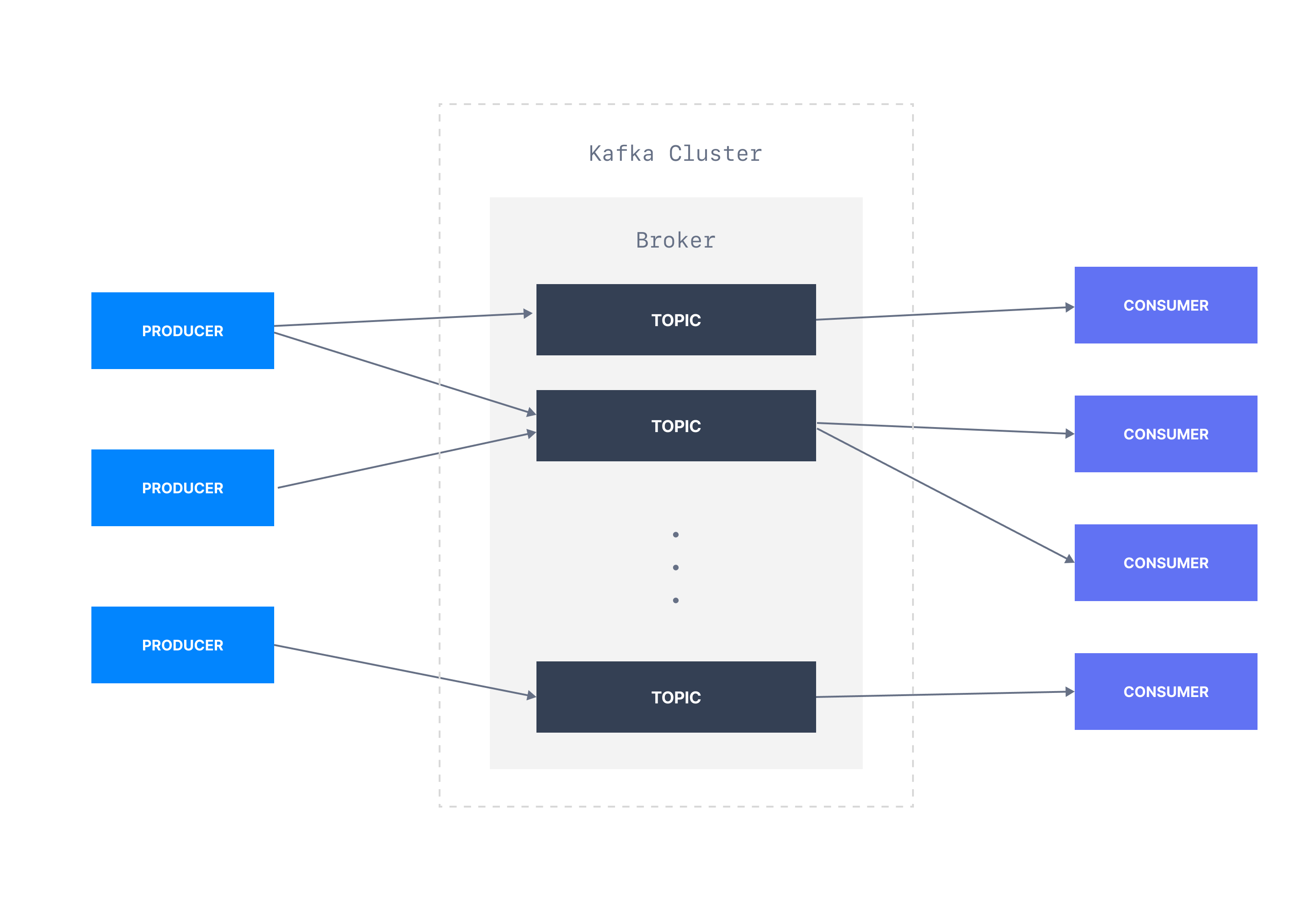
Kafka was donated to the Apache Software Foundation (ASF) to become an open-source project. That means you can download, install, and manage an Apache Kafka cluster free of charge. Also, Kafka is available as a managed service from vendors such as Confluent, AWS MSK, and Aiven.
AWS Kinesis - An overview
Kinesis is an event streaming platform based on the publish-subscribe principle. Kinesis is offered as a managed service by AWS.
Kinesis is the umbrella term used for four different services--Kinesis Data Streams, Kinesis Data Firehose, Kinesis Video Streams, and Kinesis Data Analytics. While each service serves a specific purpose, we will only consider Kinesis Data Streams for the comparison as it provides a foundation for the rest of the services. We will refer to Kinesis Data Streams as Kinesis for the sake of simplicity.
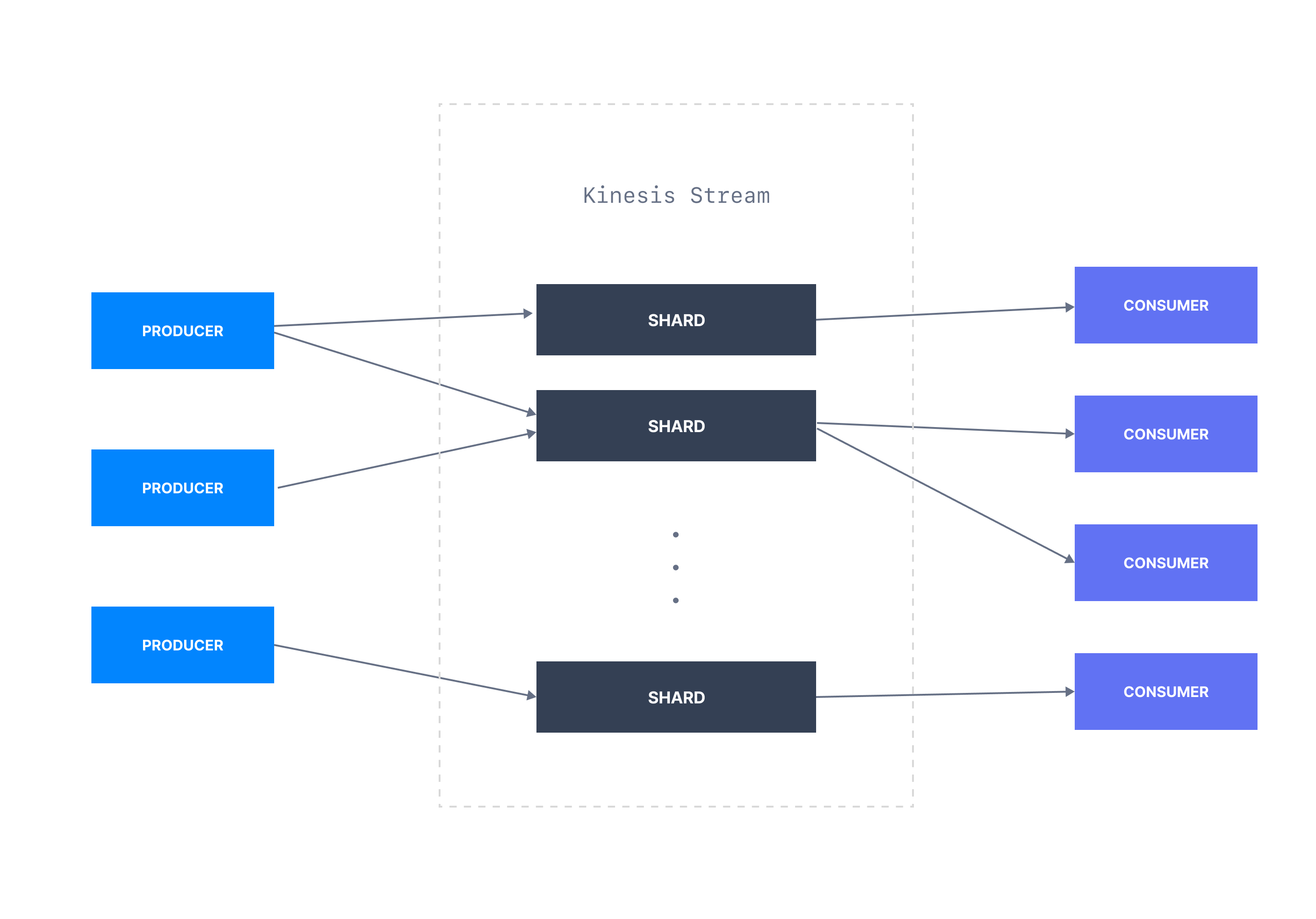
Kinesis organizes its data records into shards. Like Kafka, Kinesis also provides its users with APIs for producing and consuming events into a shard. Those APIs are available in multiple programming languages and tightly integrated with AWS SDKs and the CLI.
Kafka vs. Kinesis - Dimensions for the comparison
Both Kafka and Kinesis are prominent technologies in the event streaming space. A decision to choose either of them should be made rationally. Hence, we came up with the following dimensions to compare and contrast them.
Installation & Administration
Internal Architecture
Data retention
Integration with the ecosystem
Pricing
Kafka vs Kinesis: Installation and administration
Apache Kafka is an open-source product. That gives you more flexibility in installing, scaling, and operating a Kafka cluster in production. You get to decide the exact Kafka version, the number of brokers, and their hardware specifications based on the workload.
But this flexibility often comes with a cost.
Kafka is a distributed system made of multiple servers (brokers). Installing and configuring a Kafka cluster to handle a typical production workload might take weeks. Once provisioned, operating a production Kafka cluster requires regular monitoring. You may have to spend on additional hardware to fine-tune the cluster performance to handle spikes in workloads. These factors may result in a high operational cost in terms of billable engineering hours and hardware.
Conversely, Kinesis hides many operational complexities from its users by being fully managed. Kinesis only exposes its users to the interfaces that matter the most--APIs for reading and writing data and configurations for securing and scaling Kinesis to handle a production workload. Apart from that, AWS takes over the laborious tasks of hardware provisioning, software installation and patching, monitoring, and other management aspects.
Kafka vs Kinesis: Internal architecture - partitions vs. shards
Although Kafka and Kinesis are trying to solve the same problem, they do it differently. Both technologies have their architectural differences.
Kafka has partitions
Kafka organizes its events around topics where all related events are written to the same topic. A topic is further broken down into partitions.
A partition is the smallest unit in a Kafka cluster that stores a subset of events belonging to a topic. Events written to a partition are strictly ordered by their partition key. When Kafka receives an event, the partition key associated with the event is passed into a hash function to determine which partition the event belongs to. Simply put, events with the same partition key will end up in the same partition.
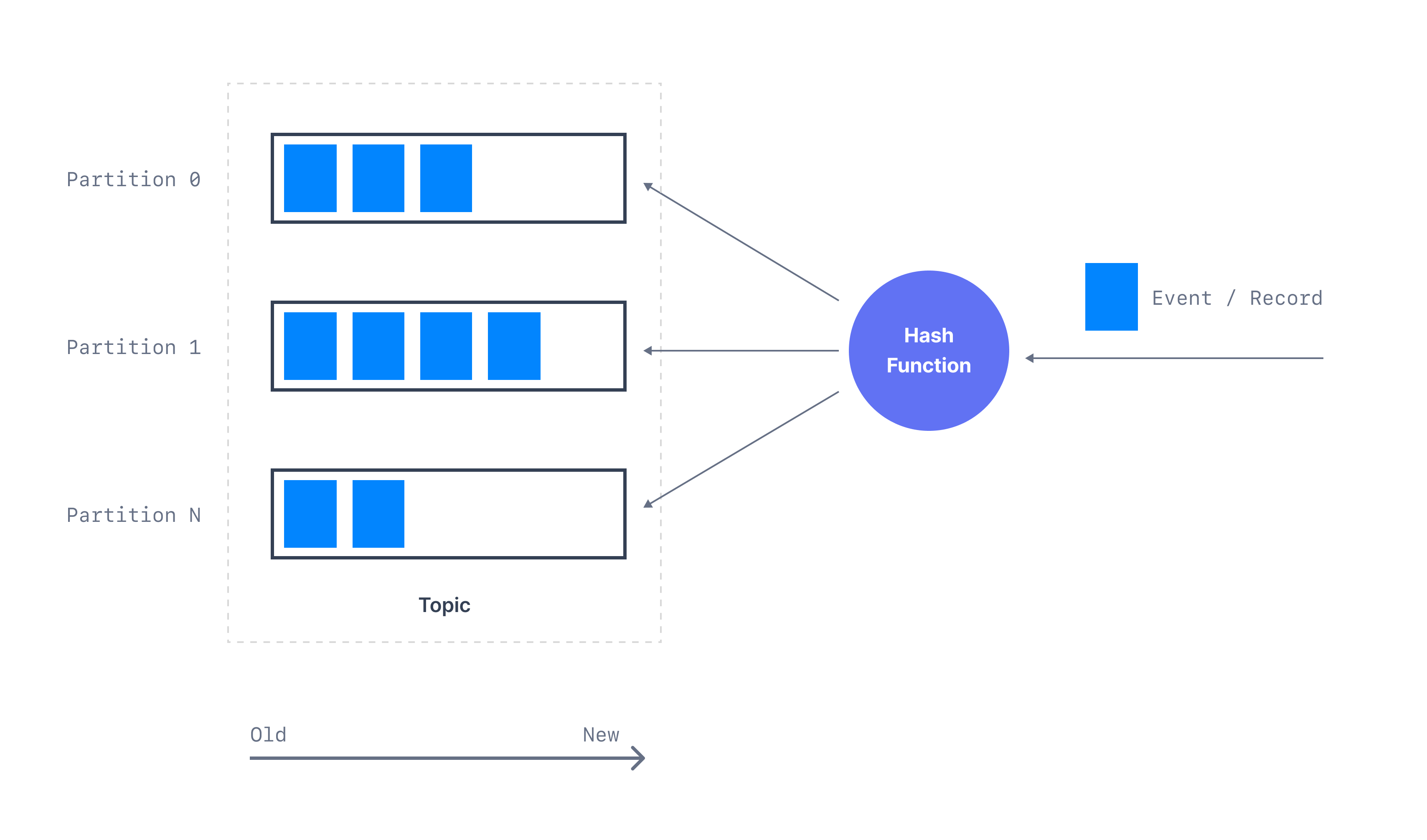
Many producers can write to a partition, which can be consumed by many consumers simultaneously. The more partitions you have, the more consumers you can have in parallel. Kafka gives you complete freedom to define any number of topics and partitions based on the cluster specifications.
Kinesis has shards
Kinesis abstracts away many internal details and surfaces only a few key concepts as a managed service. In Kinesis, you have streams, the Kafka equivalent for a topic. All related events are stored in a stream. A stream is further broken down into shards. A shard holds a subset of data records in a stream. Kinesis also uses a partition key to determine the shard a given event belongs to. Like Kafka, events with the same partition key will always end up in the same shard.
Different hashing strategies for message keys
However, Kafka and Kinesis use different strategies to hash partition keys. Kafka’s hashing algorithm depends on the number of partitions. If you add a new partition to a topic, Kafka will trigger a rebalance to distribute the partitions to the existing consumers, but the existing data will not be rebalanced. As a result, you will lose the key-based ordering of messages.
Conversely, Kinesis hashes message keys on a continuous space regardless of the shard count. Hence, adding or removing shards does not affect the key-based message ordering.
Pull Model: the throughput of a Kinesis shard is bounded
Unlike a Kafka partition, the throughput of a shard has limits. Each shard can only accept 1,000 records or 1 MB per second (see PutRecord documentation). If you write to a single shard faster than this rate, you'll get a ProvisionedThroughputExceededException. Each of the shards in a stream supports a read throughput of 2MB per second, which all stream consumers share. You can scale this limit by adding more shards to the stream, incurring additional costs. Comparatively, the throughput of a Kafka partition has no limits.
Push Model: Kinesis supports Enhanced fan-out
AWS recently announced the Enhanced fan-out feature, where each consumer reading from a shard will get a dedicated throughput of 2MB per second. When the fan-out is enabled, records are pushed immediately to the consumer, making it an ideal choice to build real-time, low-latency consumer applications.
Conversely, Kafka only supports the traditional read model where consumers are supposed to pull data from partitions.
Kafka vs Kinesis: Data retention period
We define the data retention period of a streaming platform as the period certain data records are accessible after they are added to the stream. By default, Kafka retains data records for up to seven days. But that is configurable. Often, users tune their Kafka cluster to store events based on several factors such as record size, event arrival rate, and the business use case.
However, higher retention periods demand more disk space. You can keep on provisioning more local storage for a Kafka cluster, but at some point, it becomes unmanageable. The recommendation is not to use Kafka as eternal storage as it can lead to difficulties in recovering from failures, increased time in maintenance and data migration, etc.
KIP-405 is a proposal to introduce tiered storage to Kafka. That allows keeping the latest data for a short period (e.g., 48 hours) in the local storage and flushing out the older data into cheap secondary storage like S3 or HDFS. Use cases like hydrating a new database, training a new machine learning model, and testing a new version of a consumer can always reach the secondary storage to access the older data.
Stream retention period on Kinesis is usually set to a default of 24 hours after creation. But Kinesis allows users to increase the retention period up to 365 days. Additional costs will incur if they want to retain data for more than 24 hours.
Kafka vs Kinesis: SDKs and ecosystem integration
An event streaming platform is useless without having a well-documented SDK for developers to read and write events into it.
Kafka officially provides two types of SDK for Java developers. First, Kafka offers low-level producer and consumer APIs targeting straightforward event production and consumer use cases. Secondly, Kafka provides the Kafka Streams API to implement more complex stream processing use cases such as event-driven microservices, fraud detection, and real-time analytics.
Apart from Java, Kafka has community-maintained SDKs for other languages.
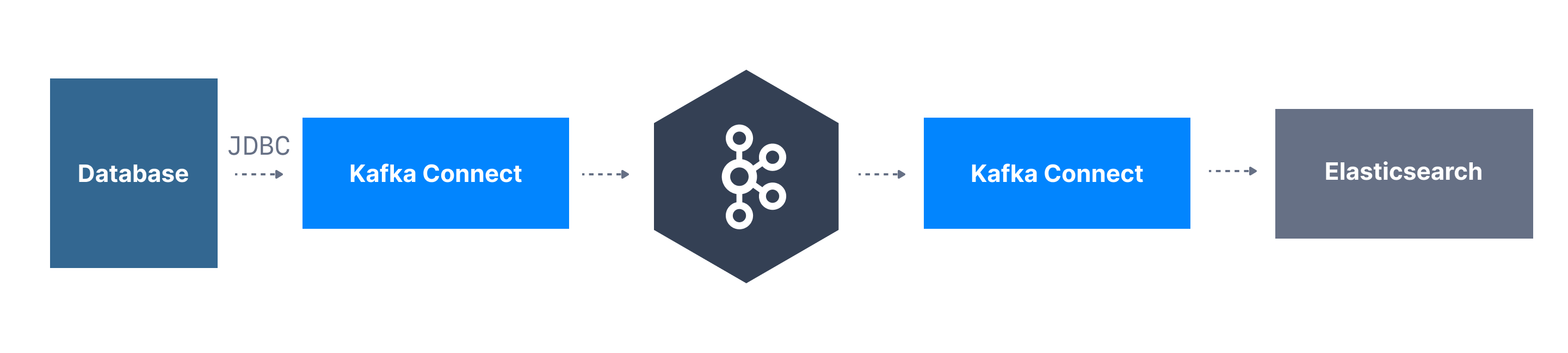
Kafka Connect is a language-neutral tool for scalably and reliably streaming data between Apache Kafka and other systems. Kafka Connect comes with “connectors” to different ecosystem components that enable moving a large data collection into and out of Kafka. For example, events received into a Kafka topic can be sent to Elasticsearch by routing through Kafka Connect with the Elasticsearch connector.
Amazon SDKs for Go, Java, JavaScript, .NET, Node.js, PHP, Python, and Ruby supports Kinesis Data Streams. In addition, the Kinesis Client Library (KCL) provides an easy-to-use programming model for processing data, and the users can get started quickly with Kinesis Data Streams in Java, Node.js, .NET, Python, and Ruby.
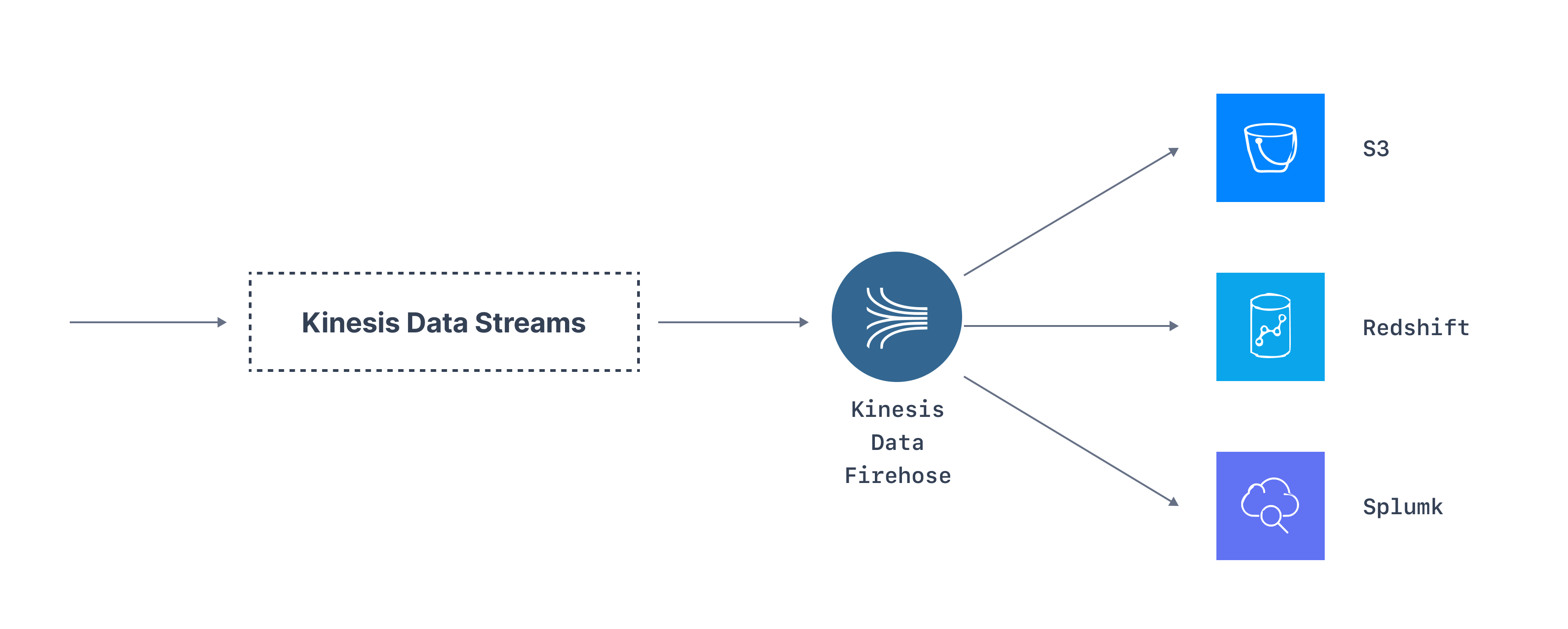
Events written to a Kinesis stream can be taken out to other AWS services via AWS Kinesis Data Firehose; the Kafka Connect equivalent connects Kinesis to other ecosystem products like S3, Redshift, and Splunk. Kinesis also tightly integrates with Kinesis Data Analytics (KDA), allowing developers to build stream processing applications on top of the events flowing from Kinesis.
In fact, KDA is Apache Flink as a managed service. It provides an alternative to Kafka Streams. You can also use KDA against a Kafka cluster to deploy your Flink applications.
Kafka vs Kinesis: Pricing
Kafka is an open-source product. Meaning it incurs zero upfront cost to get started. However, as we discussed earlier, operating a production Kafka cluster incurs costs in terms of hardware and labor. Amazon’s model for Kinesis is pay-as-you-go. It works on the principle that there are no upfront costs for setting up; the amount to be paid depends on the services rendered. The pricing is calculated in terms of shard hours, payload units, or data retention period.
You can find more information on Kinesis pricing from here.
Conclusion
Our discussion so far can be summarised as follows:
Feature | Kafka | Kinesis |
|---|---|---|
Licensing | Free and open-source | Commercial |
Hosting | Primarily on-premises, but managed services like Confluent, AWS MSK, and Aiven also exist. | Only on the AWS cloud. AWS takes care of the management. |
Logical records container | Topic | Stream |
Physical records container | Partition | Shard |
Key hashing strategy | Depends on the number of partitions (breaks key-based ordering if adding partitions) | Independent of shards (doesn’t break key-based ordering if adding shards) |
Throughput per partition/shard | Unlimited. Only governed by cluster’s resources | Both read and write throughput is limited per shard. Scale-out by adding more shards. More throughput for consumers if using enhanced fan-out |
Message consumption strategy | Consumers pull data from partitions | Consumer-driven pull and enhanced fan-out where messages are being pushed to consumers. |
Data retention | One week by default. But configurable. The tiered storage capability is working progress. | 24 hours by default. But can be extended up to 365 days which would incur a cost. |
SDK support | Official Java SDK and community maintained SDKs for other languages. | SDKs are available in many languages and integrate well with AWS CLI. |
Ecosystem integration options | Kafka Connect | Kinesis Data Firehose |
Stream processing engine integration | Kafka Streams, ksqlDB | Kinesis Data Analytics (managed Apache Flink) |
Operational complexity | Takes weeks to set up a production cluster yourself, hours if using managed solutions | Provisions in hours |
The technology space we live in today is full of choices, making it challenging to come up with a clear answer to many technical decisions. The same applies when choosing either Kafka or Kinesis as an event streaming platform. There’s no single correct answer. It always depends.
If you come from a background where the cloud is no option, you have access to engineering talent experienced in distributed systems, DevOps, and JVM languages; Kafka might be a good fit for your organization. On the other hand, if you are starting small or have been established on AWS for a while, Kinesis provides you with a smooth transition to event streaming. It takes away the operational burden and lets you focus only on the business problem while giving you the best value for your investment.
We hope this article helped you pick the right technology based on the engineering culture, budgetary constraints, and how critical the role of event streaming plays within your organization.
And if you choose Apache Kafka for your data event streaming development, make sure to check out Conduktor. Our all-in-one GUI works whether your Kafka is on-prem or you're using a managed service or cloud solution like Amazon MSK, Aiven, Confluent, or Upstash. Ultimately, Conduktor will help to bypass some of the speedbumps, increase productivity, reduce costs and ultimately, accelerate project delivery.
We aim to accelerate Kafka projects delivery by making developers and organizations more efficient with Kafka.